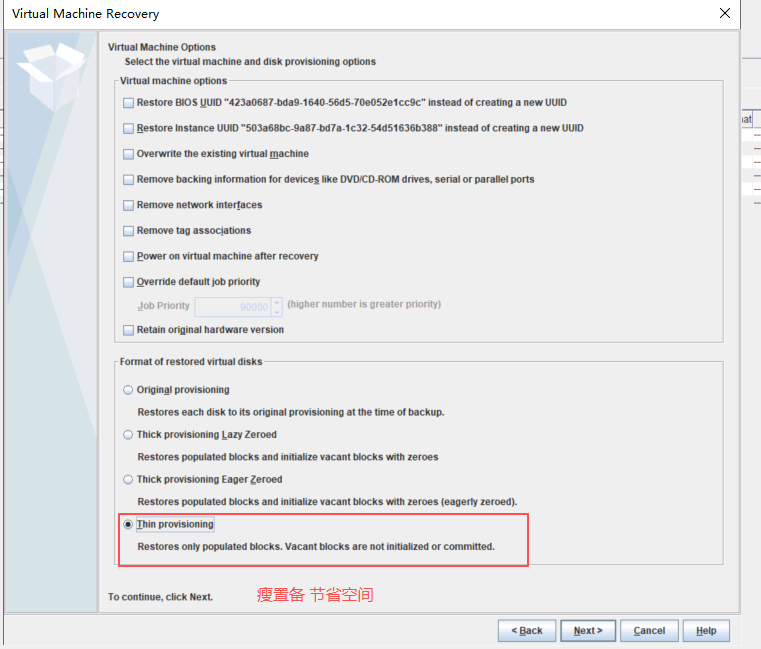
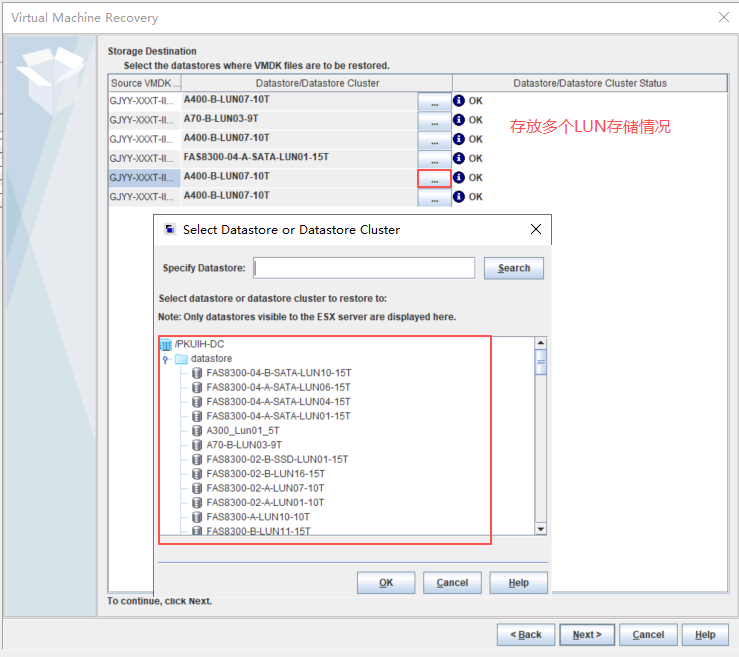
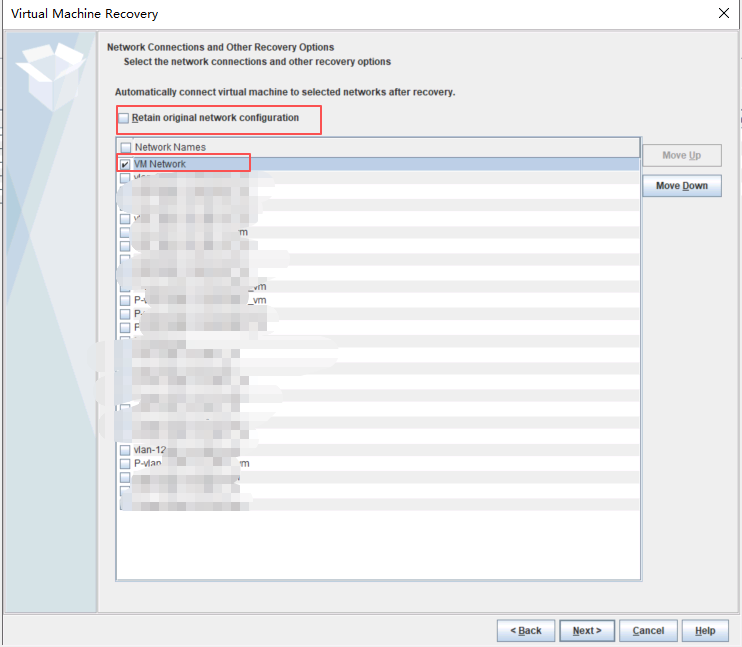
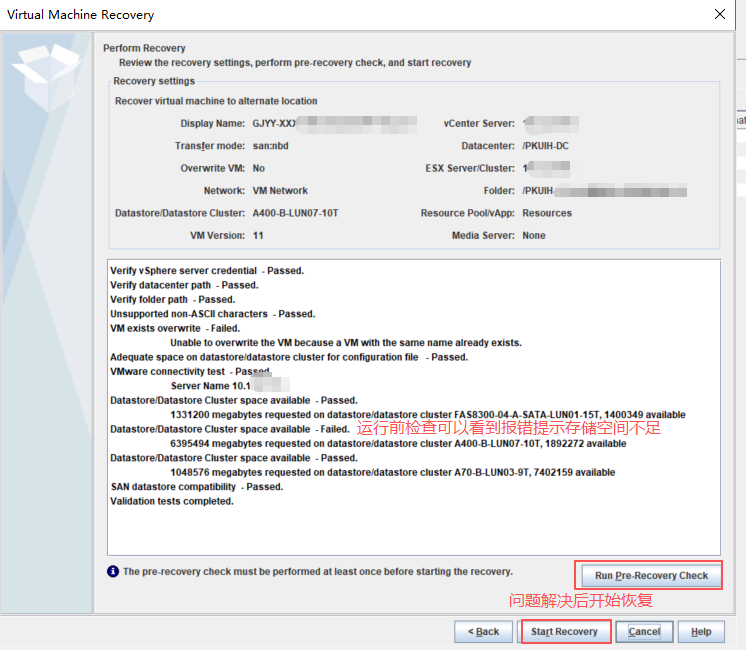
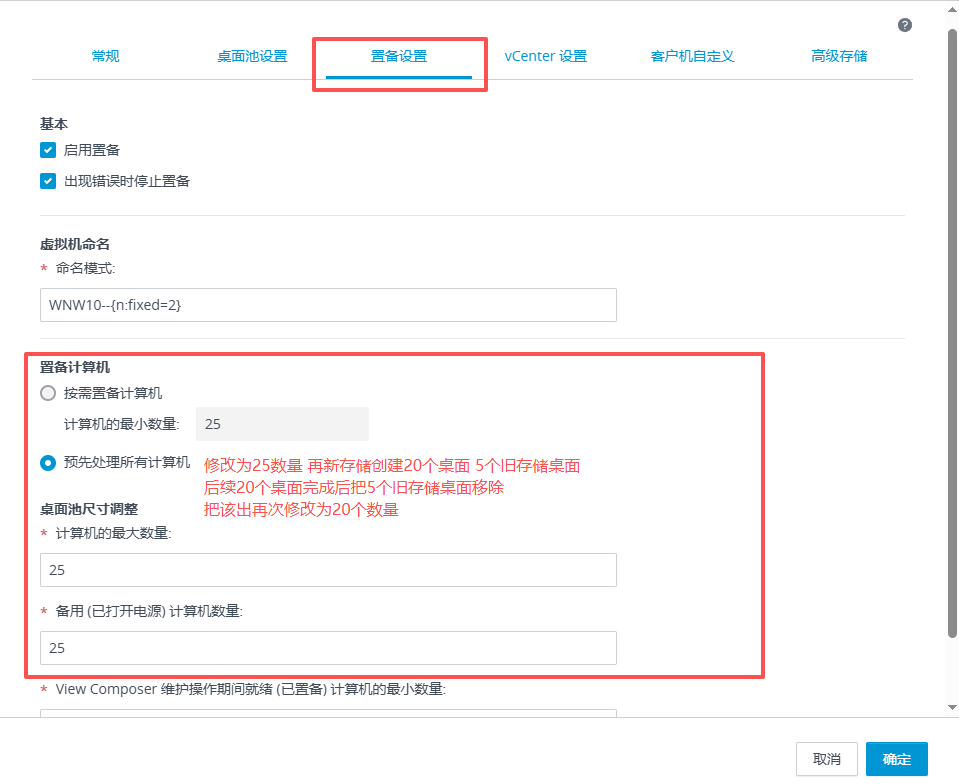
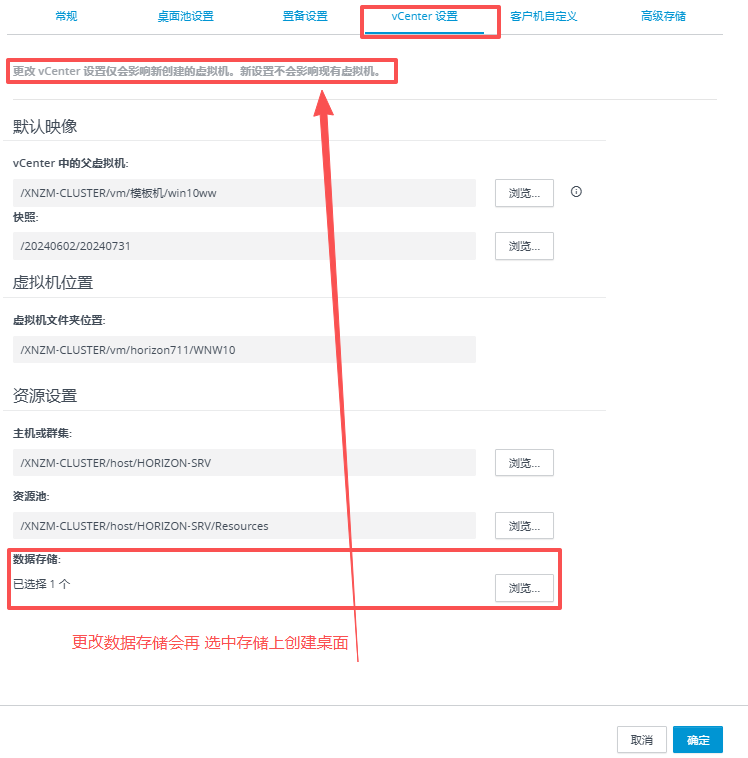
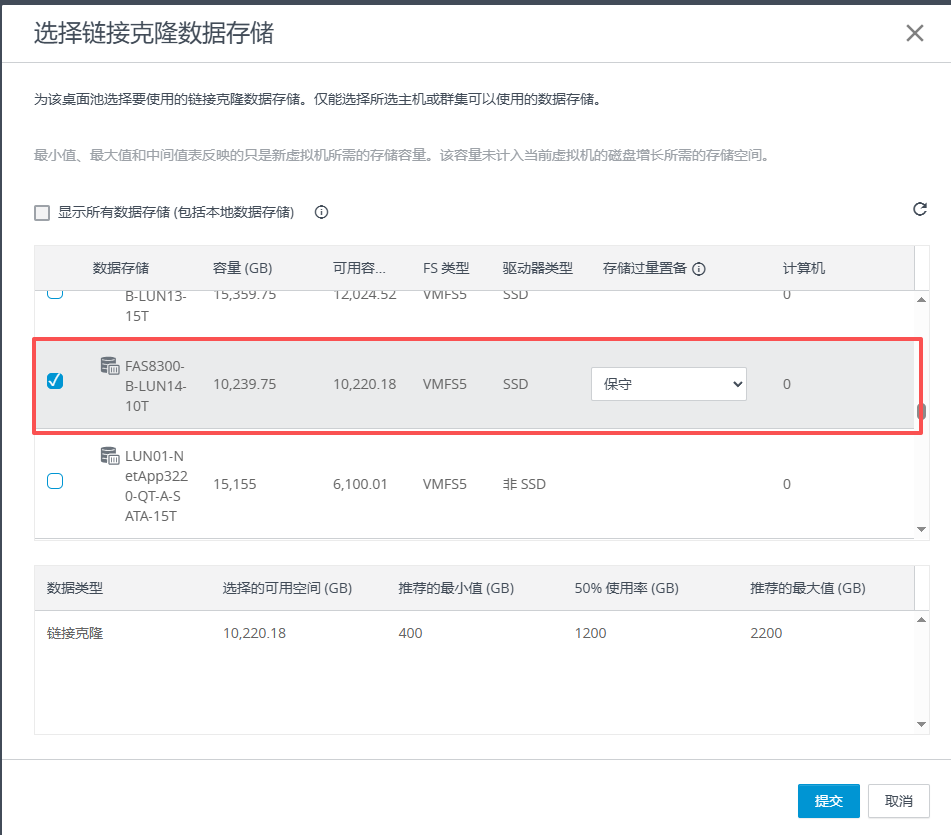
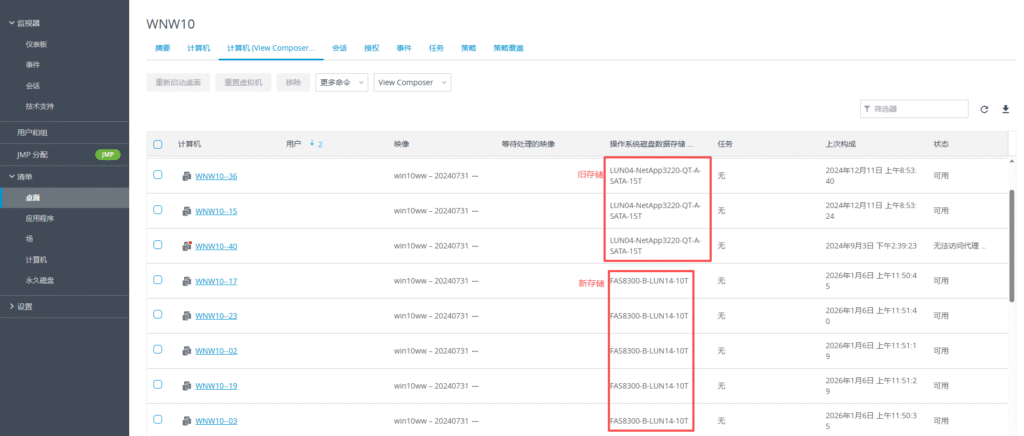
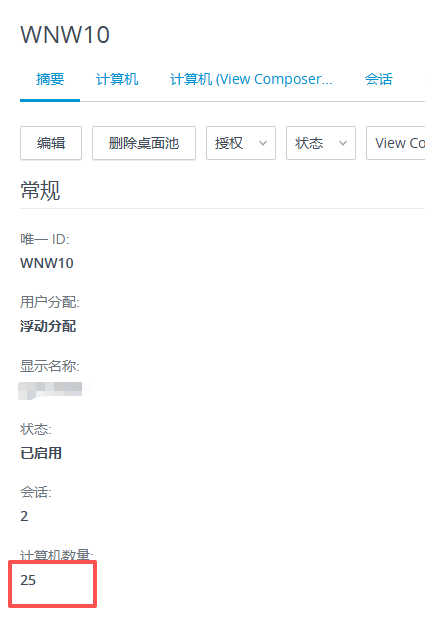
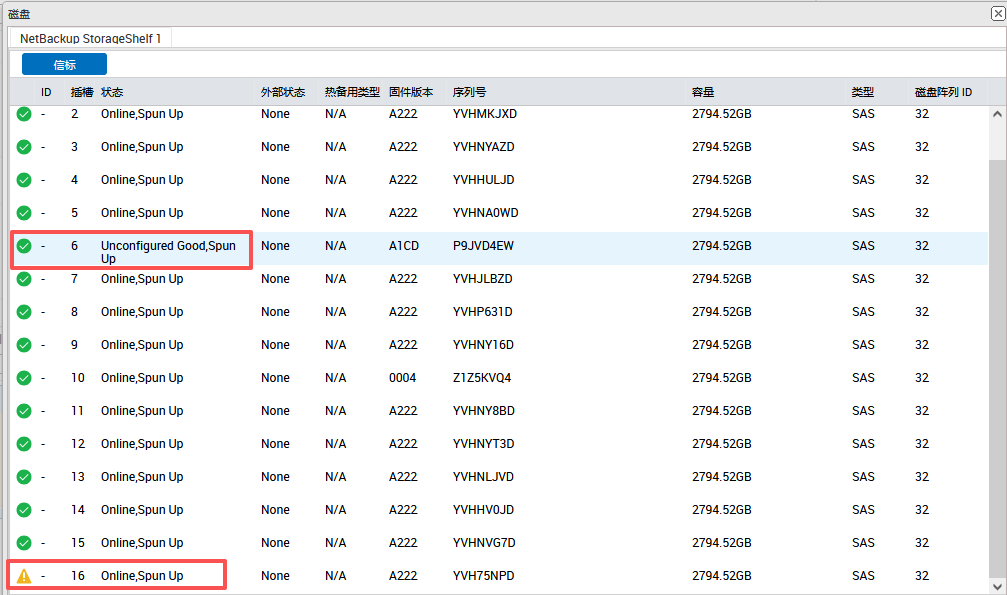
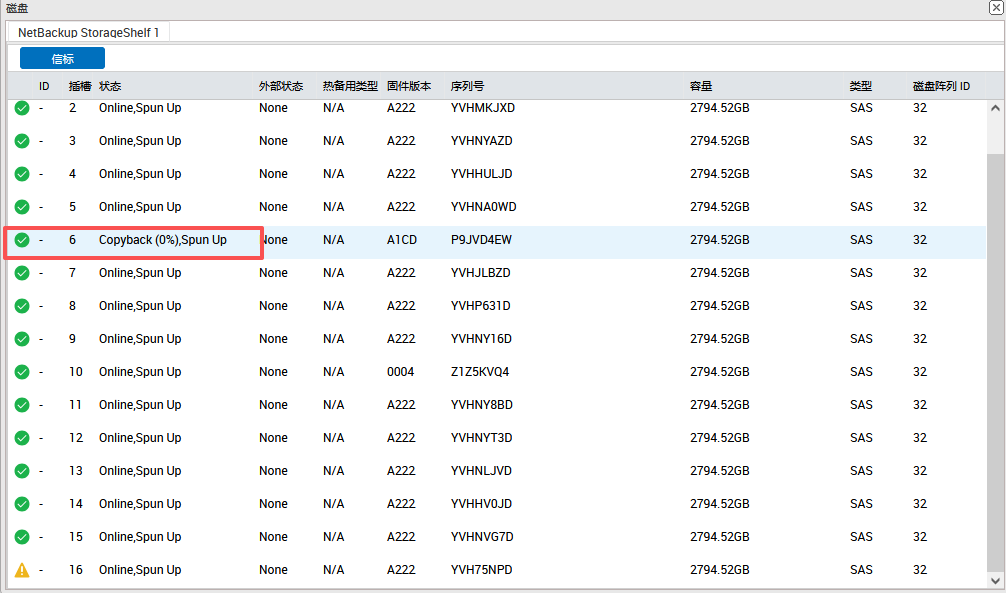
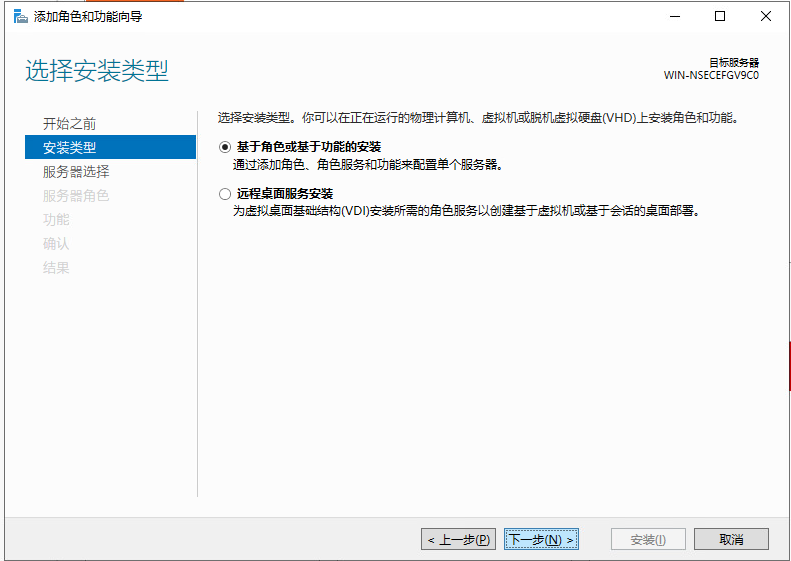
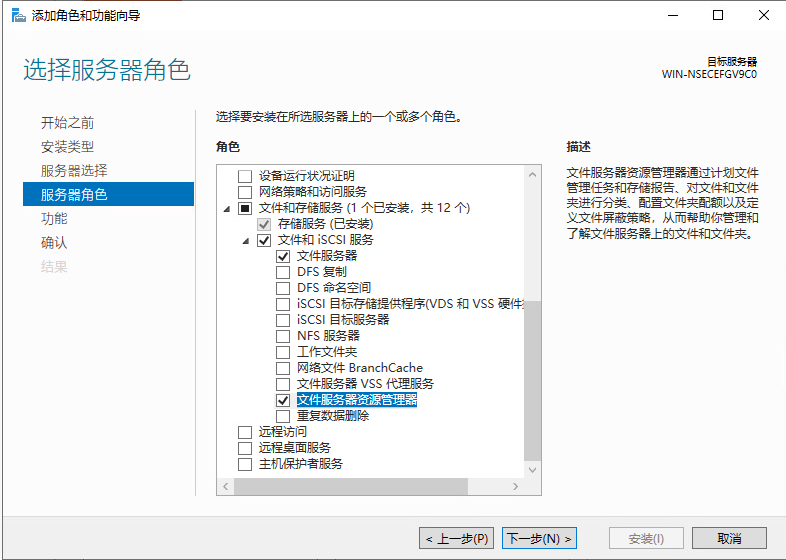
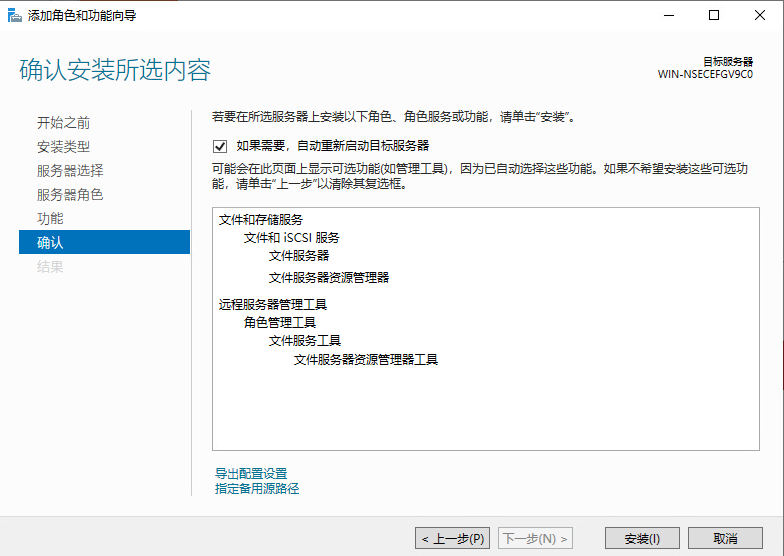
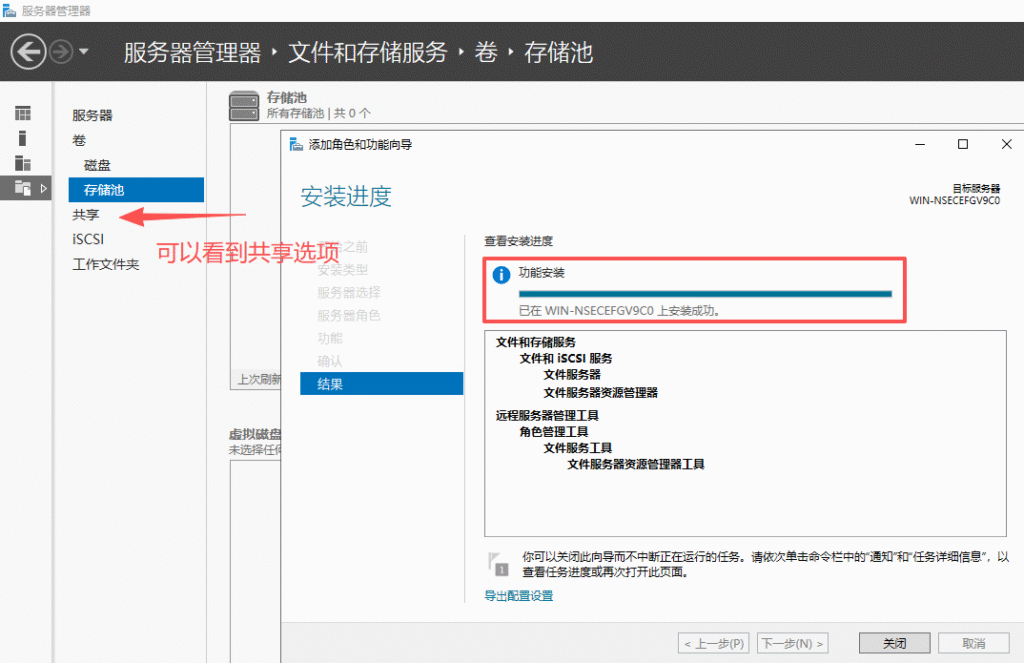
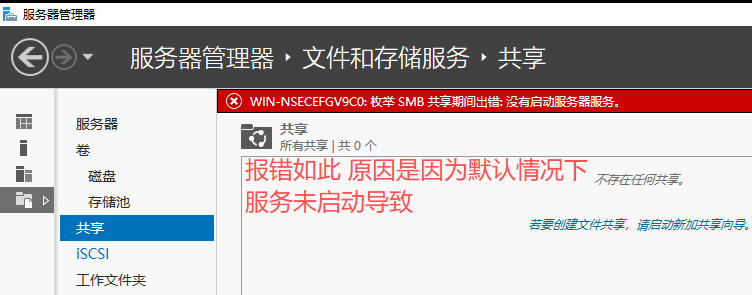
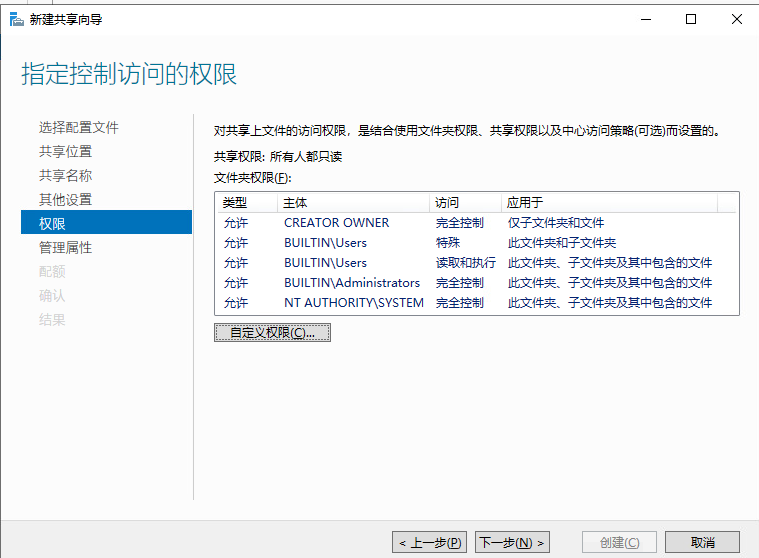
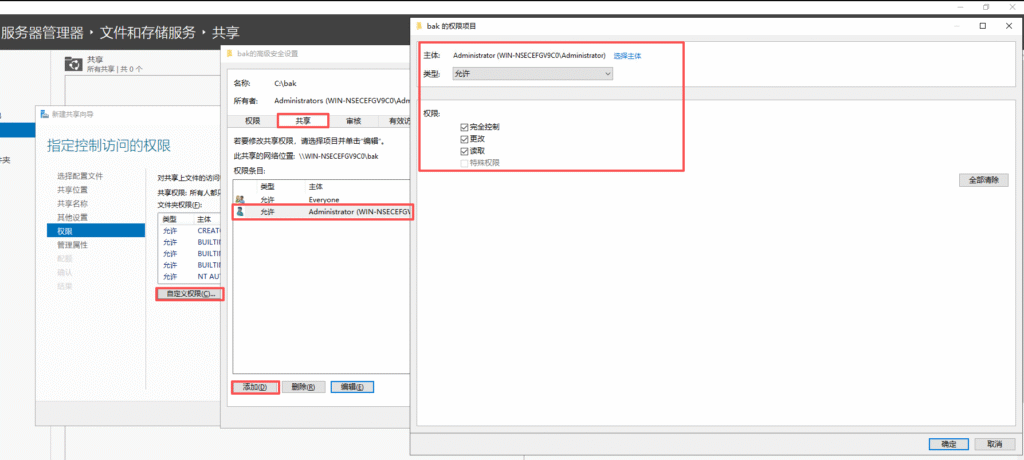
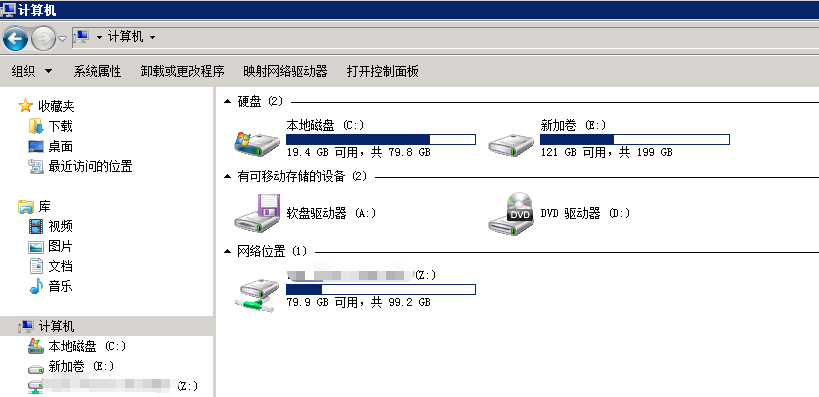
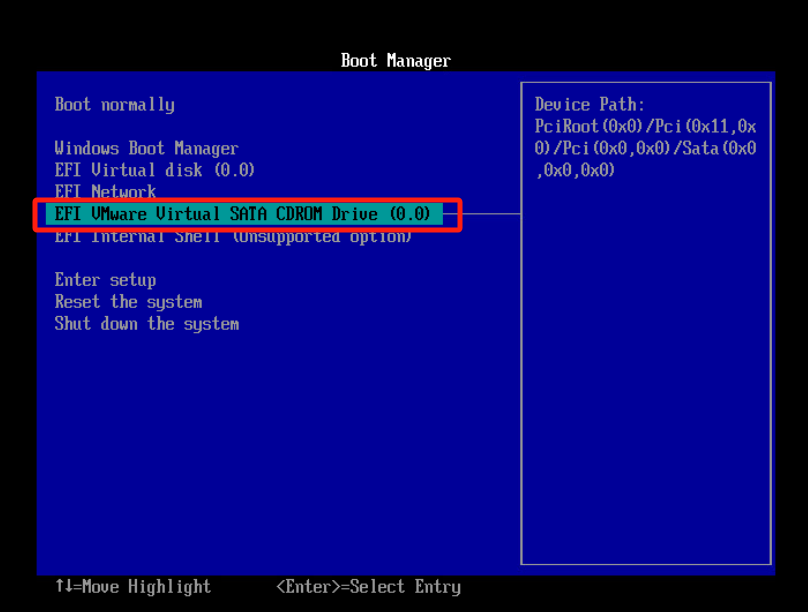
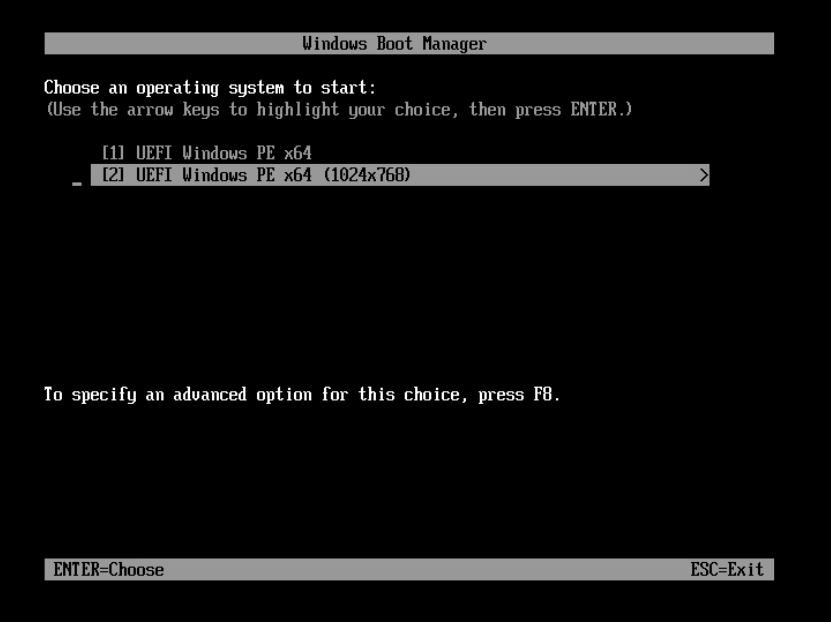
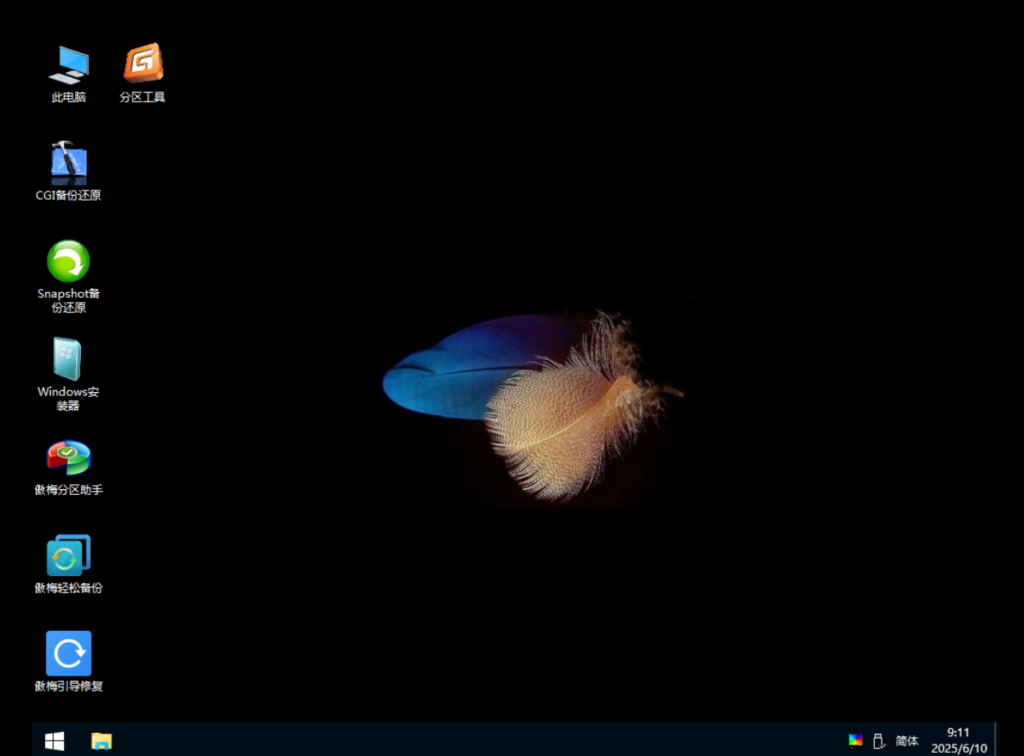
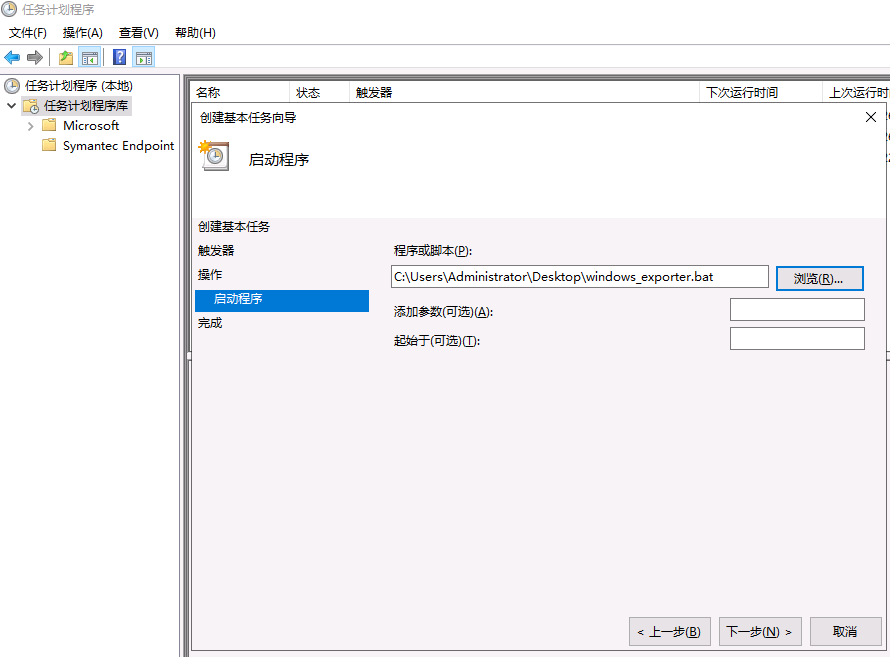
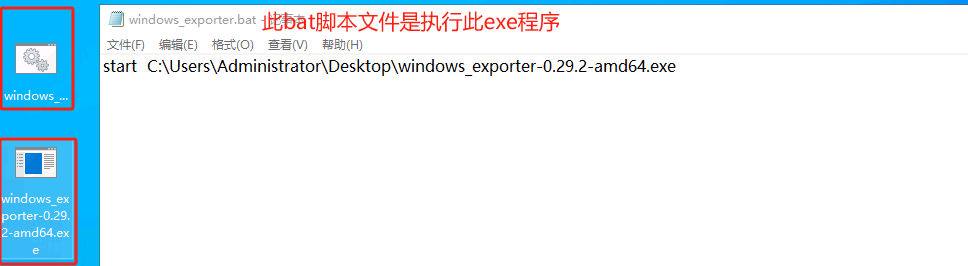
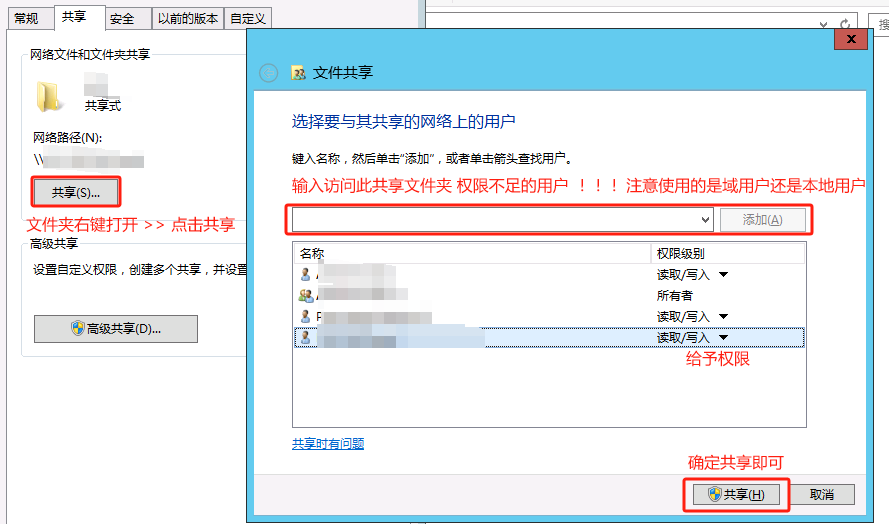
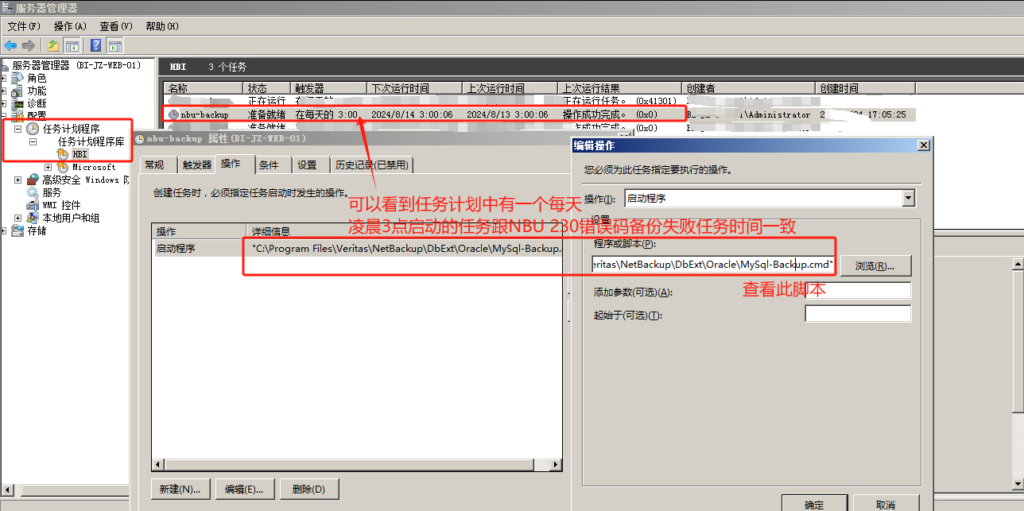
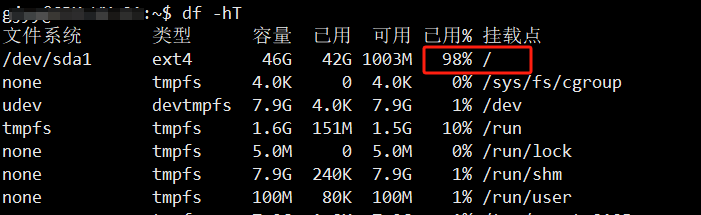
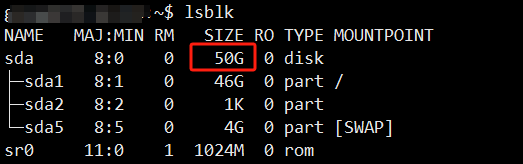
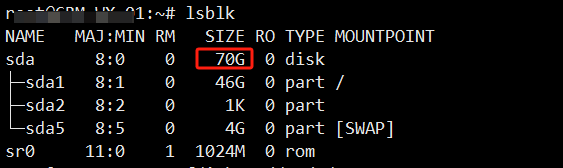
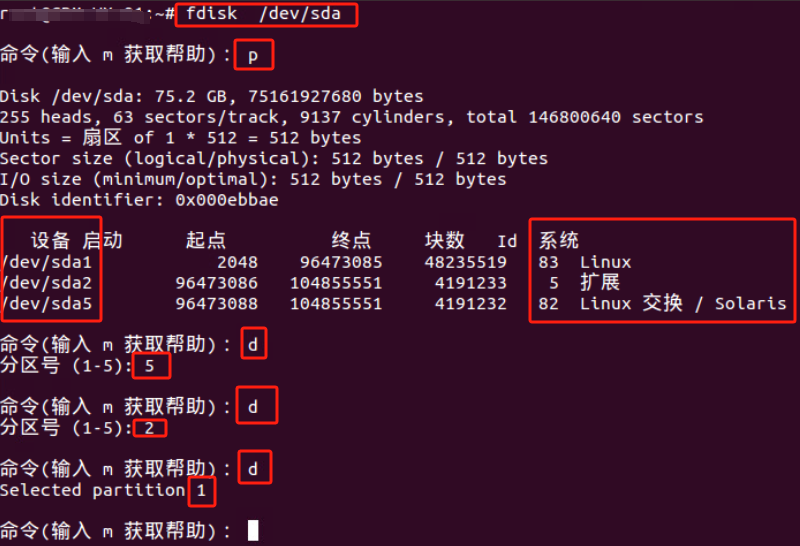
基本磁盘类型 除去系统盘外 可以转为动态磁盘跨区卷 扩容不丢数据 但系统盘若转为动态磁盘:系统启动失败风险:动态磁盘不支持引导加载程序(Boot Loader)。转换后,您的电脑很可能无法正常启动,直接导致黑屏或报错 所以进入PE扩容系统盘
支持UEFI以及BIOS PE镜像
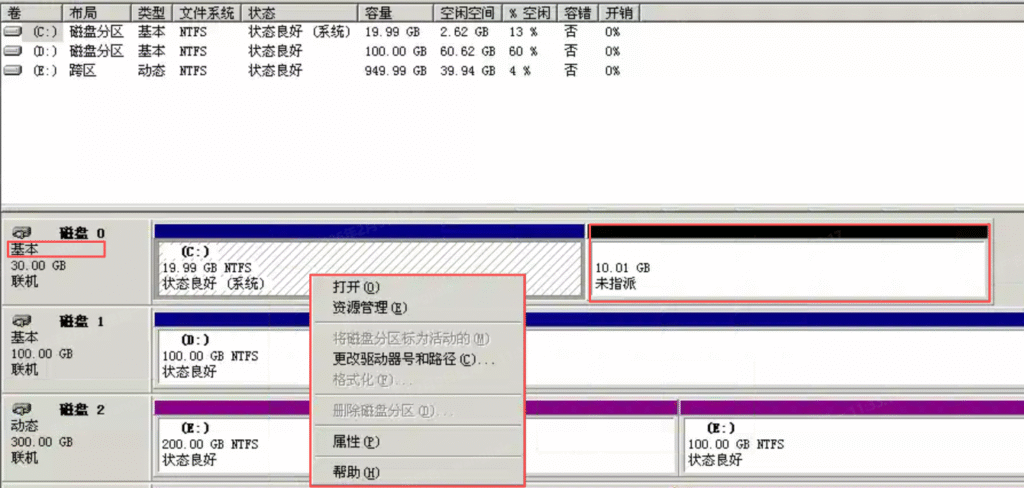
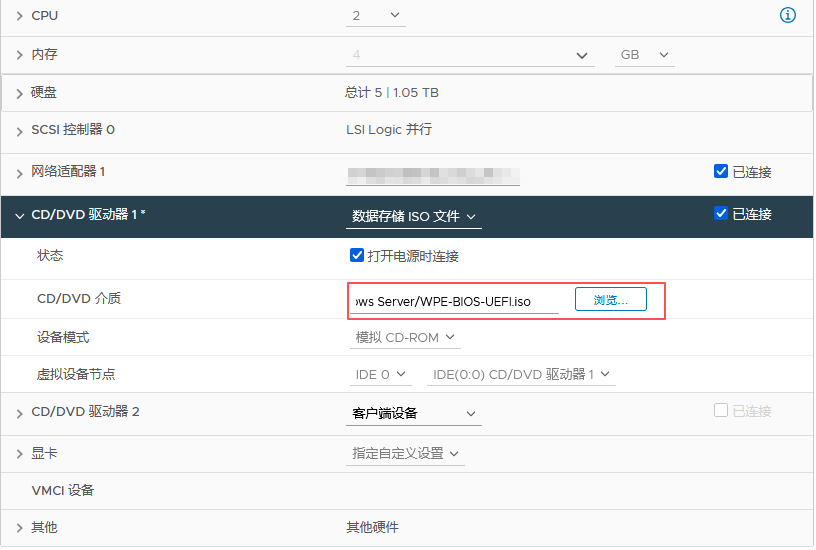
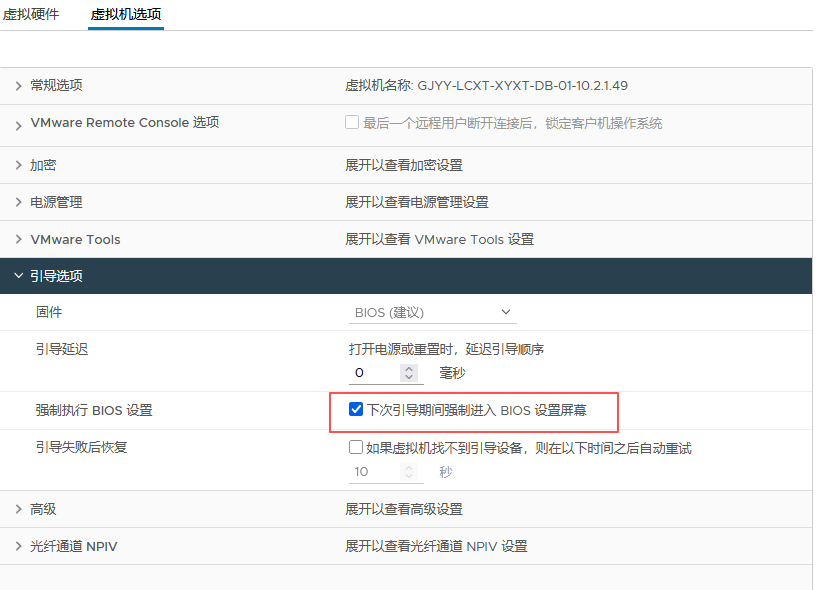
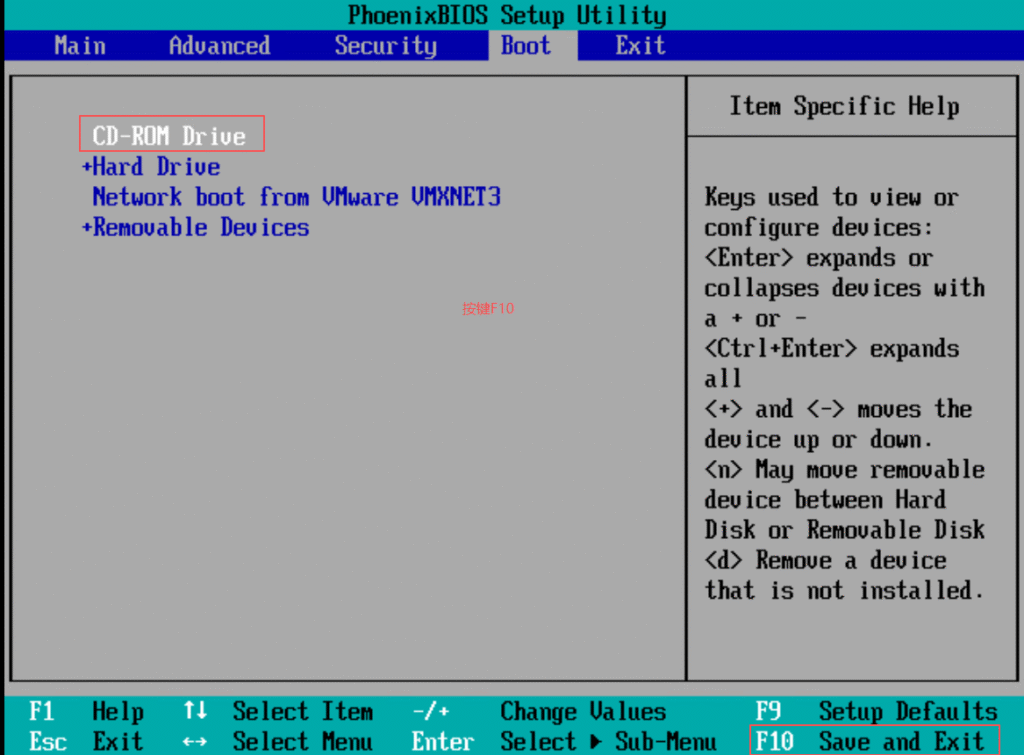
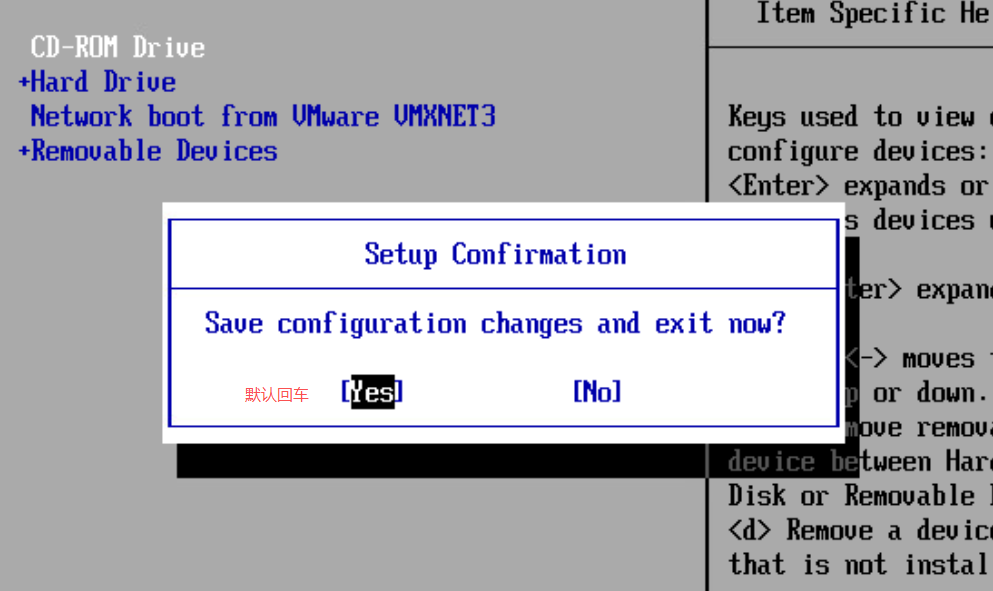

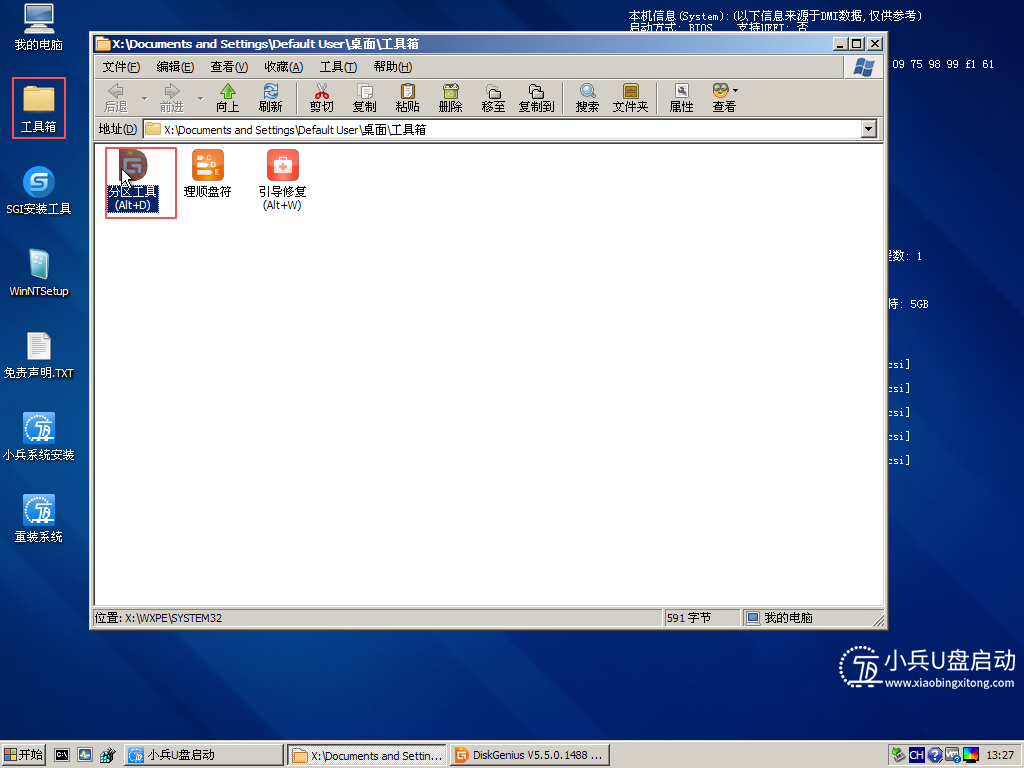
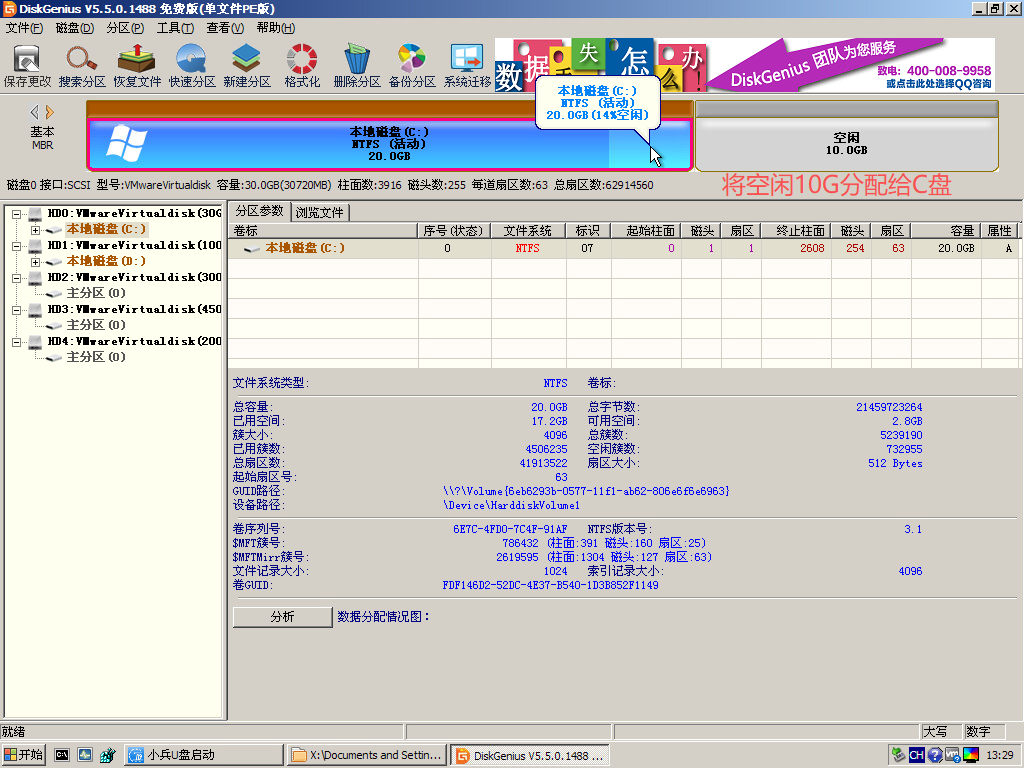
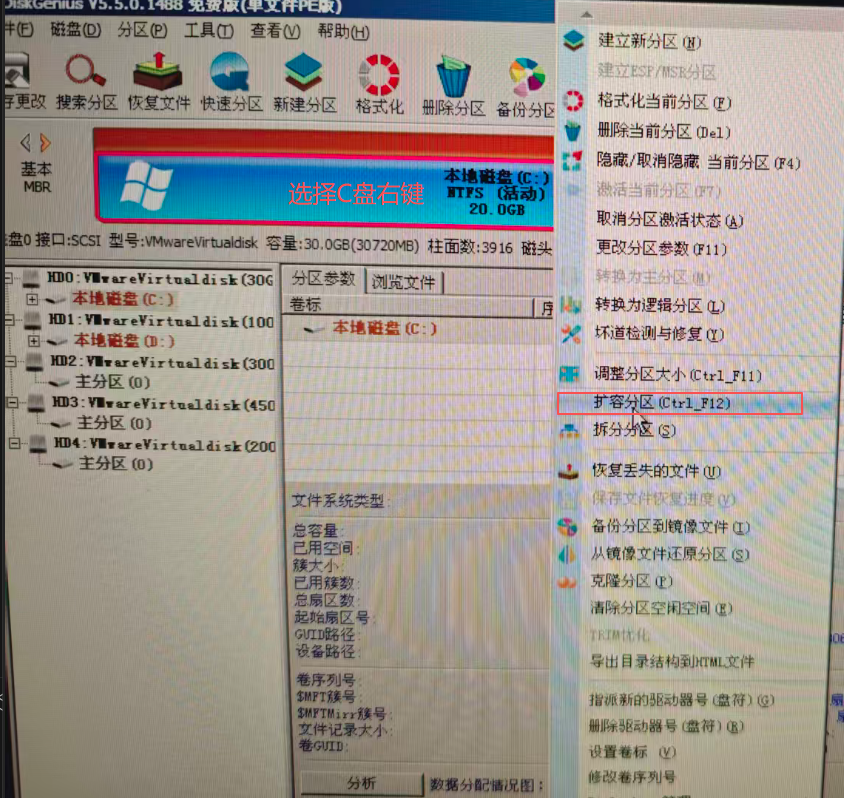
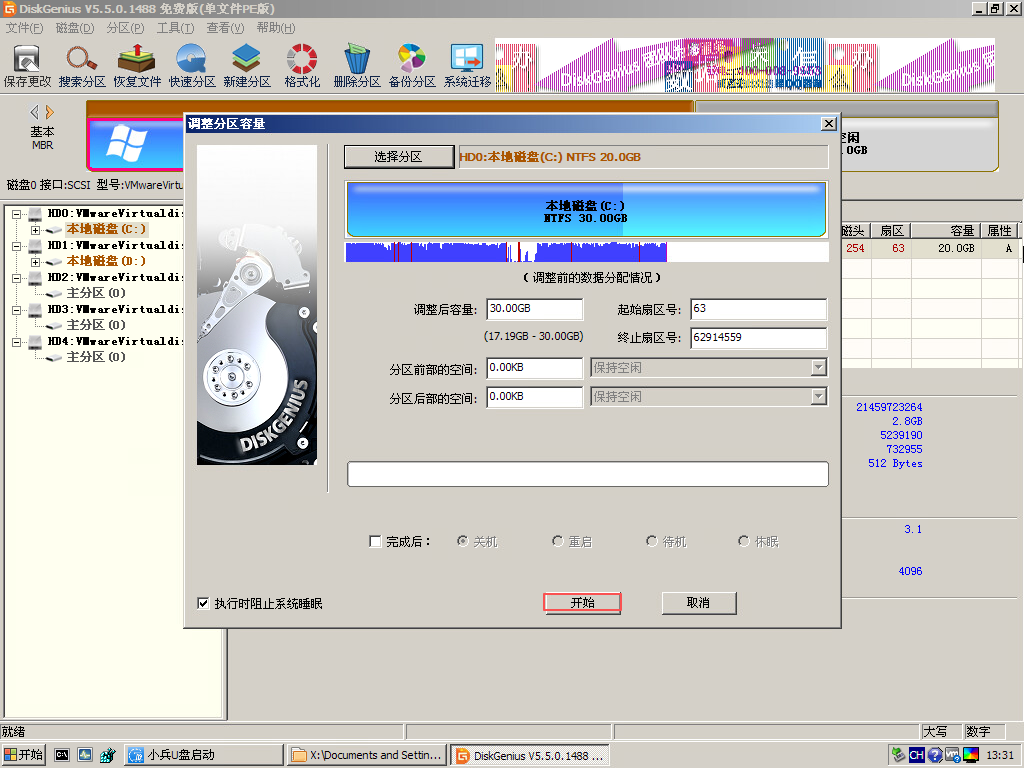
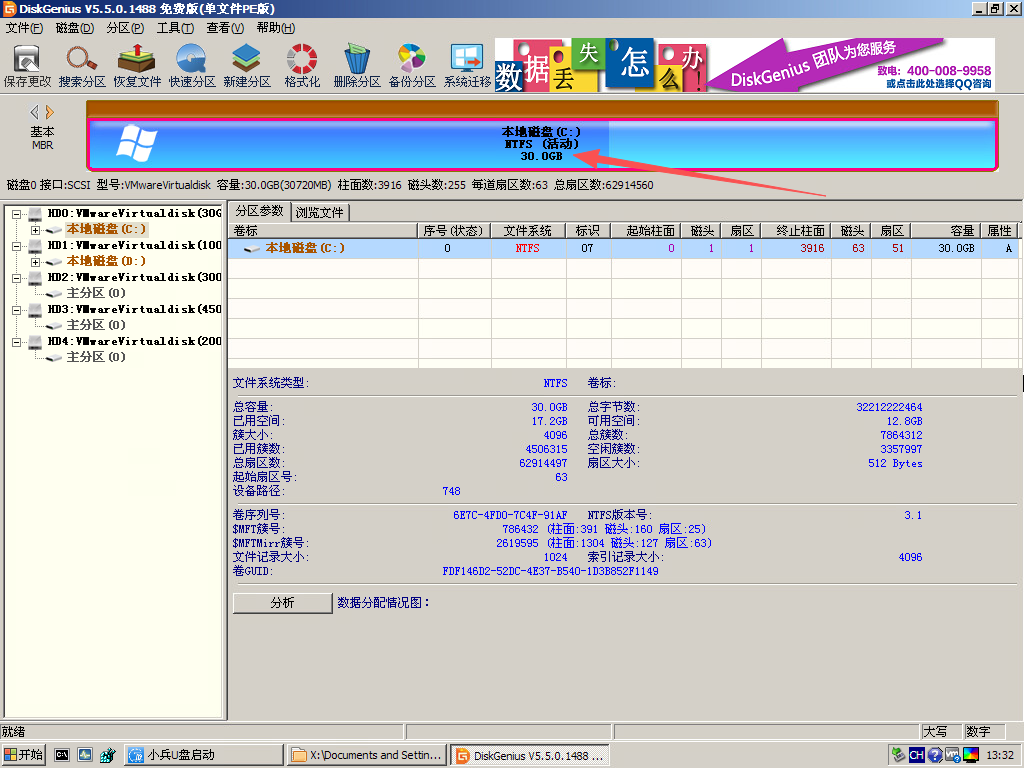

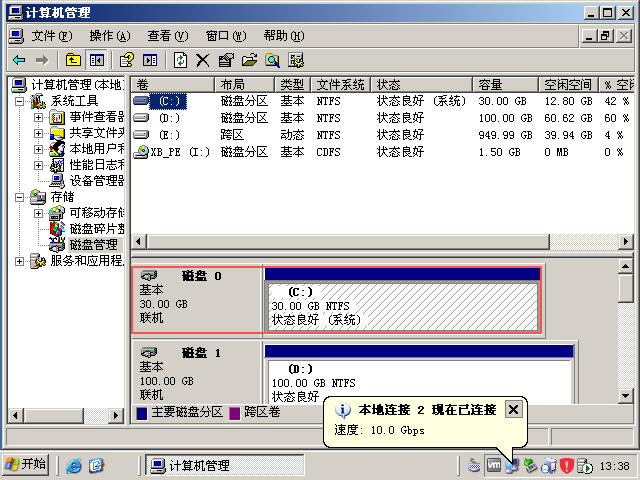
基本磁盘类型 除去系统盘外 可以转为动态磁盘跨区卷 扩容不丢数据 但系统盘若转为动态磁盘:系统启动失败风险:动态磁盘不支持引导加载程序(Boot Loader)。转换后,您的电脑很可能无法正常启动,直接导致黑屏或报错 所以进入PE扩容系统盘
支持UEFI以及BIOS PE镜像

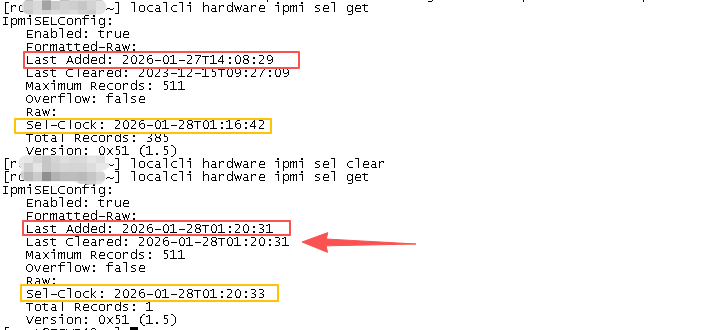
IpmiSELConfig:
启用状态:启用
格式化原始数据:
最后添加时间:2026-01-27T14:08:29 可以看到未清除前最后添加时间与当前时间不一致清除后此值与当前时间一致
最后清除时间:2023-12-15T09:27:09
最大记录数:511
溢出:否Raw:
赛尔时钟:2026 年 1 月 28 日 01 时 16 分 42 秒
总记录数:385
版本:0x51(1.5)


localcli hardware ipmi sel get 查看当前 SEL 日志状态(确认是否已满)
localcli hardware ipmi sel clear 清除 SEL 日志
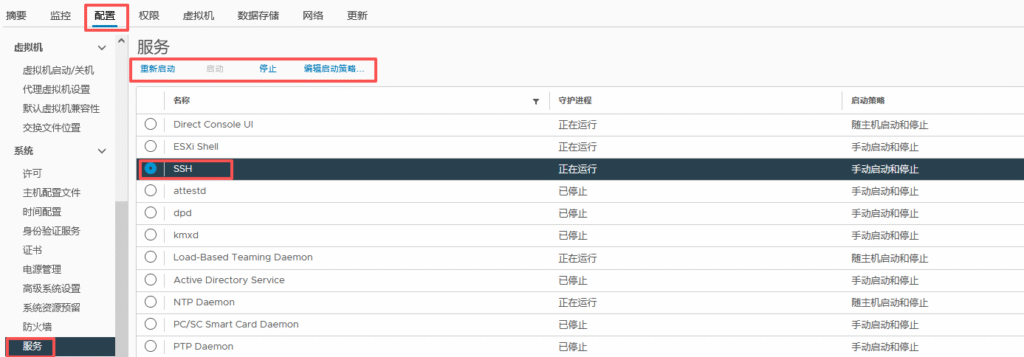
开启SSH
man scp
-l 限速

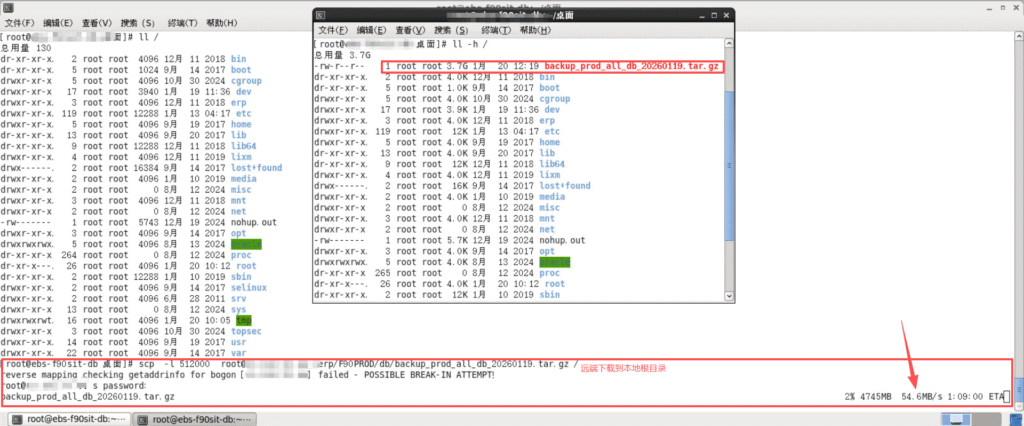
咱们限速50MB
要将50MB转换为Kbit,我们需要进行单位换算:
1 MB (兆字节) = 1024 KB (千字节)
1 KB (千字节) = 1024 Bytes (字节)
1 Byte (字节) = 8 bits (比特)
因此:
50 MB = 50 × 1024 × 1024 × 8 bits = 419,430,400 bits
将bits转换为Kbit (千比特):
1 Kbit = 1000 bits
所以:
419,430,400 bits ÷ 1000 = 419,430.4 Kbit
因此,50MB等于419,430.4 Kbit。忽略小数点也就是419430
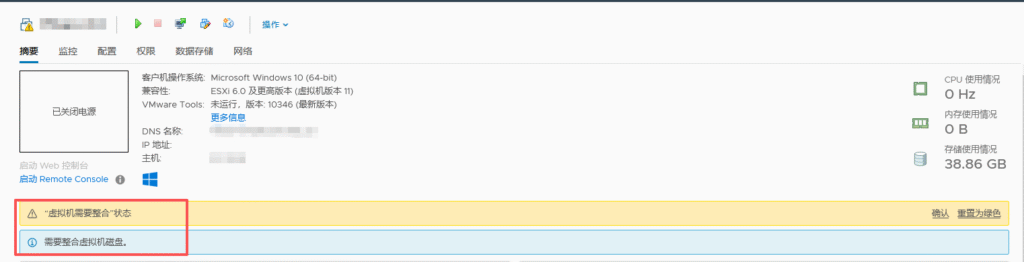
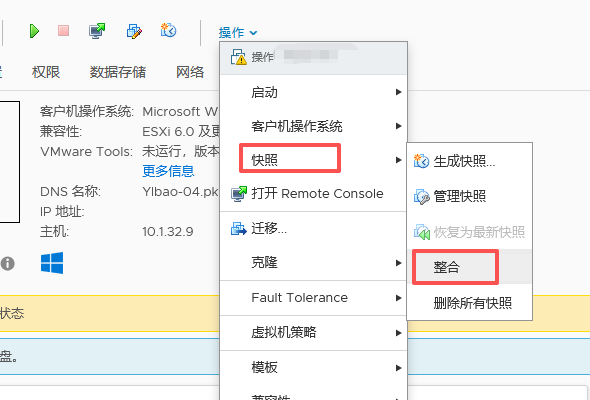
不要将虚拟机快照当作备份:快照依赖于父磁盘,删除父磁盘后快照文件无法恢复虚拟机
不要拍摄超过3个快照:保留的快照越多,对虚拟机性能的影响越大
不要保留快照超过72小时:长时间保留快照会占用更多的磁盘空间,影响性能
注意点!!!
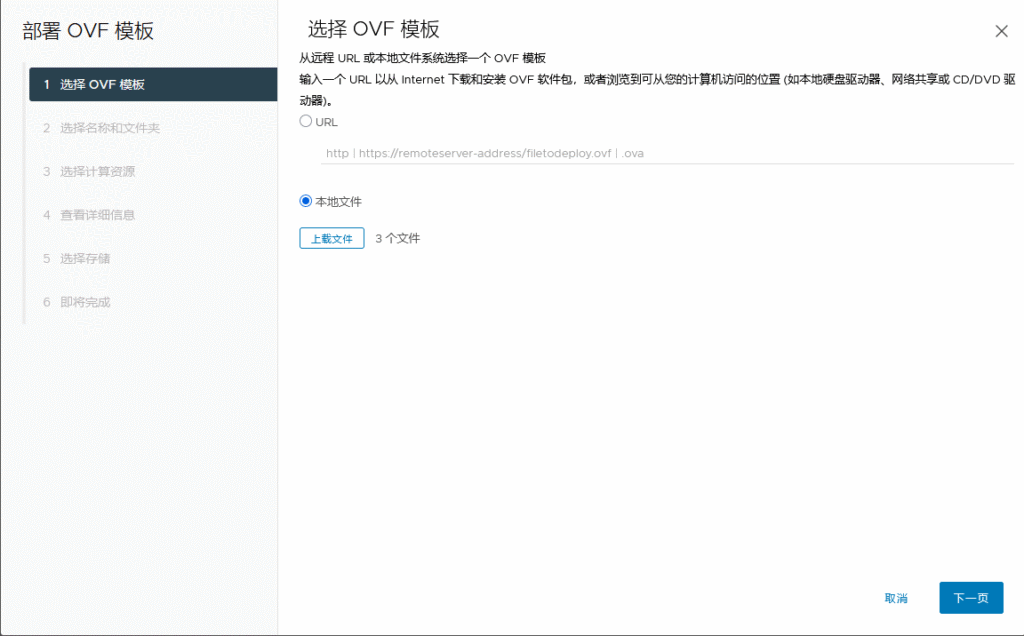
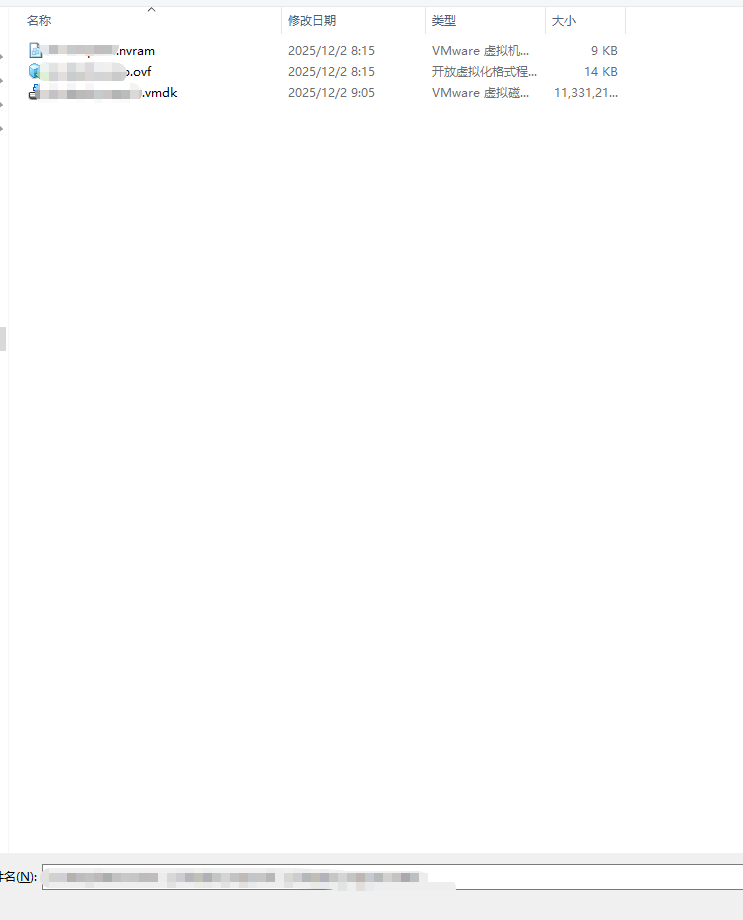
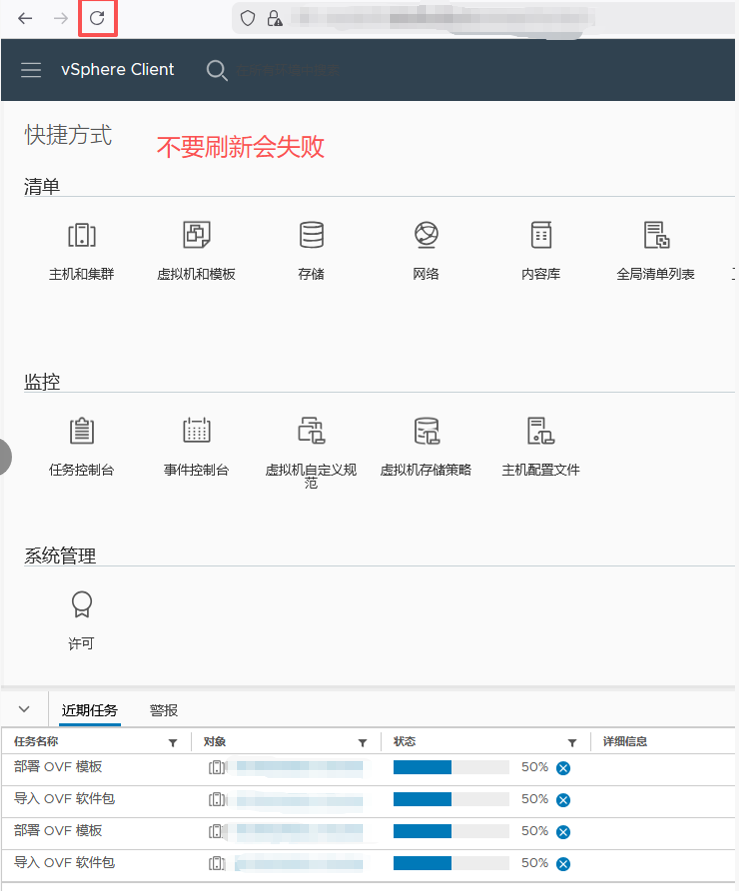
1、不要出现任何中文名称 如果有中文.ovf文件里对应的中文名称可能是乱码。如果是乱码,直接修改成英文名即可,同步修改.vmdk的文件名后导入
2、编辑设置删除CD/DVD驱动器 不然会找不到这个磁盘映像也可以编辑.ovf文件,找到ovf:href="***.nvram",把这一行注释掉导入
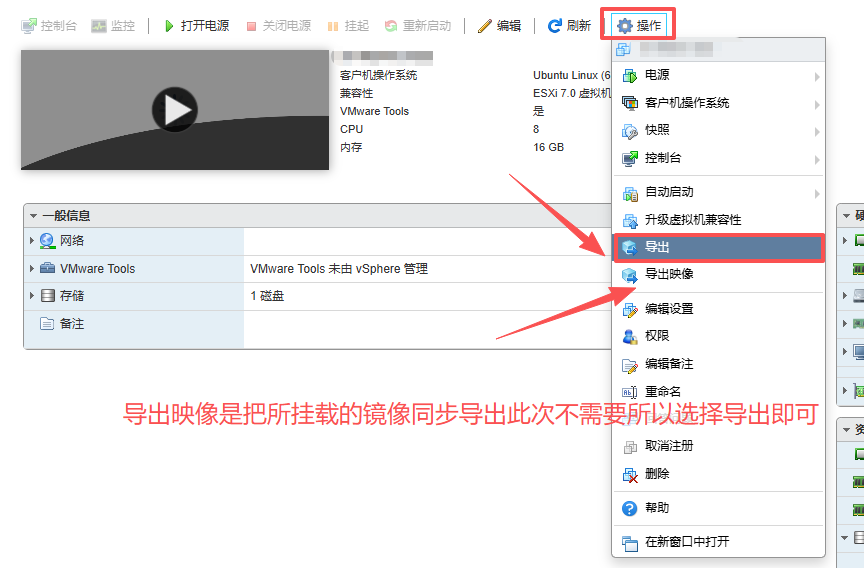
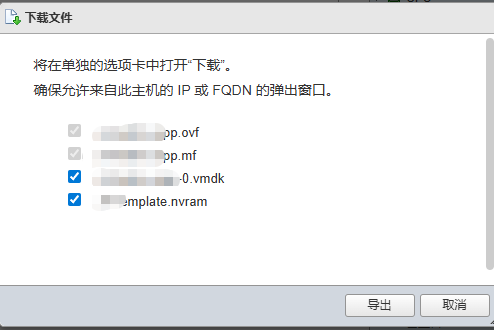
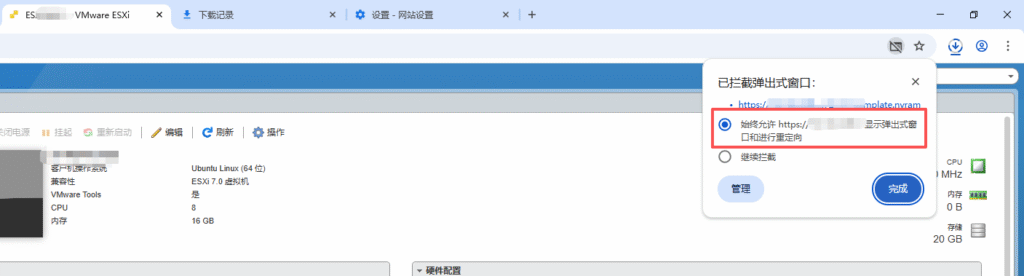
之后再次重新导出 因为本次导出前是拦截的 少个nvram文件

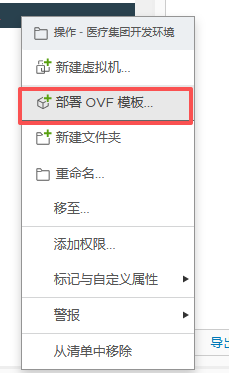
转载链接:https://www.cnblogs.com/byx1024/p/12936030.html
通过事件查看器得到是因为Windows未激活导致的关机 因为其评估版原因 而标准版、数据中心版未激活不会出现该问题
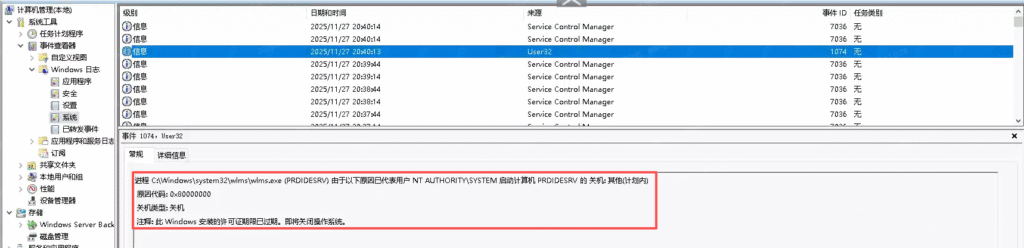

转为正式版再激活不会丢数据 cmd输入
标准版:ServerStandard
DISM /online /Set-Edition:ServerStandard /ProductKey:WC2BQ-8NRM3-FDDYY-2BFGV-KHKQY /AcceptEula
数据中心版:ServerDatacenter
DISM /online /Set-Edition:ServerDatacenter /ProductKey:CB7KF-BWN84-R7R2Y-793K2-8XDDG /AcceptEula大致耗时20分钟左右删除程序包 重启计算机
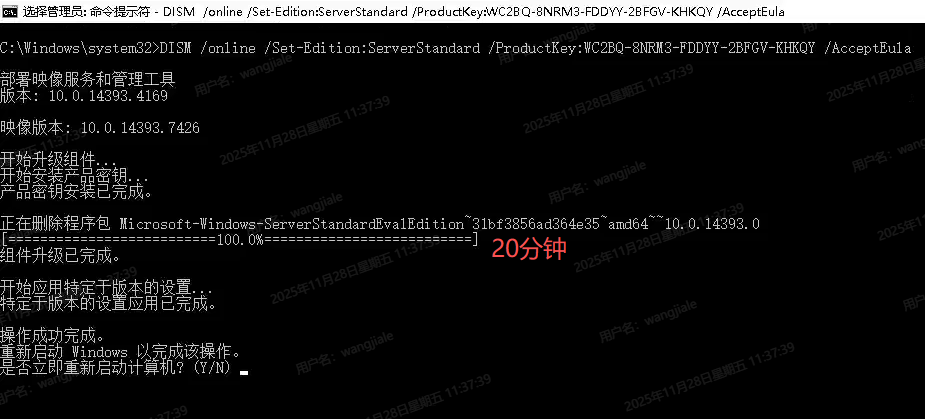
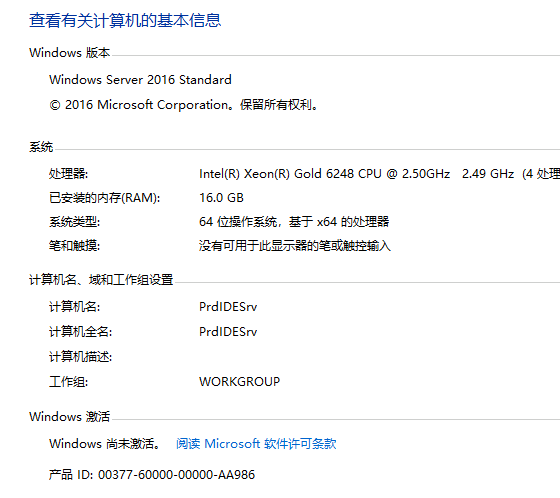
可以看到标准版 未激活不会自动关机

博客上的各种各样的解决方法均不生效 因为其针对win server的且 KB2661332.msu补丁打不上
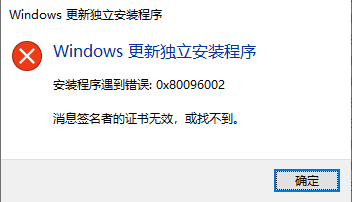
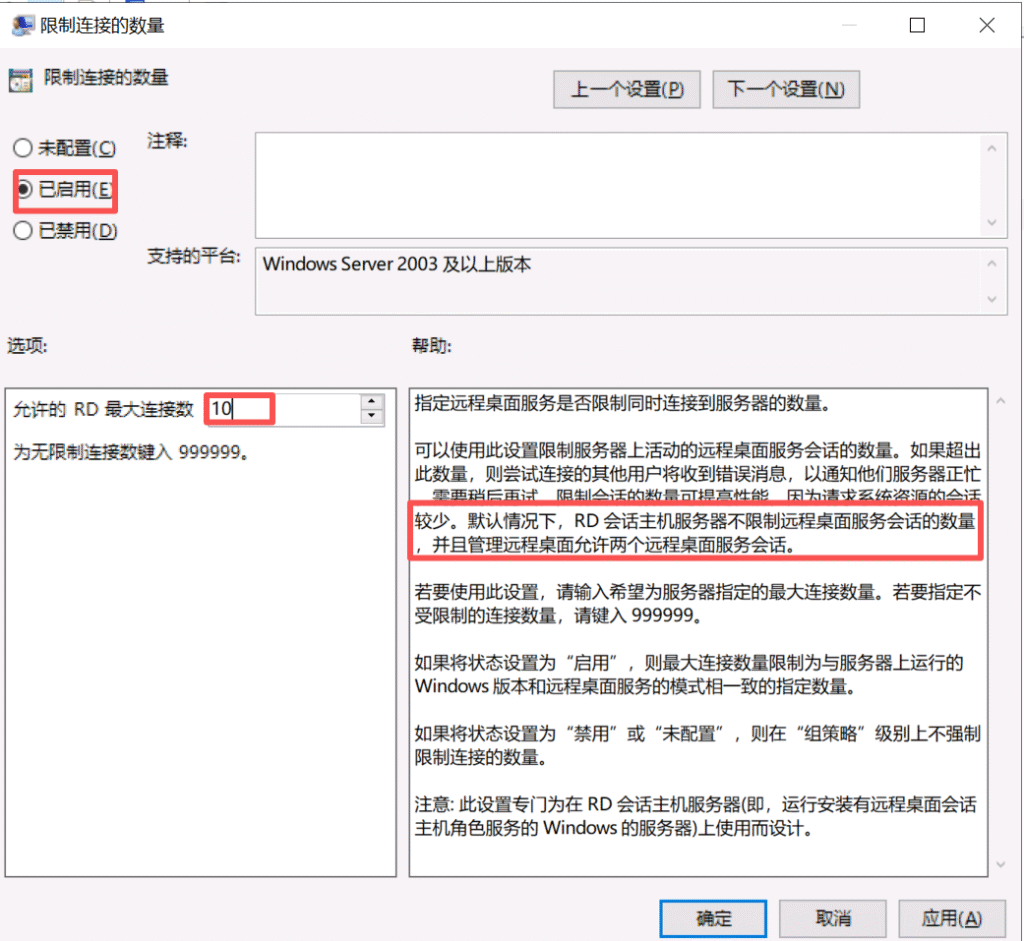
输入 gpedit.msc,打开本地组策略编辑器 导航到 计算机配置>>管理模板>>Windows组件>>远程桌面服务>>远程桌面会话主机>>连接
查看到限制连接的数量为100将其修改为了5
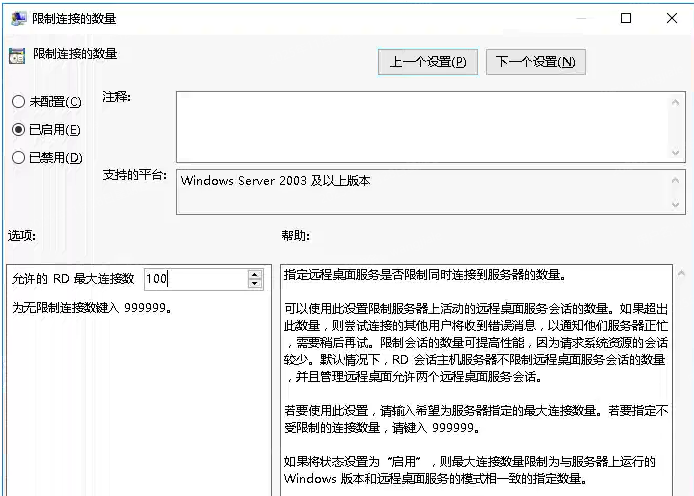
查看到是已禁用修改为未配置
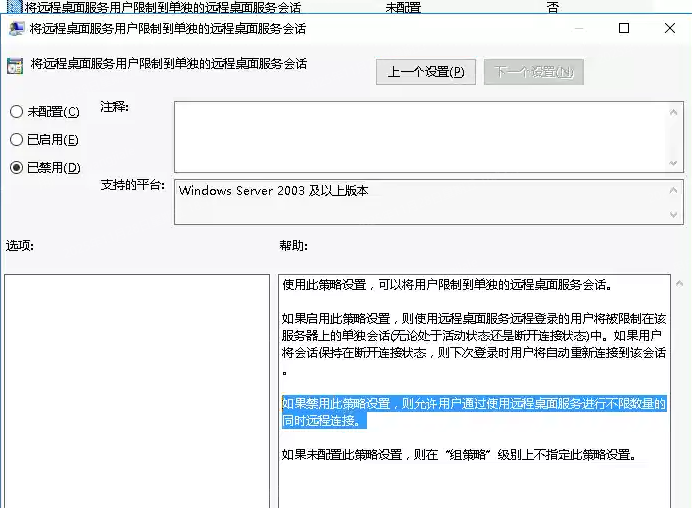
经上述操作 问题没有复现
不要运行任务程序先关机再开机后win+r打开运行输入%temp%
该文件夹是 Windows 系统用于存储临时文件的目录
避免误删系统文件:且勿直接删除 %temp% 文件夹本身,仅清空其内容即可。
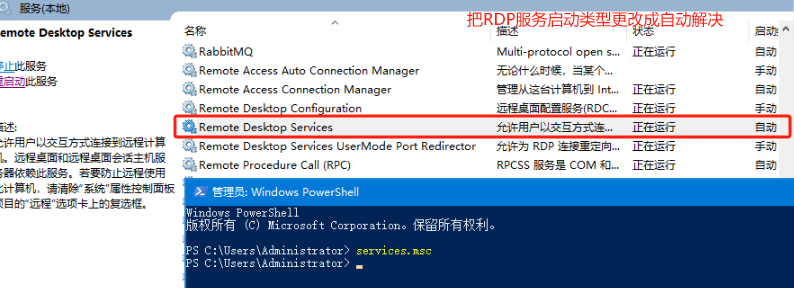
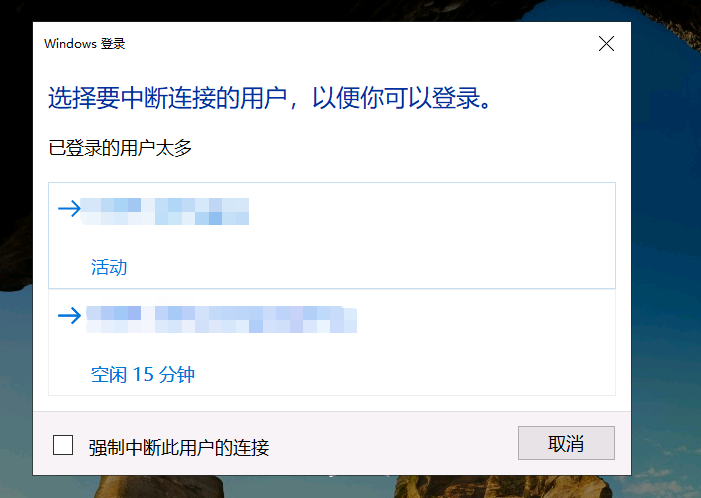
默认情况下,Windows Server允许最多两个用户同时登录。如果要支持更多的用户并发登录,则需要组策略启用会话连接数和安装远程桌面服务
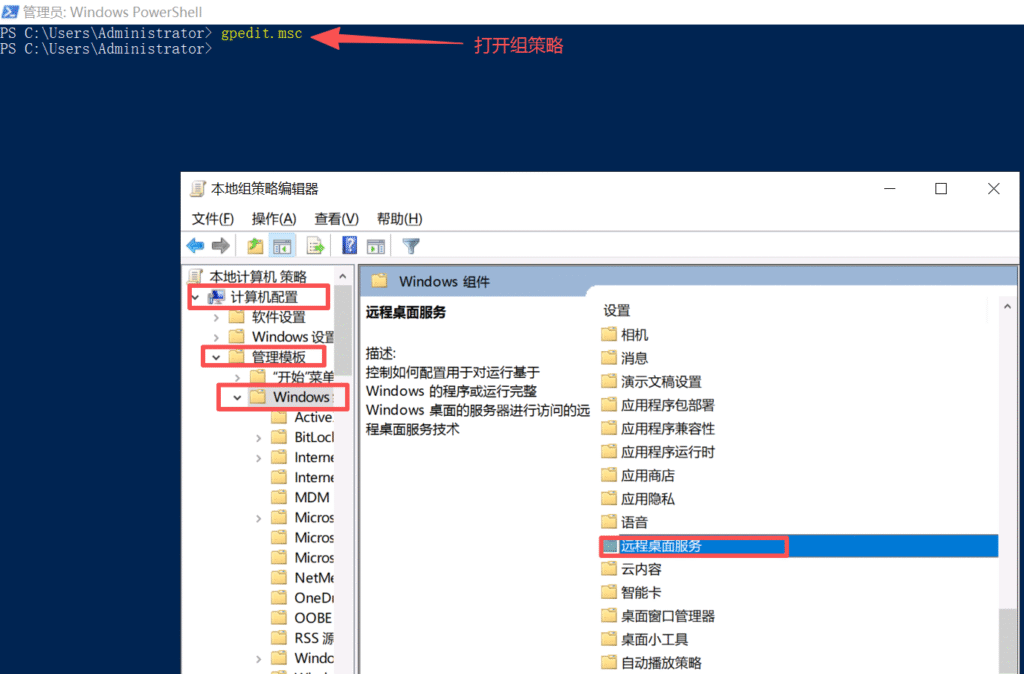
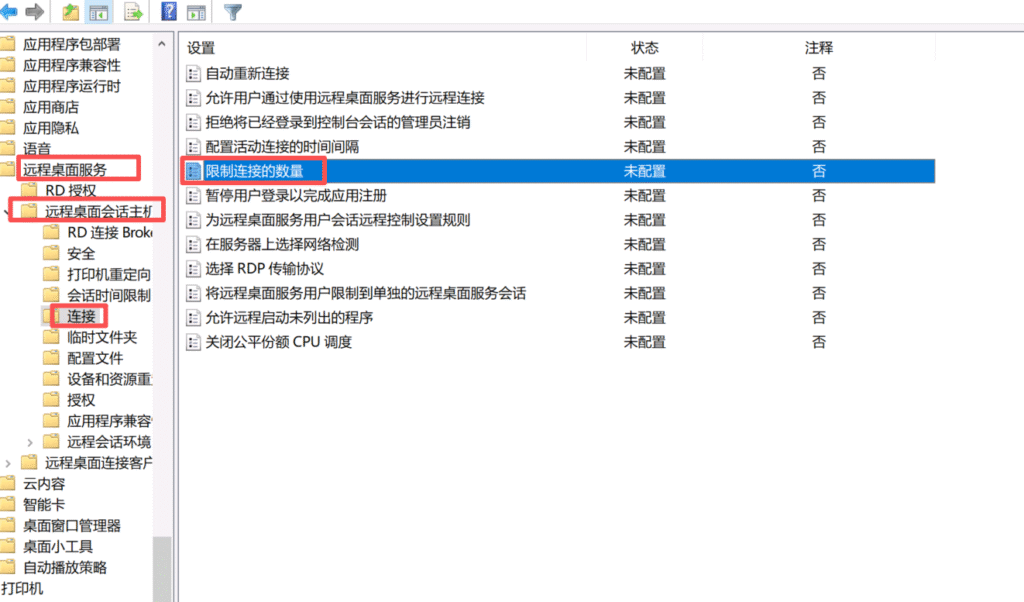
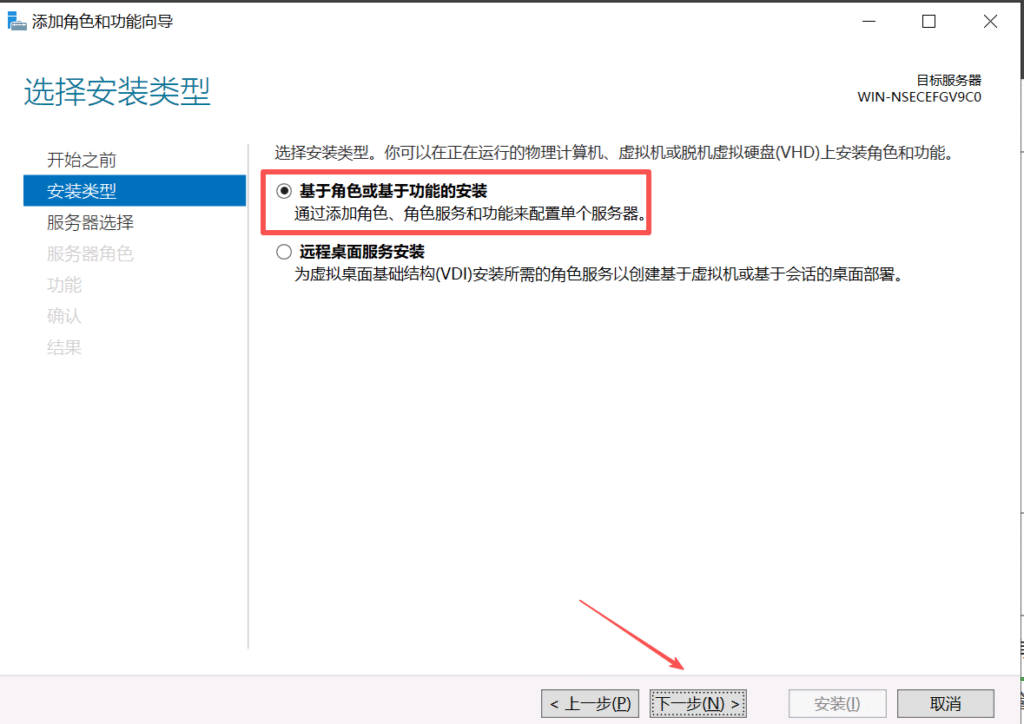
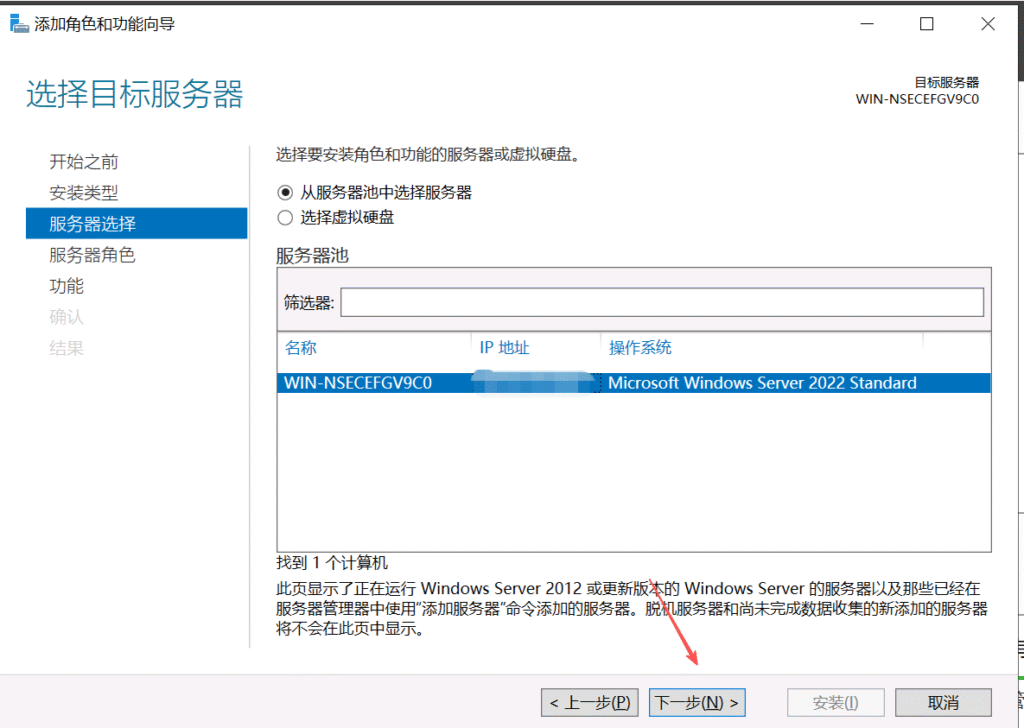
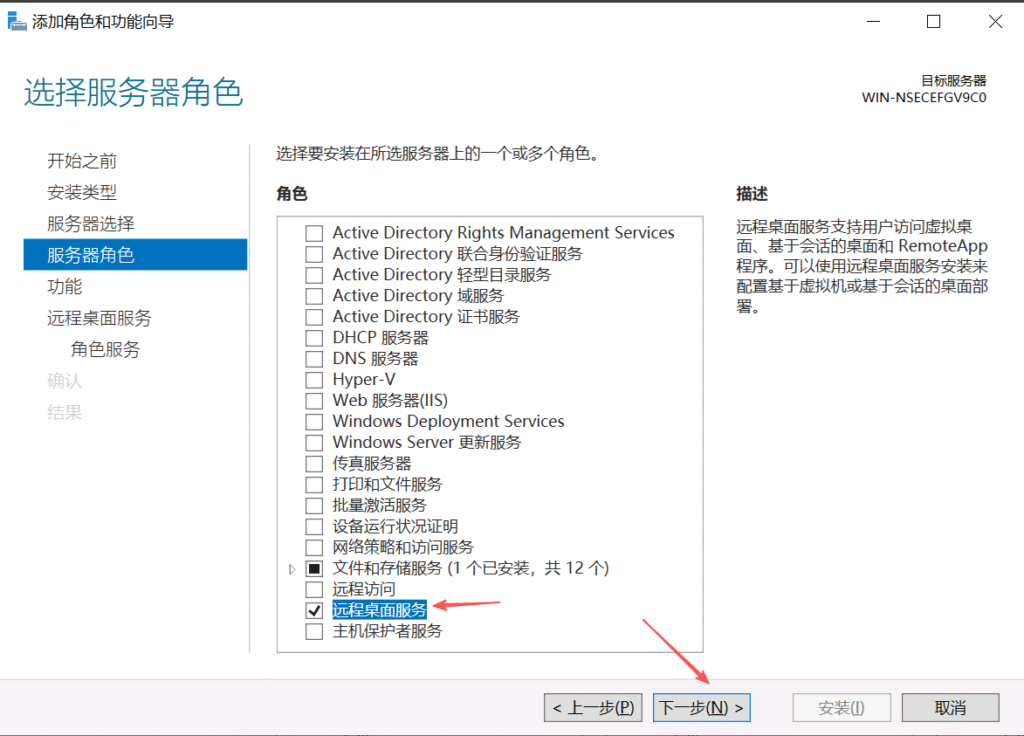
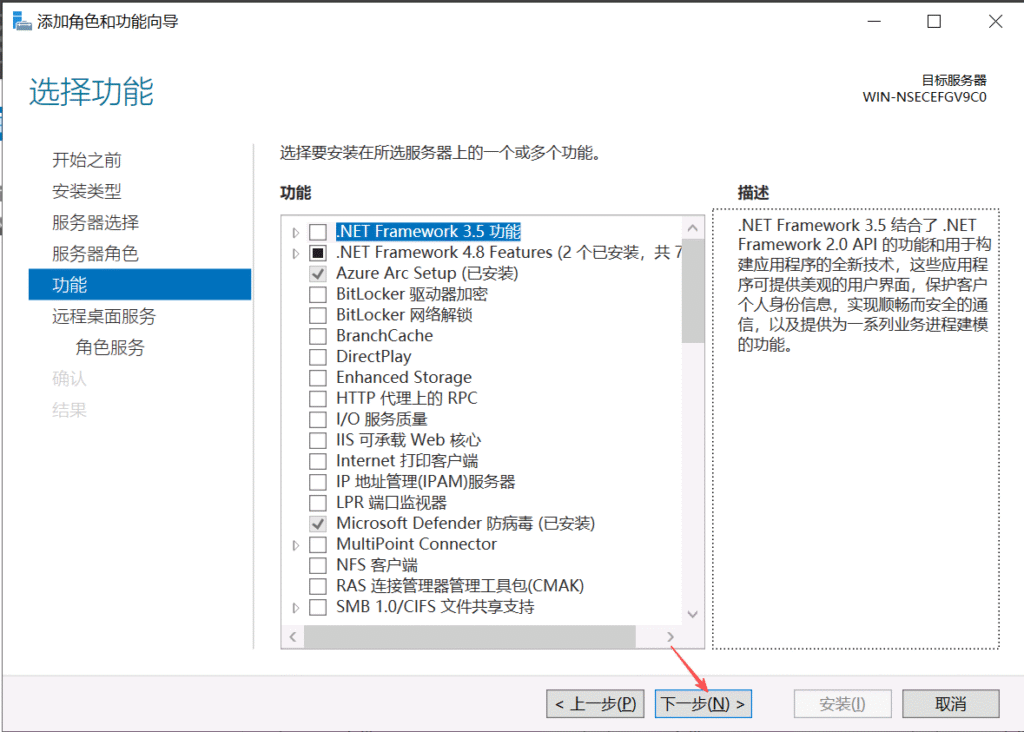
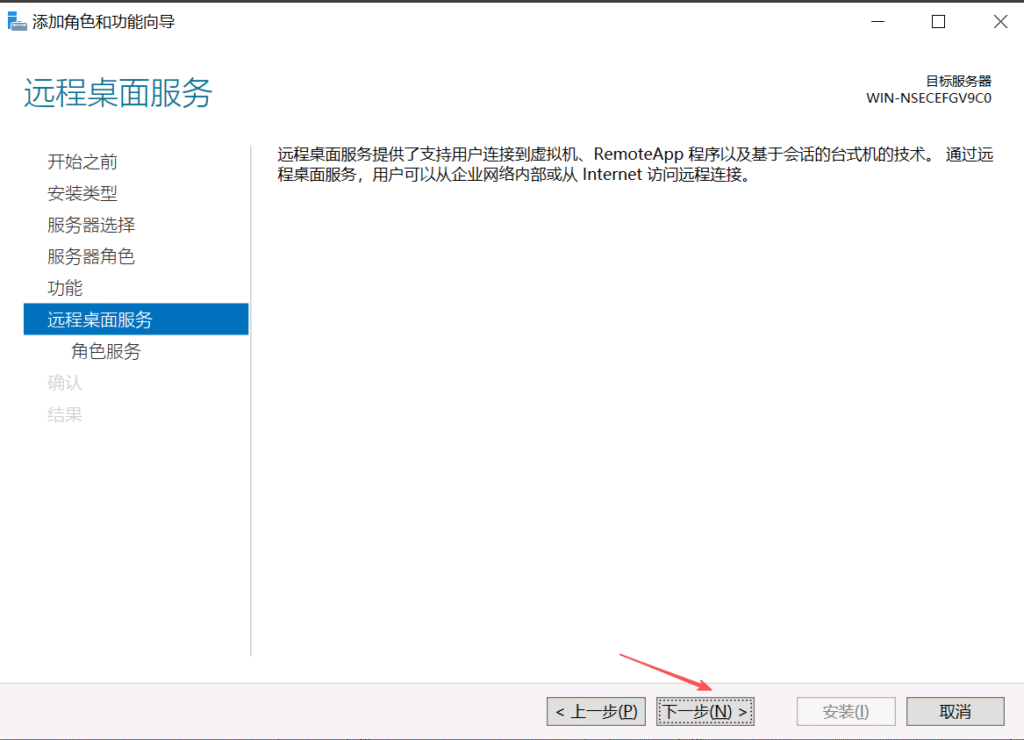
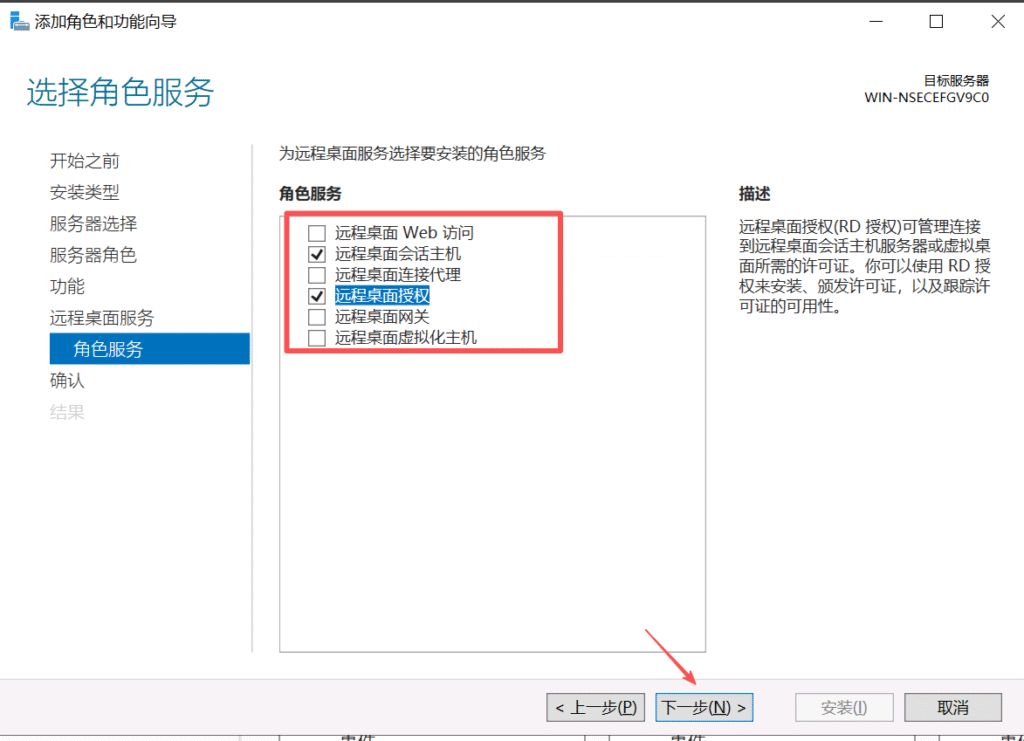
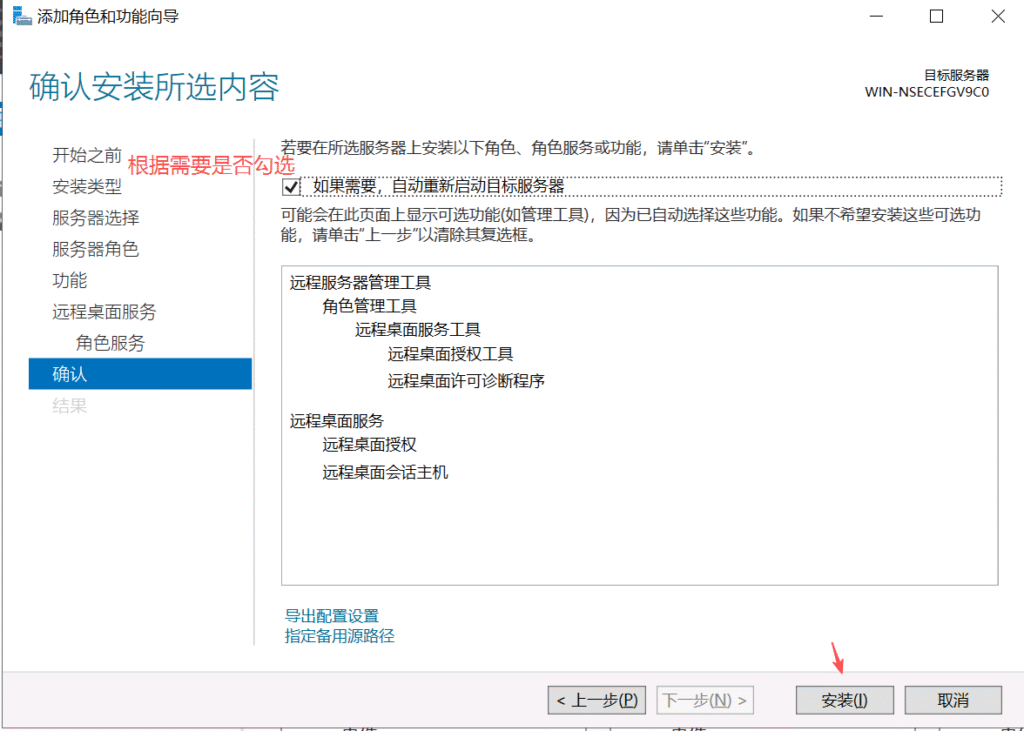
重启机器后RDP解决成功
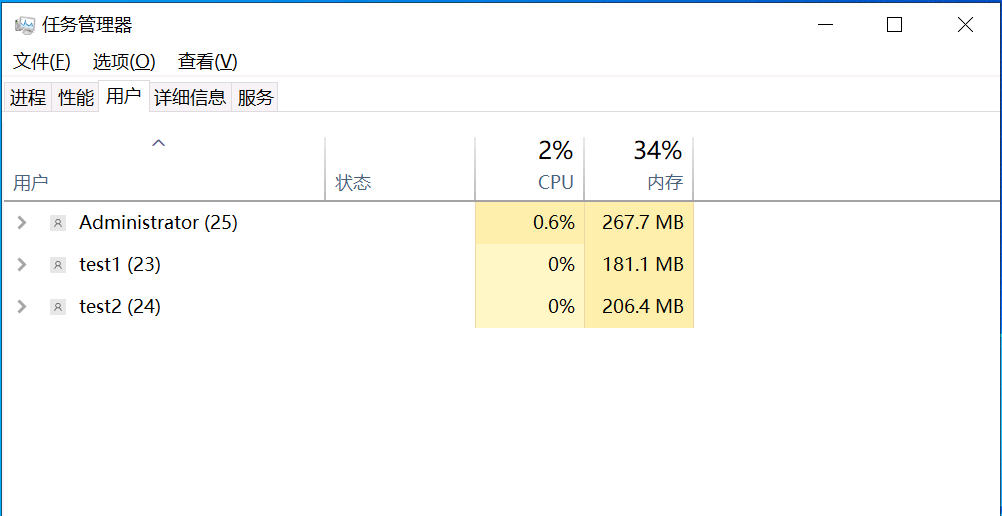
继上述操作后 RDS服务会有120天授权期 报错由于没有远程桌面授权服务器可以提供许可证,远程会话连接已断开。请跟服务器管理员联系。
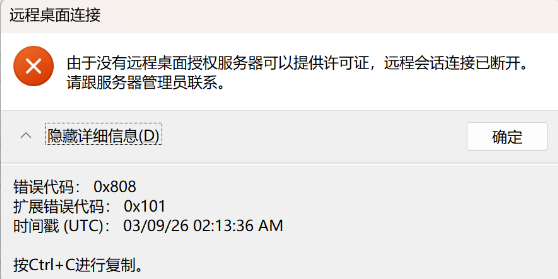
参考链接https://blog.csdn.net/dgxj_skxx/article/details/134893558
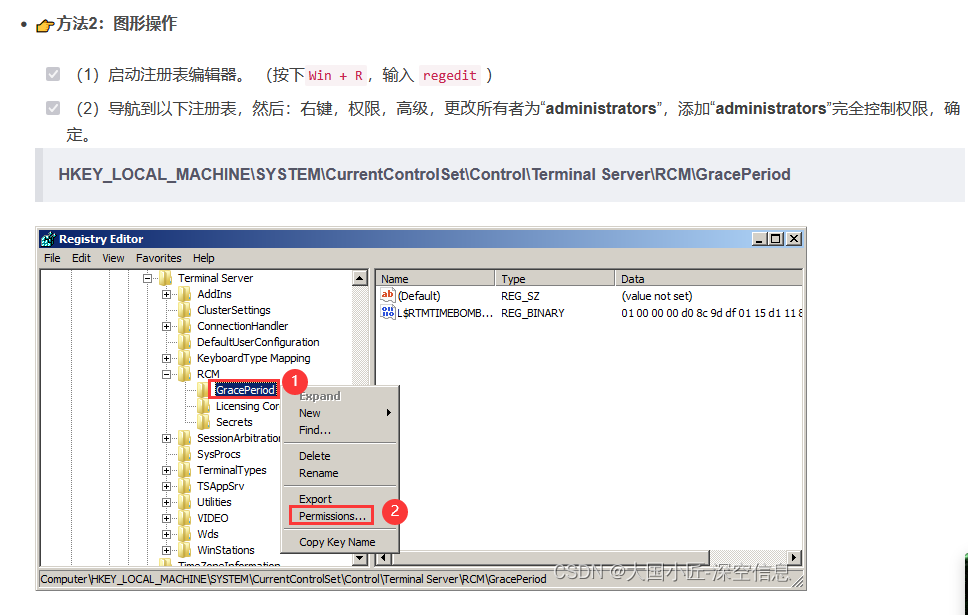
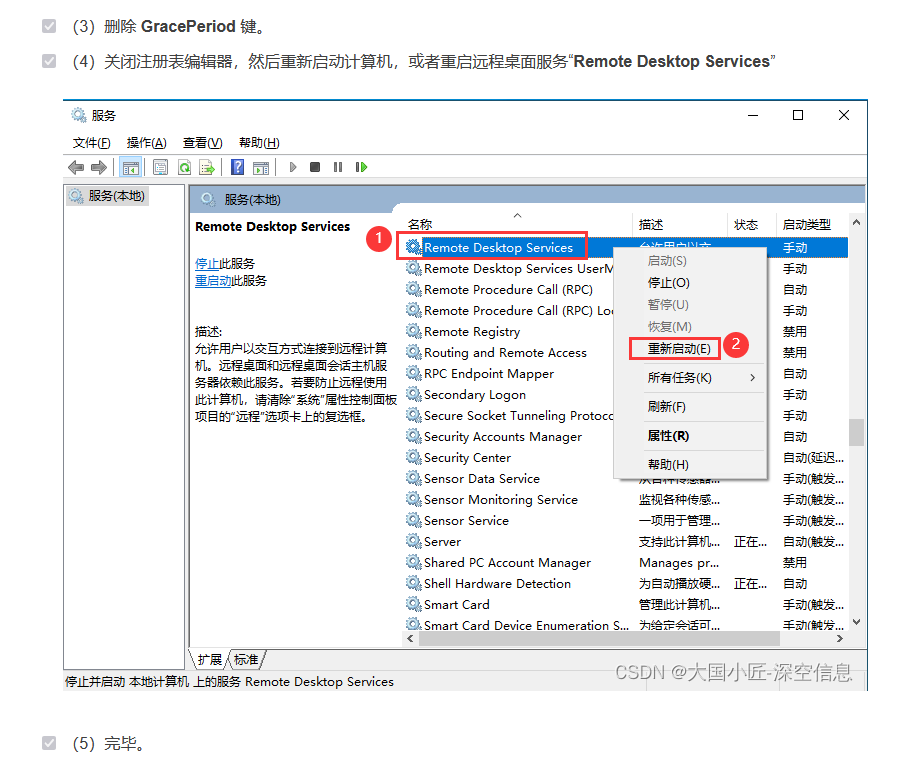
参考链接https://blog.csdn.net/lzh99rsq/article/details/152008391

用以下方式成功解决

Test-Computersecurechannel -credential 域账号(域名\管理员域账号) -Repair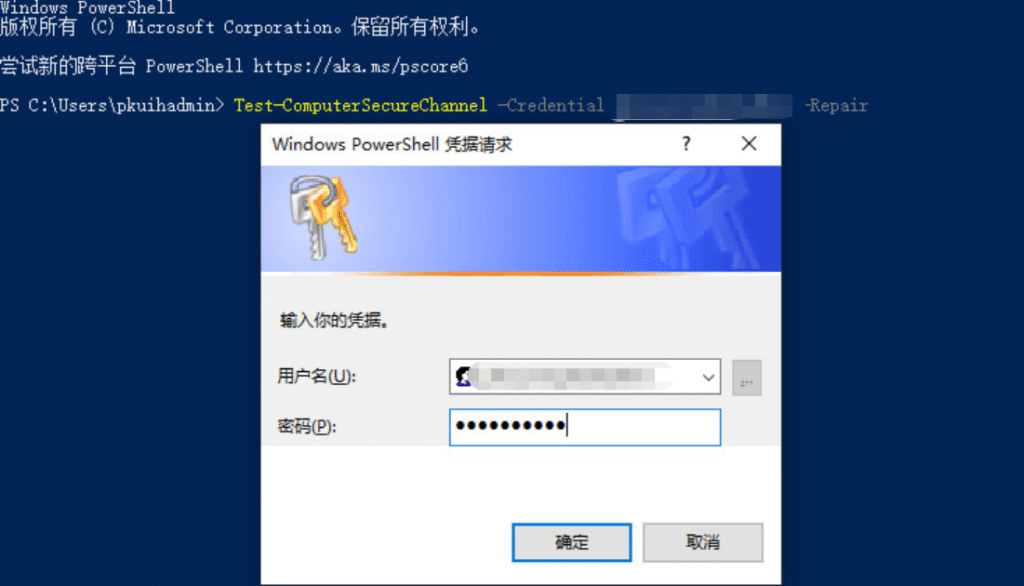
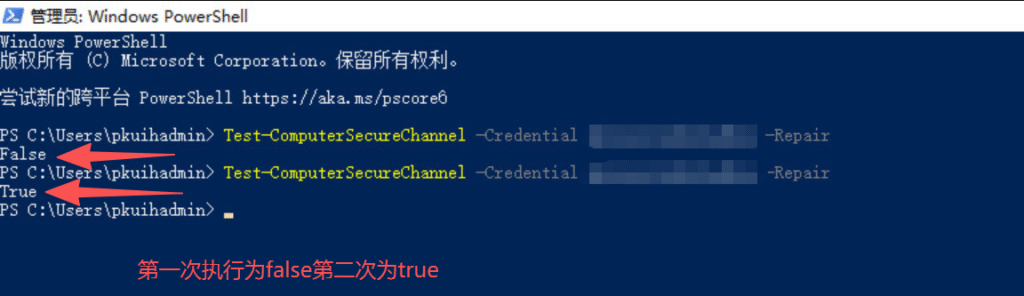
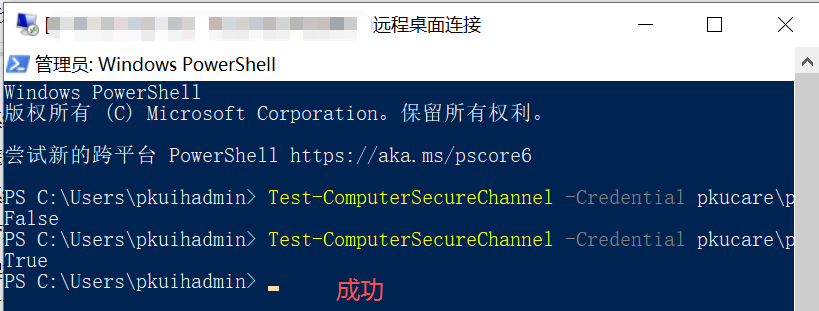
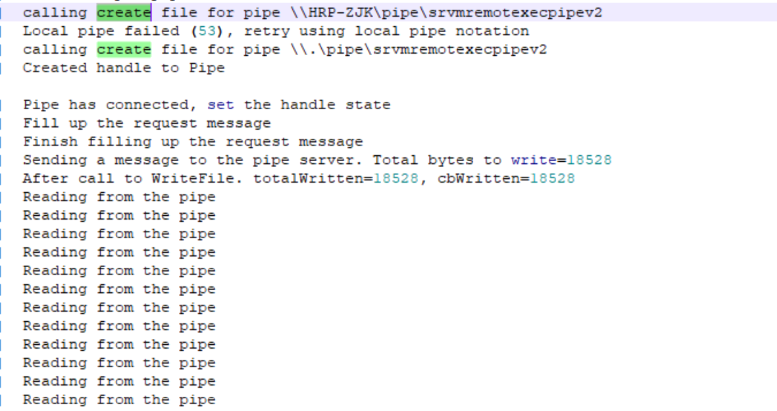

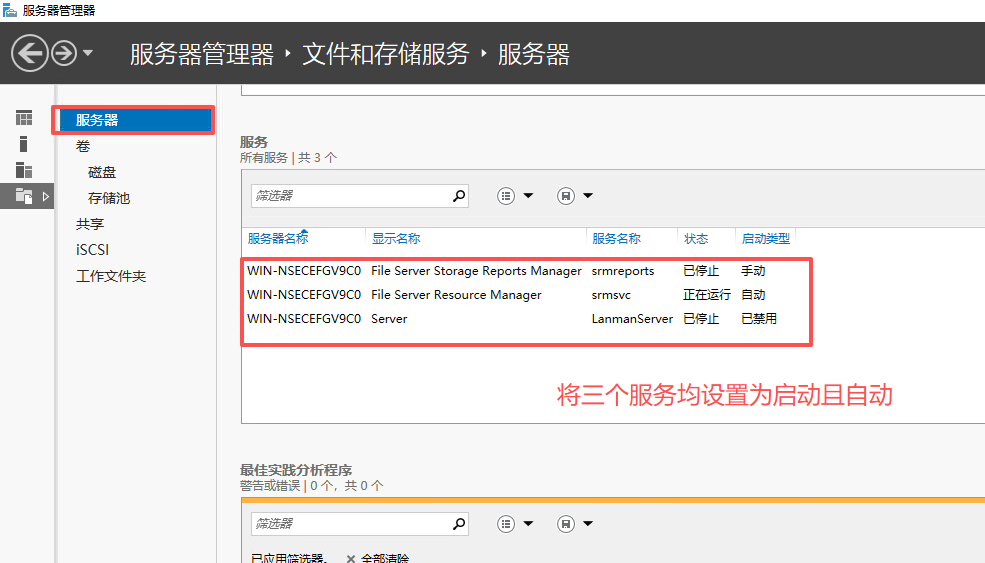
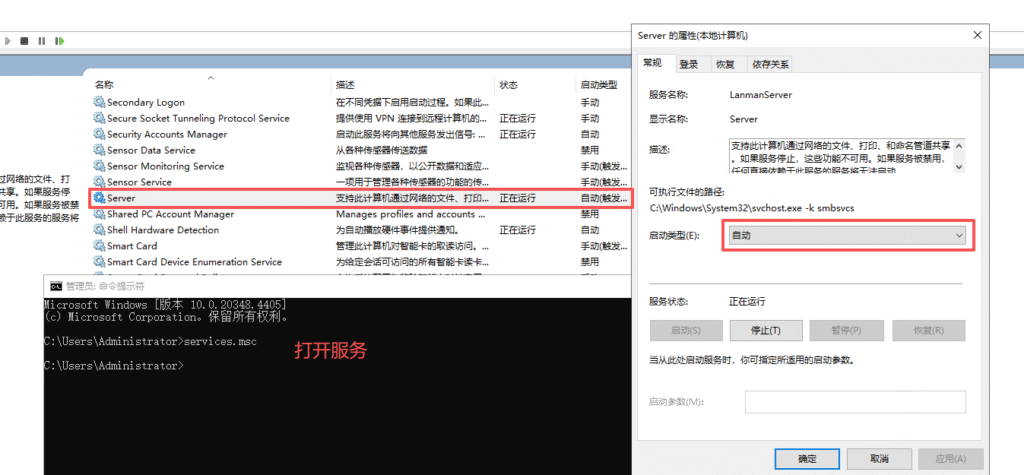
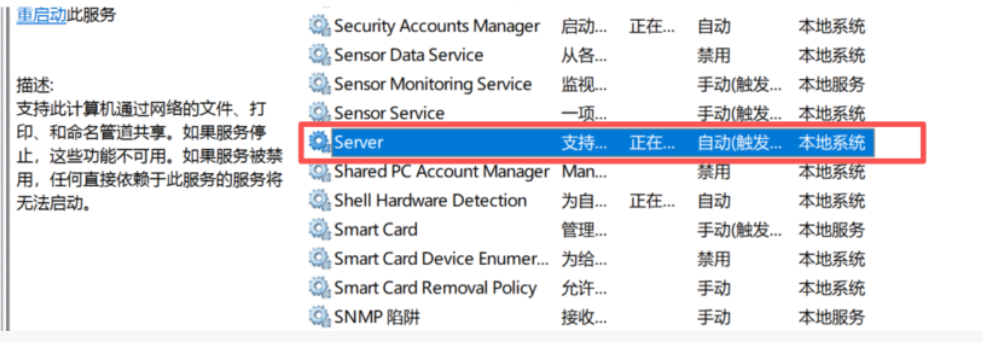
Server服务为未启动 将其设置为自动启动以及启动成功解决
因NBU存储介质使用容量超出了水位线所以备份报错NBU status: 129, EMM status: Insufficient disk space,Disk storage unit is full(129) 又因不备份避免Oracle机器磁盘爆满所以手动删除了物理文件归档
存储介质使用容量阔余后备份依然失败提示(6)User backup failed 是因为删除的物理文件归档没有和控制文件同步造成的
避免Oracle机器磁盘爆满
su – oracle
sqlplus / as sysdba
SQL> archive log list;查看归档路径
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /archived/xxx/x/ 确认归档路径
Oldest online log sequence 177886
Next log sequence to archive 177888
Current log sequence 177888
SQL> exit
(Archive destination USE_DB_RECOVERY_FILE_DEST若路径为默认
exit退出至root用户执行find / -name *.arc可以查看到路径)
cd /archived/xxx/x/进入归档路径
ll -h | more
总用量 7.8G
-rw-r—– 1 oracle oinstall 271M 10月 21 06:40 1_177860_944059067.arc
-rw-r—– 1 oracle oinstall 271M 10月 21 07:09 1_177861_944059067.arc
-rw-r—– 1 oracle oinstall 271M 10月 21 07:32 1_177862_944059067.arc
-rw-r—– 1 oracle oinstall 271M 10月 21 07:44 1_177863_944059067.arc
-rw-r—– 1 oracle oinstall 273M 10月 21 07:53 1_177864_944059067.arc
-rw-r—– 1 oracle oinstall 272M 10月 21 08:01 1_177865_944059067.arc
rm -rf 1_17786*.arc 删除归档
避免NBU备份失败状态码6
正确删除Oracle过期归档日志的方法是:通过RMAN工具依次执行crosscheck archivelog all和delete expired archivelog all命令,确保控制文件与物理文件同步后删除过期记录。
删除过期归档日志的正确方法
操作步骤:
连接到RMAN:
RMAN
connect target /
校验归档日志状态:crosscheck archivelog all检查控制文件与实际文件的差异
删除过期日志:delete expired archivelog all同步控制文件并删除过期记录
命令作用:
crosscheck:扫描归档目录,标记控制文件中已不存在的日志为EXPIRED状态
delete expired:仅删除标记为EXPIRED的日志记录,避免残留无效信息
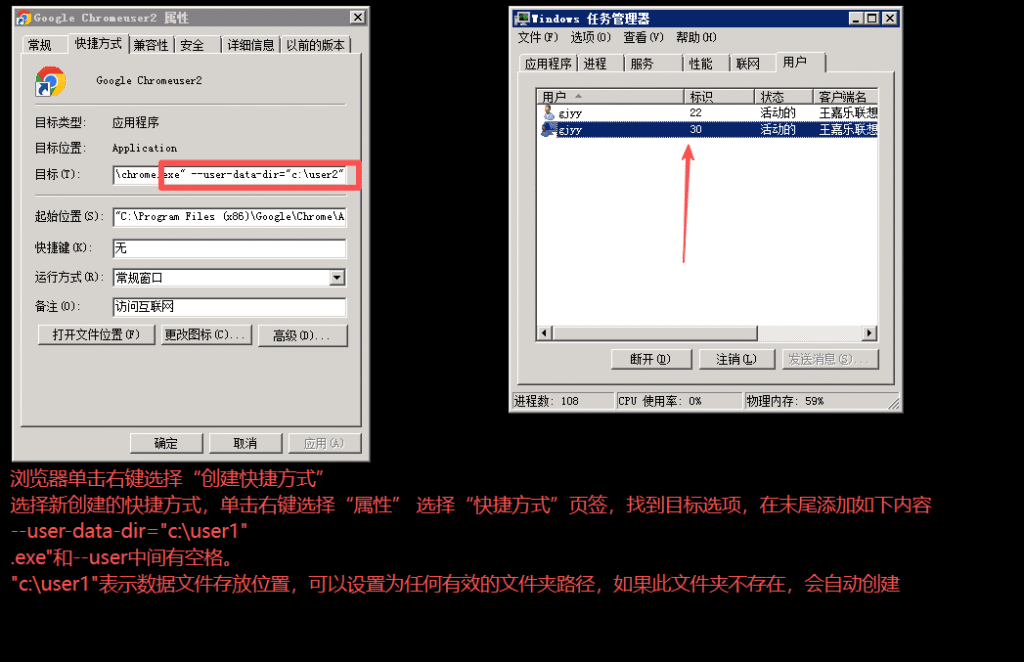
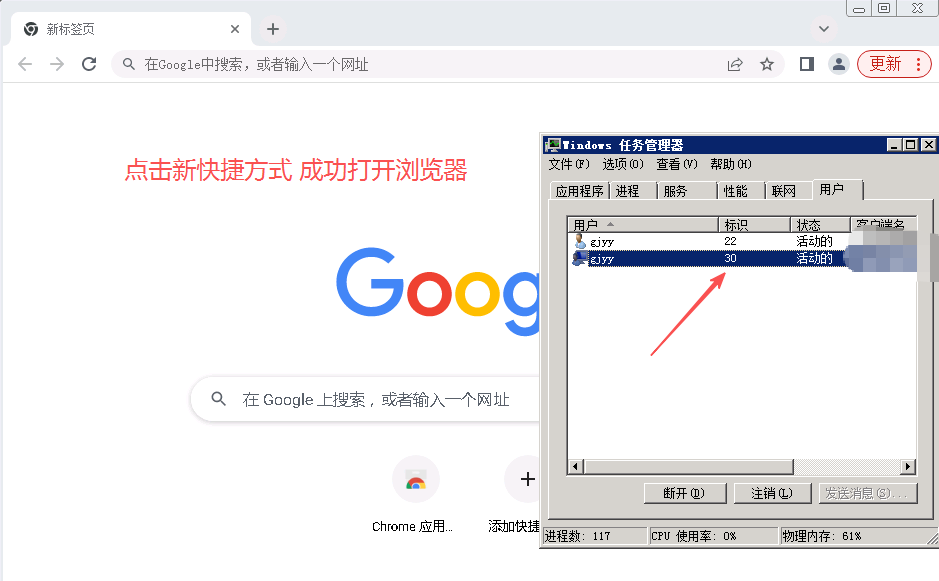
双核浏览器按照此方法设置多开不成功 !!!!
浏览器单击右键选择“创建快捷方式”
选择新创建的快捷方式,单击右键选择“属性” 选择“快捷方式”页签,找到目标选项,在末尾添加如下内容
–user-data-dir=”c:\user1″
.exe”和–user中间有空格。
“c:\user1″表示数据文件存放位置,可以设置为任何有效的文件夹路径,如果此文件夹不存在,会自动创建

set diagnostic 进入可执行 危险复杂命令的诊断模式
row 1
event log show event日志输出
storage failover show 存储容错输出
cluster show 节点输出
alert show 告警输出
system node run -node * -command storage show fault
system node run -node * -command storage show fault -v 存储显示故障详细的
system health subsystem show 系统健康子系统显示
set admin
报错


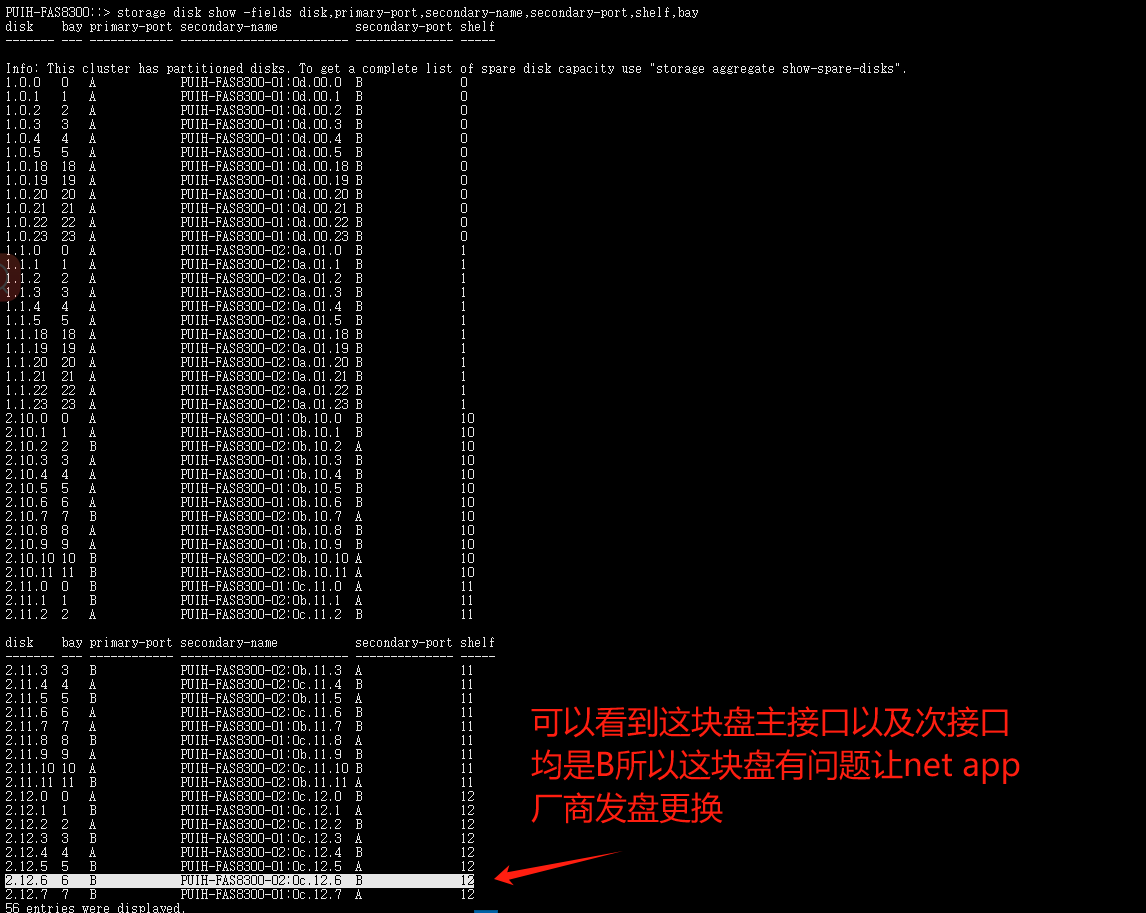
此命令查看失去冗余的磁盘 更换盘后执行此命令看是否恢复冗余
storage disk show -fields disk,primary-port,secondary-name,secondary-port,shelf,bay
disk(磁盘) bay(基座) primary-port(主接口) secondary-name(次要名称) secondary-port(次要接口) shelf(背板)
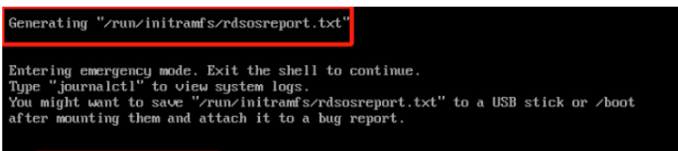
该错误通常是由于文件系统问题导致的
rdsosreport.txt 文件是一种 Linux 系统诊断报告,用于收集系统信息并诊断故障。 它通常是在系统启动时生成的,并可以在 /run/initramfs/ 目录中找到。 该文件可能包含系统配置、硬件信息、已安装的驱动程序、日志等信息。 如果系统出现故障,可以将该文件发送给技术支持人员以进行诊断
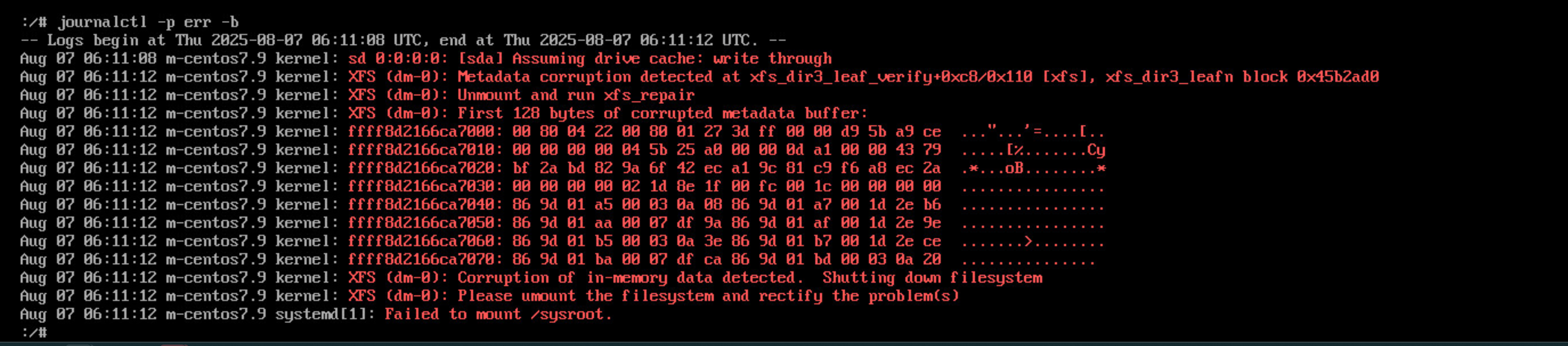
journalctl -p err -b journald是systemd的守护进程,它从系统、内核和各种服务或守护进程多个来源收集日志, 并以二进制格式存储日志,以便于操作。
-f : 实时显示最近的10条日志
-e : 跳转到日志末尾以显示最新事件
-r : 按时间倒序打印日志消息
-k : 只显示内核日志
-u : 只显示指定systemd Unit的消息
-b : 显示来自特定引导的消息,如果不包括特定引导会话,则显示当前引导消息
--list-boots : 显示引导编号(相对于当前引导)、它的id以及与引导有关的第一个和最后一个消息的时间戳
–utc : 以UTC时间表示
-p, --priority= : 按消息优先级过滤输出
-S, --since= : 根据开始时间过滤日志
-U, --until= : 根据结束时间过滤日志
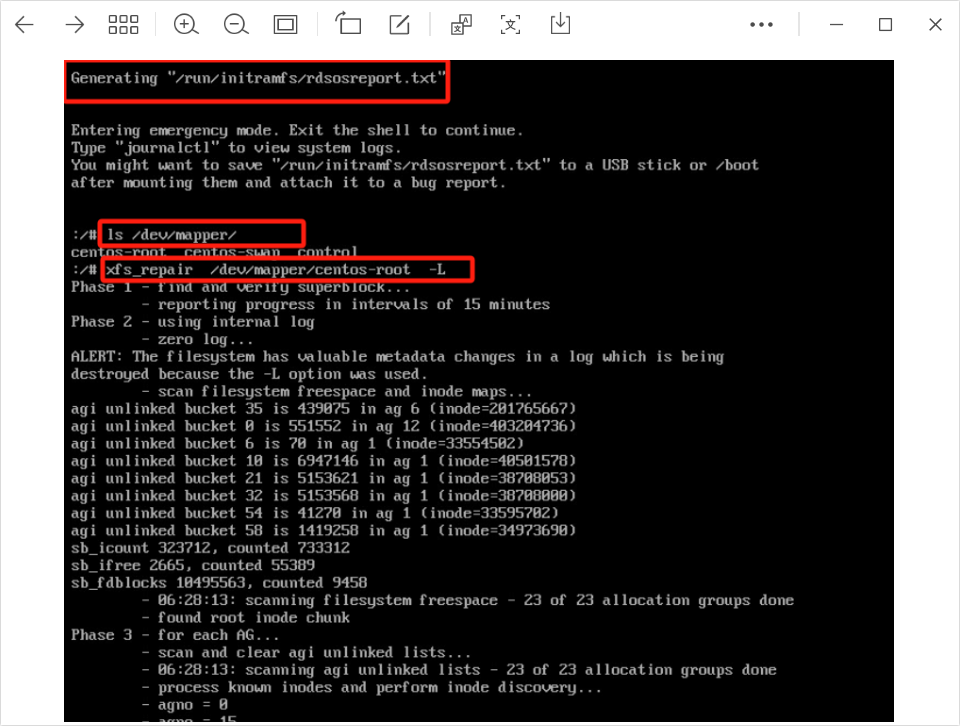
--disk-usage : 显示所有日志文件的当前磁盘使用情况ls /dev/mapper 查找root卷
xfs_repair /dev/mapper/centos-root 修复文件系统
xfs_repair /dev/mapper/centos-root -L 如果不行的话加-L参数(-L:强制日志清零,包括元数据更改)此参数可能会丢失文件系统元数据,生产环境慎用,使用之前先备份元数据
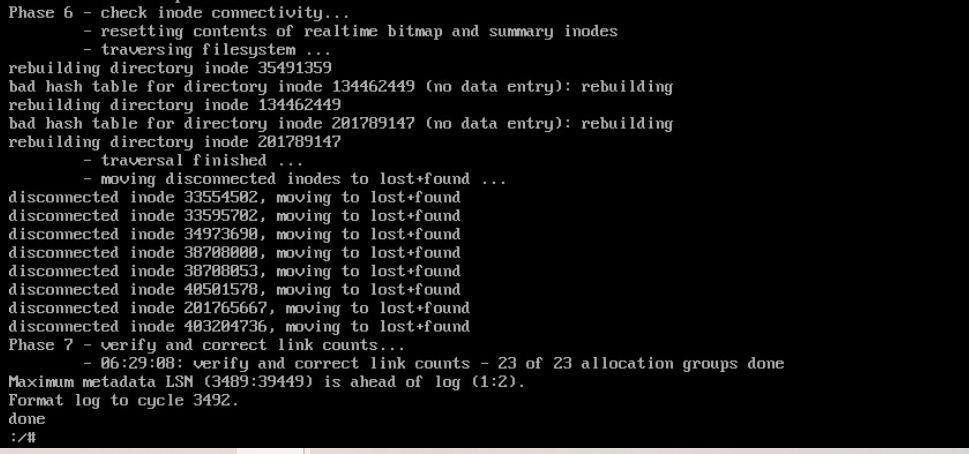
如果修复失败检查打开的文件关闭 卸载卷并再次修复文件系统
lsof | grep /dev/mapper/centos-root
umount /dev/mapper/centos-root
xfs_repair /dev/mapper/centos-root -L
ssh到esxi主机 输入esxcli storage core adapter rescan --all 刷新HBA卡 较慢耐心等待
disk show -broken 查看坏盘
bad label 坏的标签

disk show -v 可以查看到盘所在控制器
system node run FAS3250-DR-KF-02 进入坏盘所在控制器
priv set advanced 进入高级模式

disk unfail -s 4a.41.9 当磁盘因标签损坏或状态异常时,该命令可恢复磁盘的正常状态
priv set 退出高级模式
aggr status -s 查看盘情况拷贝数据中正常状态


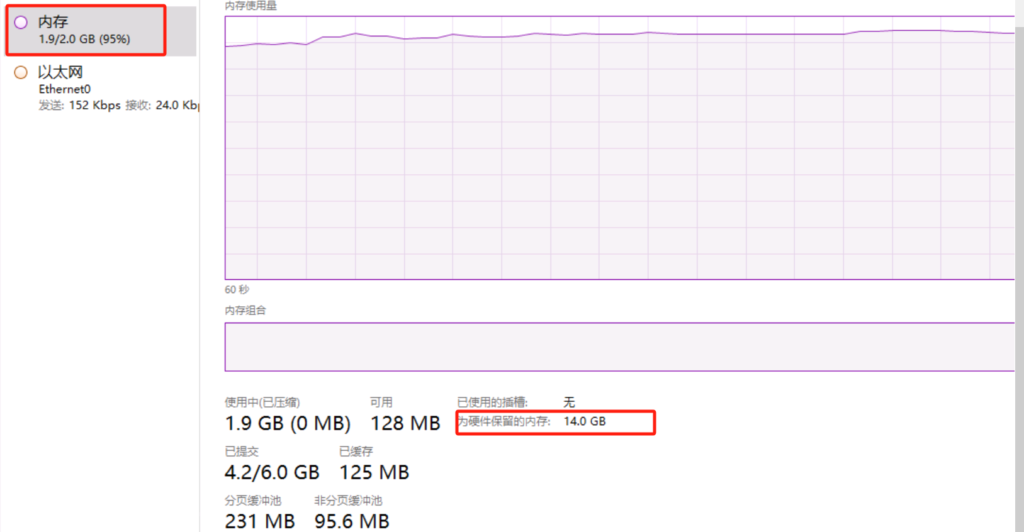
Windows 系统未激活或key不合适 会导致16G内存的机器 只有2G内存可用 为硬件保留的内存14G
cmd输入后重启机器
slmgr /skms kms.chinancce.com
slmgr /ipk WX4NM-KYWYW-QJJR4-XV3QB-6VM33(这是server 2022 datacenter版本的激活码 其他版本的可以参考https://cloud.tencent.com/developer/article/1930066或者自行百度)
slmgr /ato
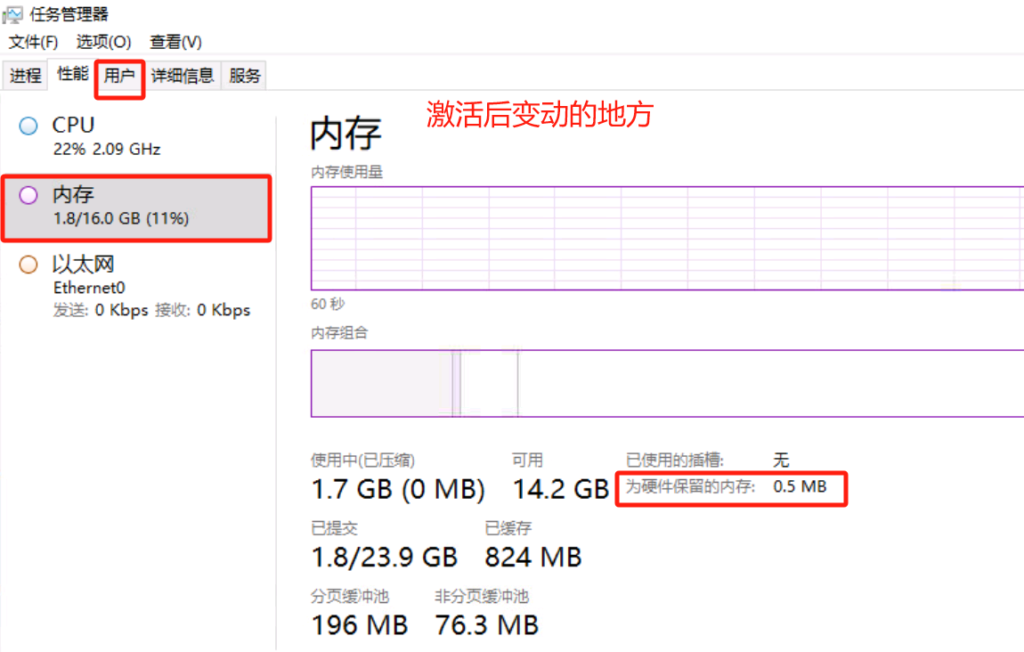
提示还是未激活 但是此问题已解决

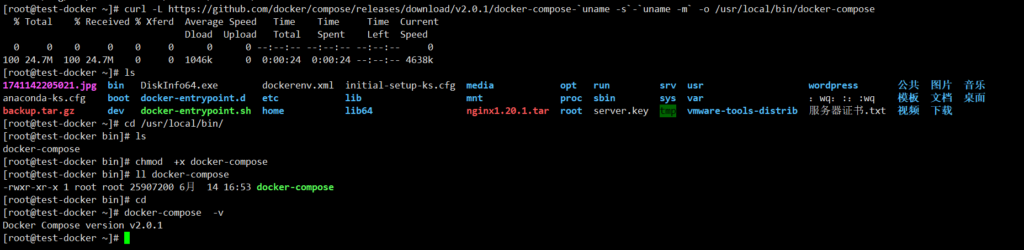
curl -L https://github.com/docker/compose/releases/download/v2.0.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-composecd /usr/local/bin/
ls
chmod +x docker-compose
ll docker-compose
cd
docker-compose -v 验证全局命令没问题
nginx配置文件修改
server_name 若访问IP地址方式那么修改为宿主机IP地址或者nginx容器IP地址均可 若域名访问直接填写域名
fastcgi_pass :9000;修改phpIP地址宿主机IP地址或者php容器IP地址均可
若错误指定IP地址或者文件路径报错404 File not found或者502 Bad Gateway
WordPress /wordpress/wp-config.php修改
/** WordPress数据库的名称 / define(‘DB_NAME’, ”);
/* MySQL数据库用户名 / define(‘DB_USER’, ”);
/* MySQL数据库密码 / define(‘DB_PASSWORD’, ”);
/* MySQL主机 */ define(‘DB_HOST’, ”);
下面截图是wp-config.php中指定DB错误截图 wp-config.php配置文件中修改即可生效
#使用版本2(3版本不支持指令volumes_from)
version: '2'
networks:
lnmp-network:
driver: bridge
ipam:
config:
- subnet: 172.18.0.0/24
gateway: 172.18.0.1#这里即使指定网关是254依然是.1 网上查资料为版本问题
services:
#配置nginx服务
nginx:
#加入到lnmp网络中指定IP地址
networks:
lnmp-network:
ipv4_address: 172.18.0.2
#设置主机名为nginx
hostname: nginx
#指定镜像
image: c8d03f6b8b91
#容器名为nginx
container_name: nginx
#暴露端口80和443
ports:
- 80:80
- 443:443
#将目录挂载到容器内
volumes:
- /nginx:/etc/nginx
- /wordpress:/wordpress
- /var/log/nginx/access.log:/var/log/nginx/access.log
- /var/log/nginx/error.log:/var/log/nginx/error.log
#指定容器时区
environment:
- TZ=Asia/Shanghai
#设置超级用户权限:
privileged: true
#设置容器重启策略nginx服务随nginx容器启动而启动
restart: always
#配置服务mysql
mysql:
networks:
lnmp-network:
ipv4_address: 172.18.0.3
hostname: mysql
image: 5107333e08a8
container_name: mysql
ports:
- 3306:3306
volumes:
- /mysql:/var/lib/mysql
- /my.cnf:/etc/my.cnf
- /var/log/mysql/mysqld.log:/var/log/mysqld.log
- /etc/localtime:/etc/localtime:ro
#指定容器时区
environment:
- TZ=Asia/Shanghai
#设置超级用户权限
privileged: true
#设置容器重启策略
restart: always
#配置服务php
php:
networks:
lnmp-network:
ipv4_address: 172.18.0.4
hostname: php
image: 38f2b691dcb8
container_name: php
ports:
- 9000:9000
volumes:
- /php.ini:/usr/local/etc/php/php.ini
- /wordpress:/wordpress
#php容器需要在nginx和mysql之后启动
depends_on:
- nginx
- mysql
#php和容器nginx,容器mysql连接
links:
- nginx
- mysql
#指定容器时区
environment:
- TZ=Asia/Shanghai
#设置超级用户权限
privileged: true
#设置容器重启策略
restart: always
#在工作目录使用此命令。
#-f: --file-name, 指定模板文件。默认为docker-compose.yml
#-p: --project-name NAME ,指定项目名称,默认使用目录名
#-d: 在后台运行
docker-compose -f /docker-compose/lnmpdockercompose.yaml up -d

访问nginx错误原因是
需要安装PHP的mysql扩展进入到php容器下执行
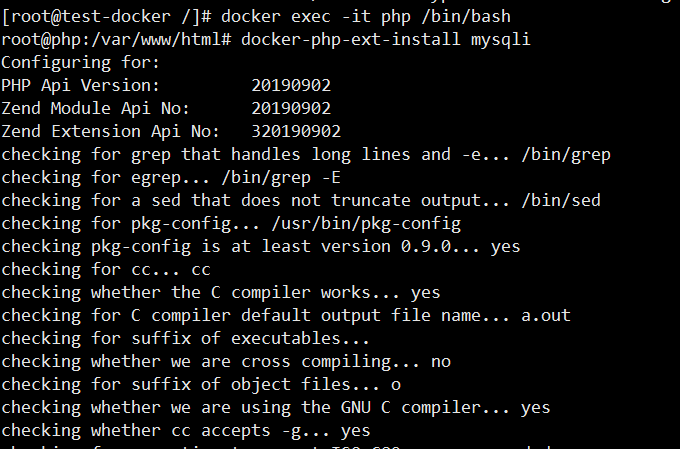
docker-php-ext-install mysqli 安装扩展
php -m 查看是否成功
重启php容器生效

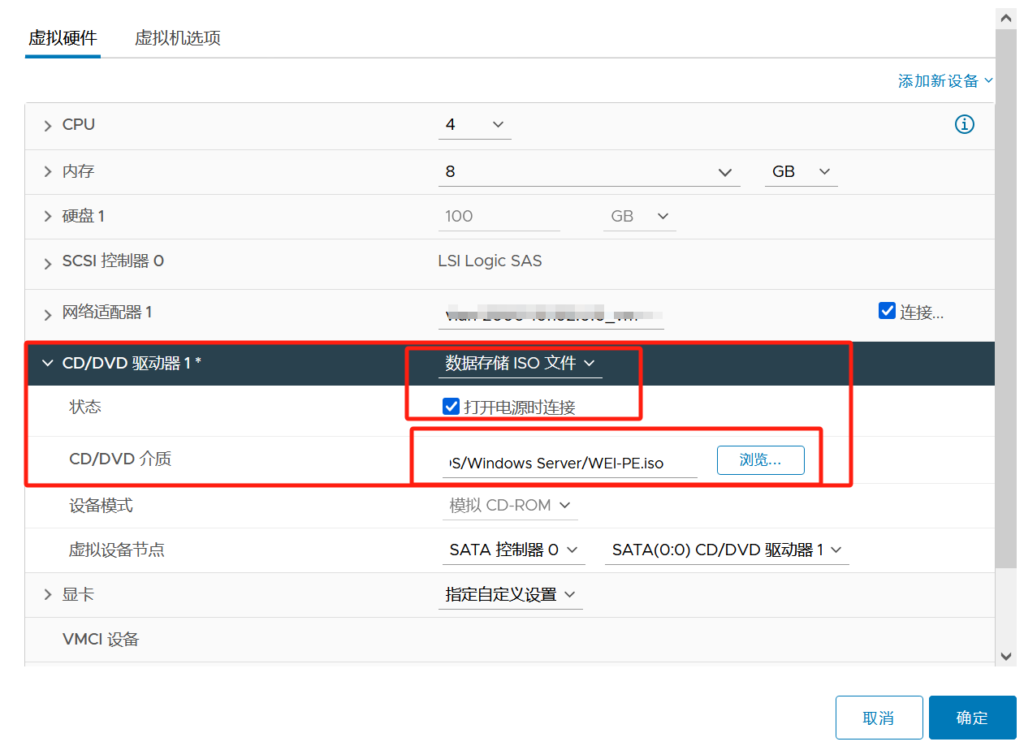
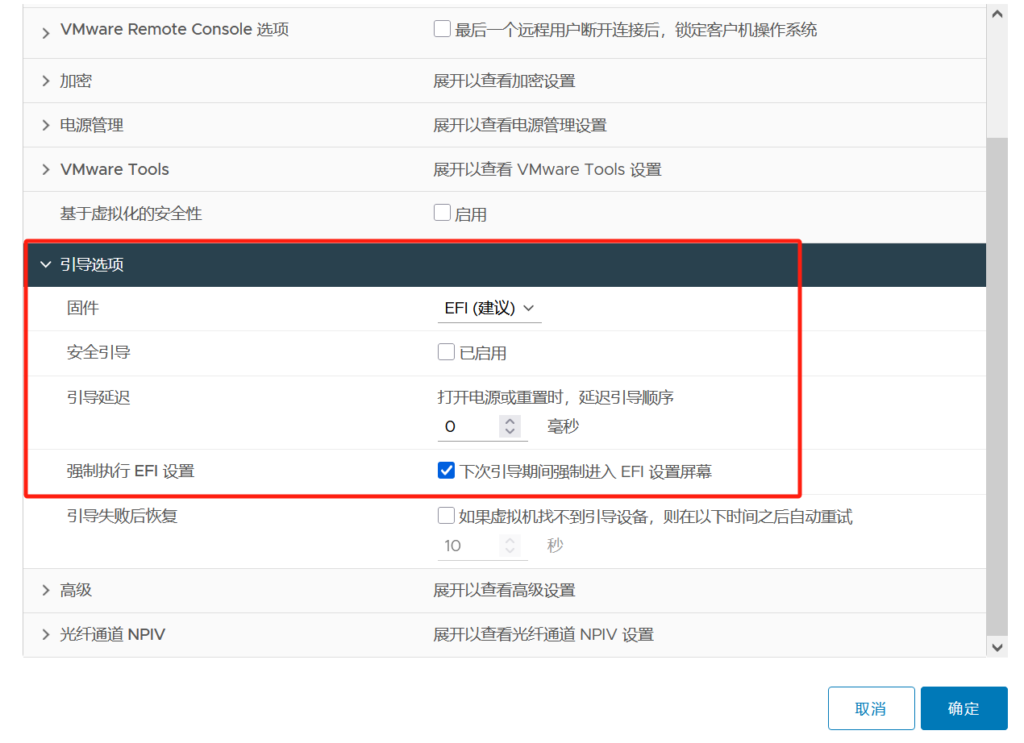
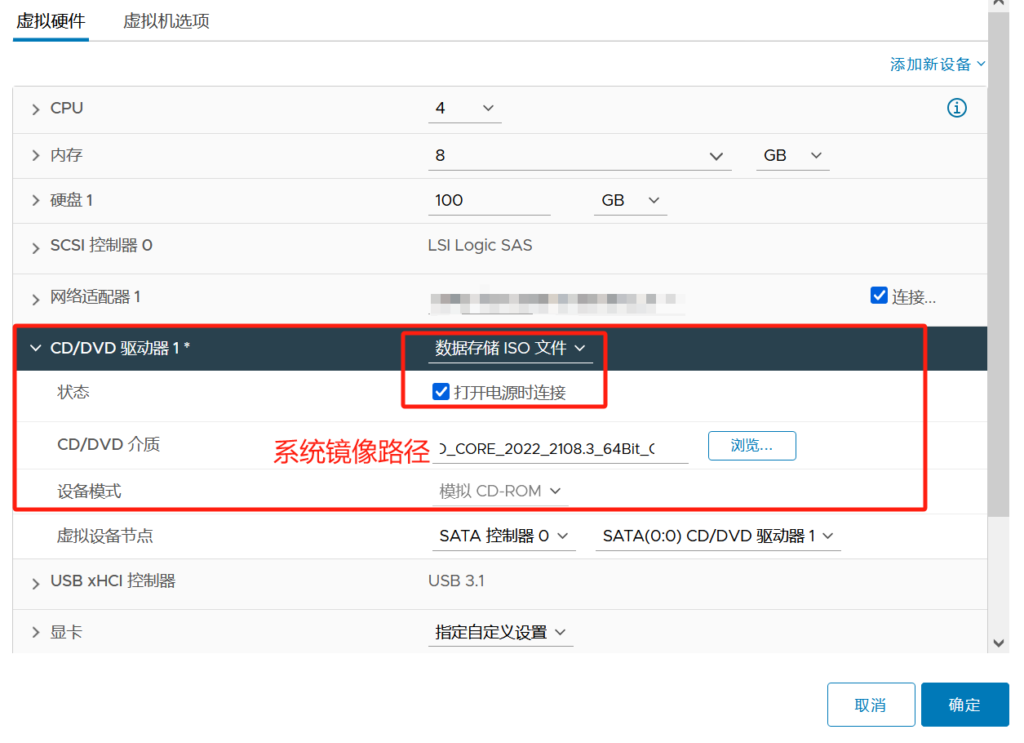
关机挂载镜像以及配置引导
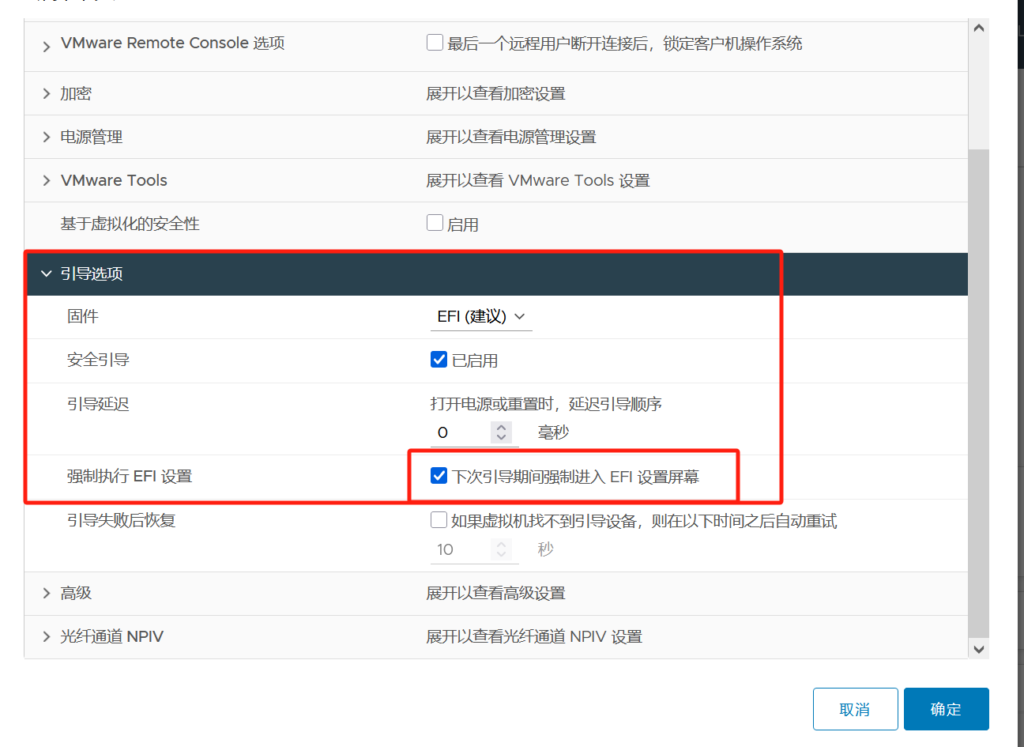
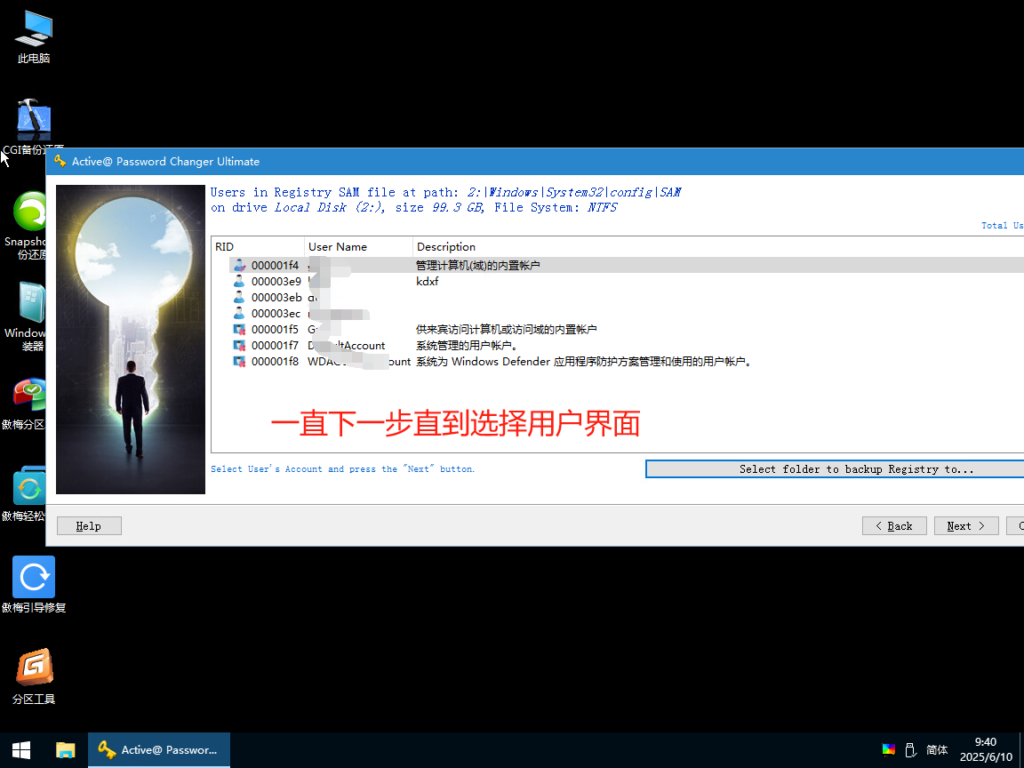
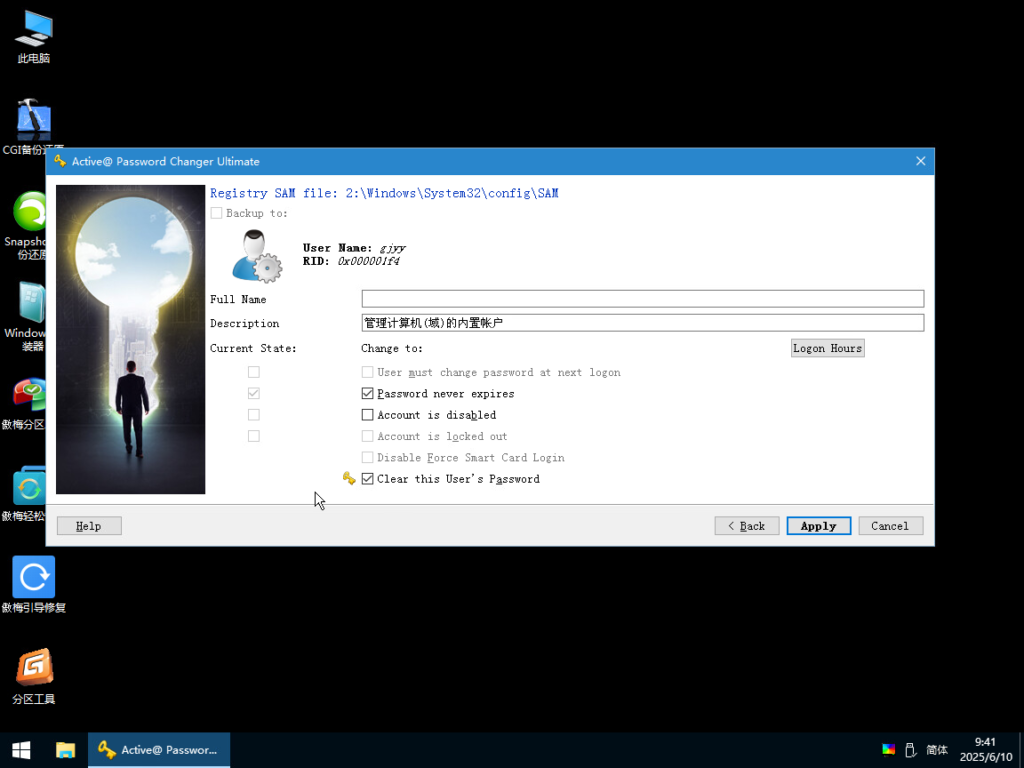
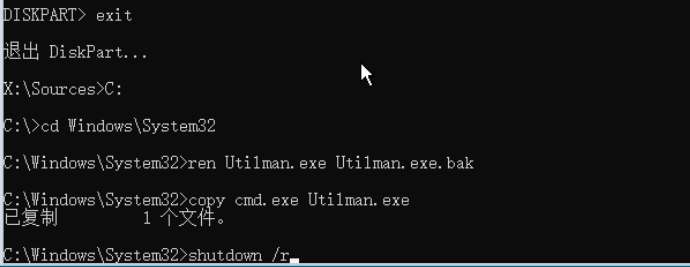
开机自动进入EFI 为将轻松访问Utilman.exe程序暂修改为cmd.exe 进而修改或者清除密码
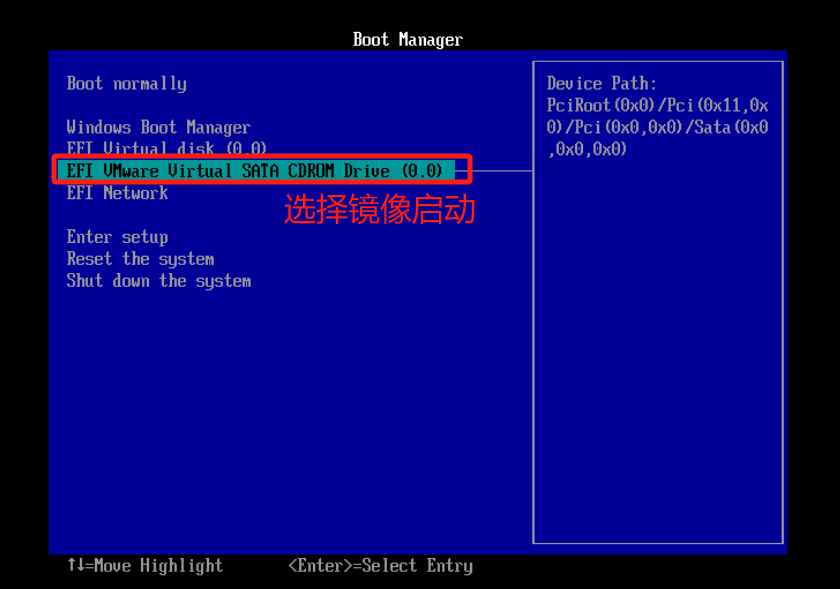

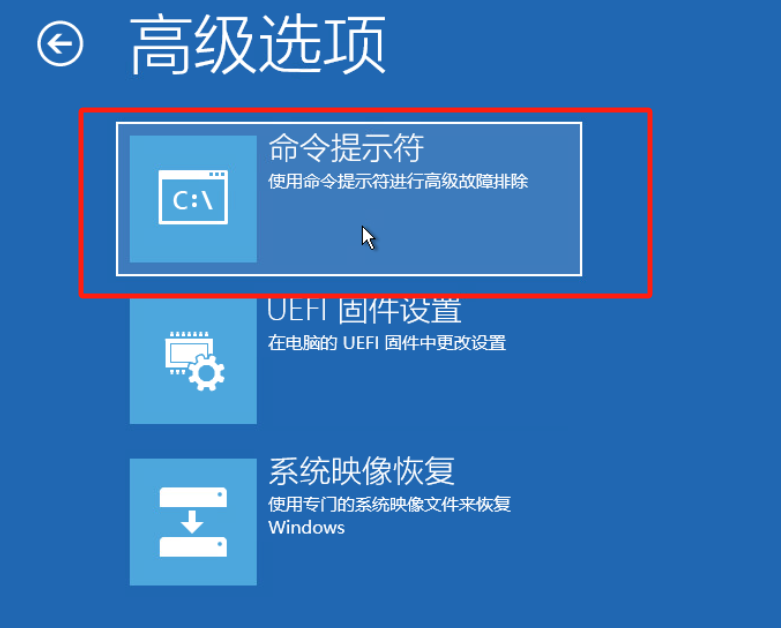
文章结尾命令注释
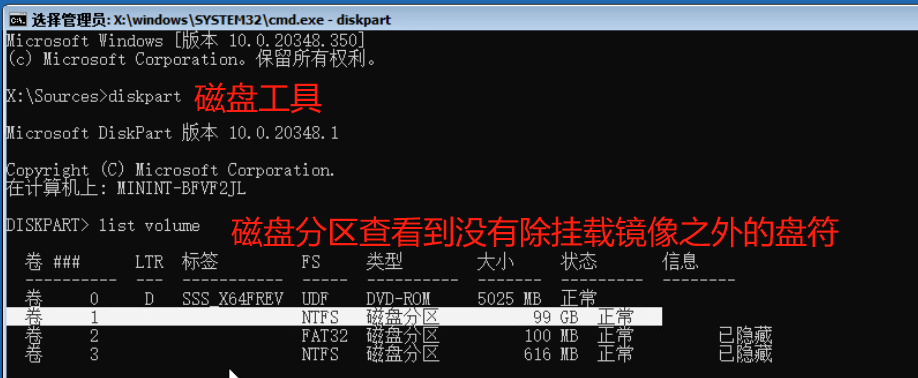
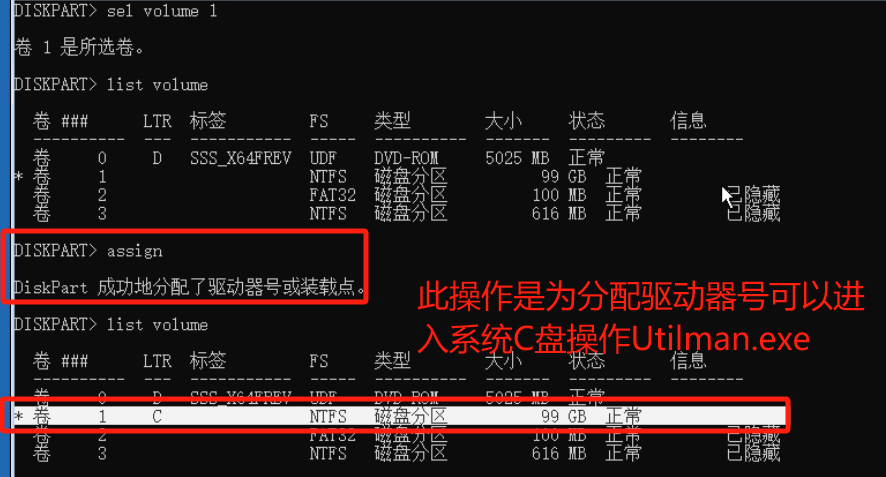



diskpart 磁盘管理
list volume 显示所有卷
sel volume 1 进入卷号1 可以看到1号卷是99G 是系统盘 目的是进入系统盘打开cmd修改密码
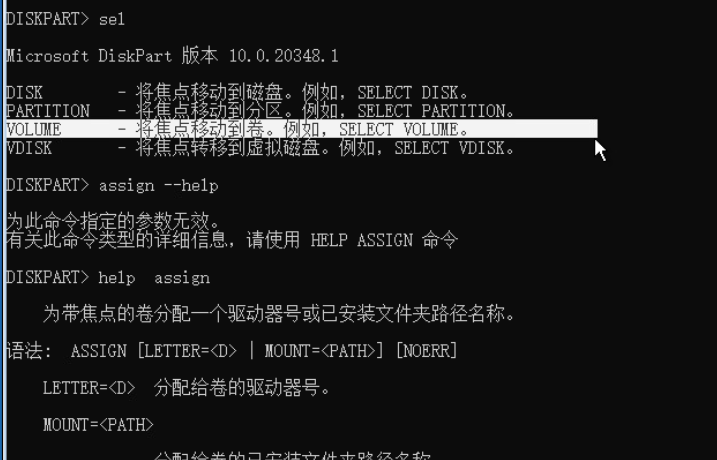
assign 分配驱动器号可以cd进入C盘
exit 退出diskpart
C: 进入C盘
cd windows\System32 进入目录
ren Utilman.exe Utilman.exe.bak 重命名Utilman.exe为Utilman.exe.bak
copy cmd.exe Utilman.exe 复制cmd.exe为Utilman.exe
点击登录屏幕上的轻松访问图标可以启动Utilman.exe 上面操作 将密码输入界面的辅助功能按钮对应程序utilman.exe更改为终端命令框程序cmd.exe
通过命令提示符更改账户密码,仅对于系统盘没有设置 BitLocker 的电脑有效(一般家用电脑都可使用此教程)
shutdown /r 立即重启
打开cmd后
net user 查看存在用户
net user administrator “密码”
正常进入系统
还原Utilman.exe文件
copy Utilman.exe.bak Utilman.exe
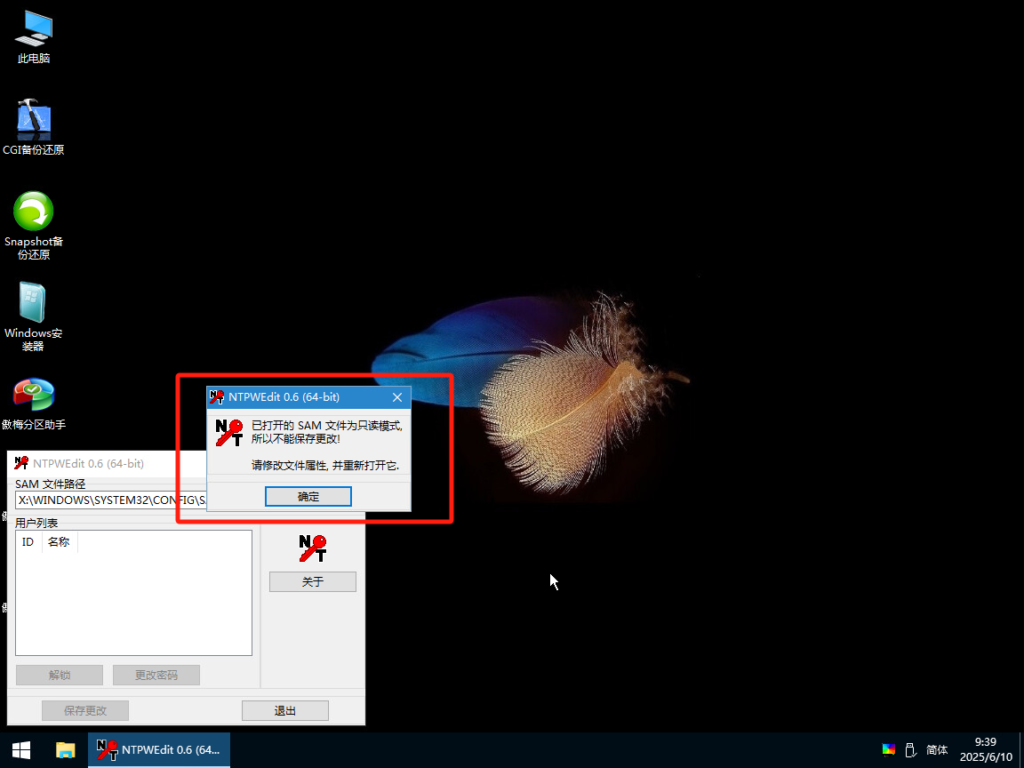
若修改不成功应该是系统安装了第三方加密进入PE修改密码如下链接
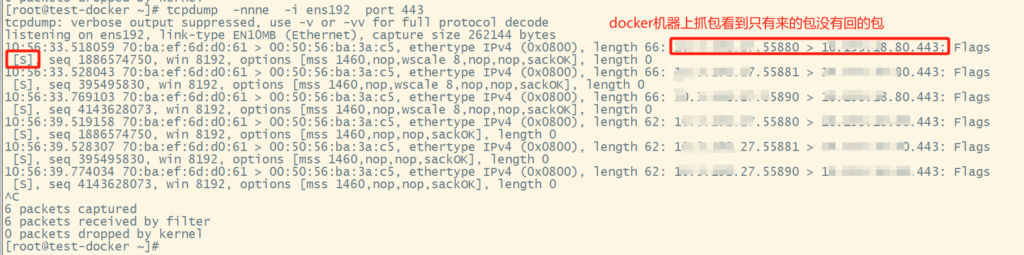
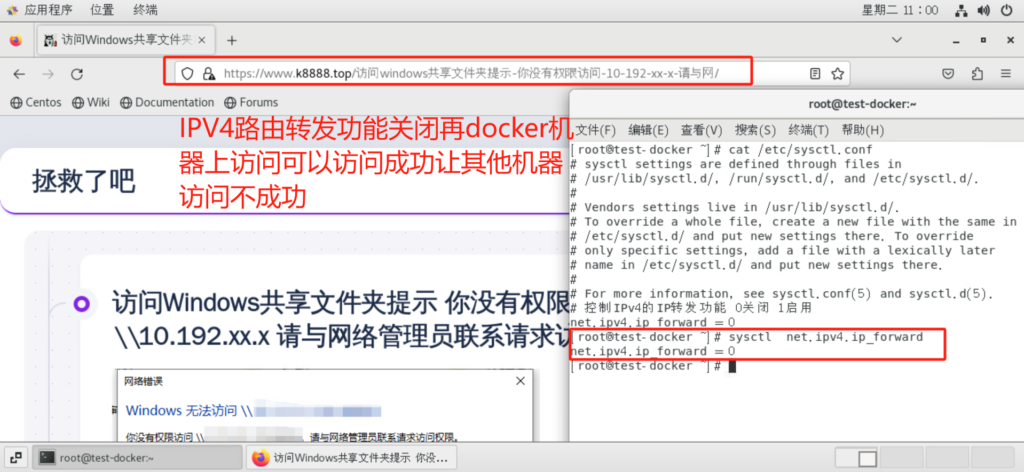
访问docker容器nginx不成功,查看docker服务以及容器均正常 tcpdump命令抓包看到是本机没有回包。宿主机重启后发现访问docker nginx容器依然不成功,手动重启docker服务后解决。
查百度发现是net.ipv4.ip_forward内核参数原因
参考链接:https://www.cnblogs.com/eeexu123/p/16130683.html
https://www.cnblogs.com/minimeta/p/16482234.html
当容器不可访问时 IP_FORWARD功能处于停用状态!
Docker daemon服务在启动过程中会检查系统的IP_FORWARD配置项,如果当前系统的IP_FORWARD功能处于停用状态,会帮我们临时启用IP_FORWARD功能,然而临时启用的IP_FORWARD功能会因为其他各种各样的原因失效…
net.ipv4.ip_forward 是一个内核参数,用于控制IPv4的IP转发功能 当你将这个参数设置为0时,系统将不会转发接收到的IP包到其他网络接口 参数设置为1时 系统将会转发接收到的IP包到其他网络接口
临时开启关闭IPv4的IP转发功能
启用:sysctl -w net.ipv4.ip_forward=1
关闭:sysctl -w net.ipv4.ip_forward=0
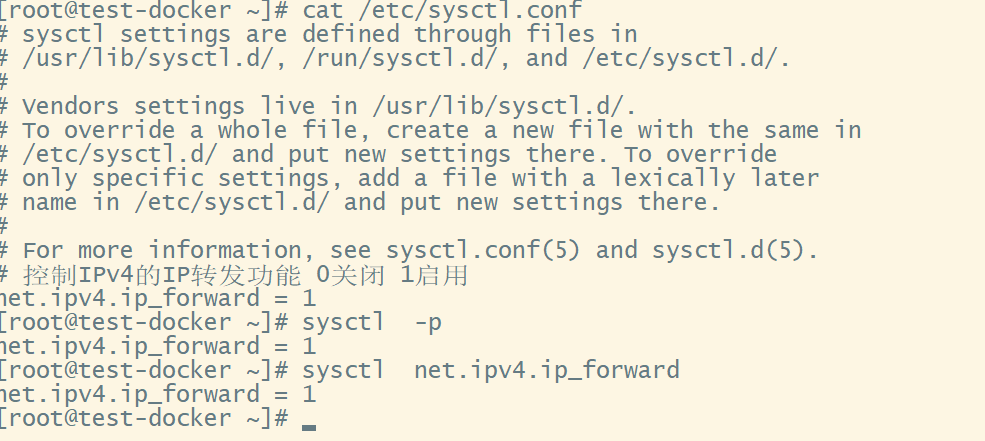
永久开启关闭IPv4的IP转发功能
vim /etc/sysctl.conf
net.ipv4.ip_forward = 1 # 启用IPV4转发
net.ipv4.ip_forward = 0 # 禁用IPV4转发
保存退出后sysctl -p 让其更改立即生效
sysctl net.ipv4.ip_forward 查看该参数状态
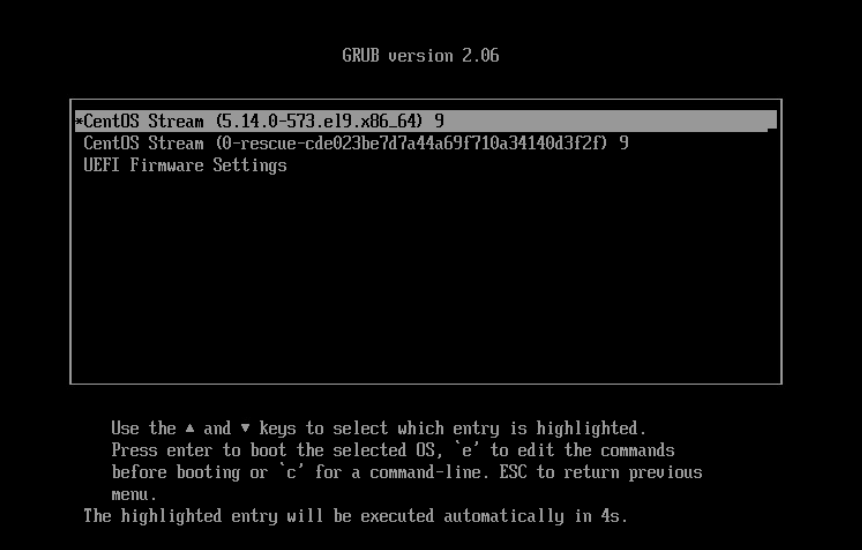
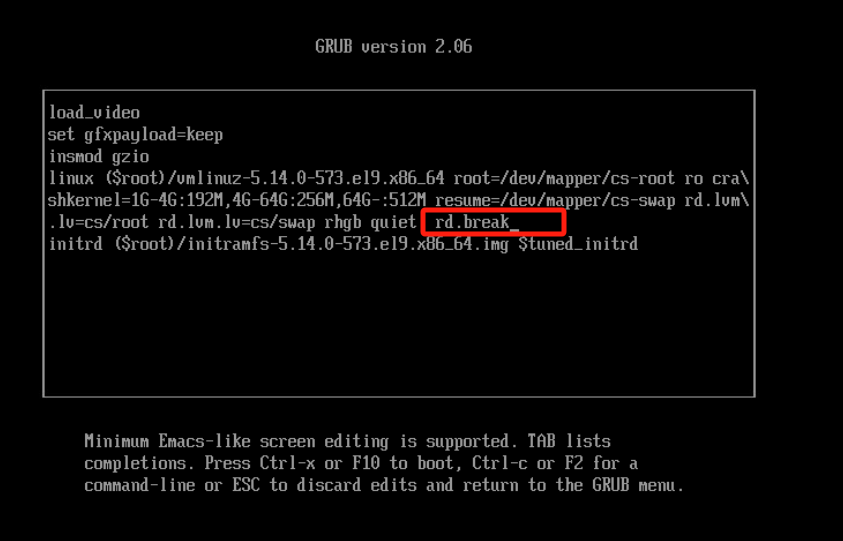
1、重启系统
2、GRUB菜单 默认的启动项 通常是第一个选项
3、按下E键进入编辑模式
4、修改启动参数 在该行末尾添加以下内容 rd.break 按下Ctrl+X或F10键启动系统,并进入救援模式
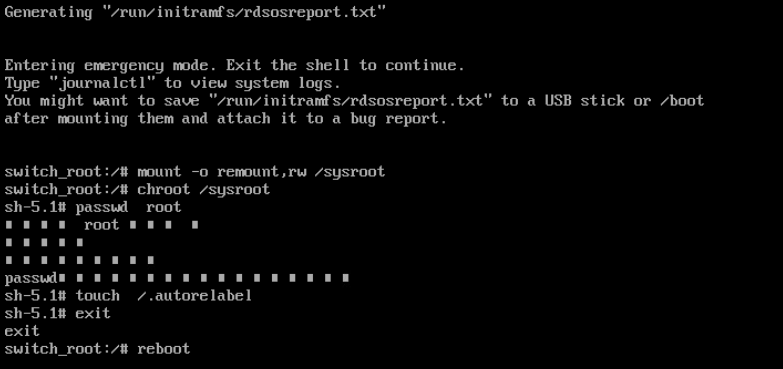
5、挂载根文件系统 系统进入救援模式后,你将看到命令提示符(类似 switch_root:/#) 重新挂载根文件系统,以读写模式挂载 mount -o remount,rw /sysroot
6、切换到实际的根文件系统 chroot /sysroot
7、重置root密码 passwd root
8、SELinux可能会阻止新的密码文件生效,你需要执行以下命令来更新SELinux上下文 touch /.autorelabel
9、命令退出chroot环境 exit 重启系统验证 reboot
pagefile.sys是虚拟内存页面文件,如果计算机在较低的内存下运行(查看到内存使用率94%),在打开大型文件时需要内存不足时,Windows 就会用部分硬盘空间代替内存。这就是虚拟内存。
pagefile.sys文件一般是C盘下的隐藏文件,此文件也会占用较大的存储位置,其大小是系统依据当前所使用的虚拟内存大小来决定的,你开启的软件程序越多,这个文件就越大。如果我们设置的虚拟内存是1G-2G,那么我们看到的pagefile.sys文件则是1G。
一般情况下pagefile.sys是没有办法删除的,只要我们设置虚拟内存,它就会一直存在。虚拟内存的设定对于自己计算机的性能在一定程度上面是有好处的。所以这里建议大家还是保留虚拟内存。如果内存足够大,硬盘资源紧张的话想要将其删除,通过修改虚拟内存的设置可以删除它。
扩容内存资源
1、右击桌面此电脑图标,选择属性
2、点击左上方的高级系统设置
3、打开系统属性窗口,点击性能的设置按钮
4、新的窗口中,点击高级选项下的更改按钮,取消第一行的自动管理所有驱动器的分页文件大小,选择无分页位文件,点击设置,确定即可 重启服务器
1、右击桌面此电脑图标,选择属性
2、点击左上方的高级系统设置
3、打开系统属性窗口,点击性能的设置按钮
4、新的窗口中,点击高级选项下的更改按钮,取消第一行的自动管理所有驱动器的分页文件大小,选择无分页位文件,点击设置
5、点击其他盘,选择系统管理的大小>>设置>>确定即可 重启服务器文件转移成功。
定期自动清理FTP目录下的数据
经验证 del 命令只是删除所有文件和子文件夹中的文件 rd命令删除整个文件夹及其所有内容(这样会把顶级文件夹删除)
FTP开启了用户隔离且局限于用户名目录 若将用户名目录也就是顶级文件夹删除那么对应FTP账号登录不成功
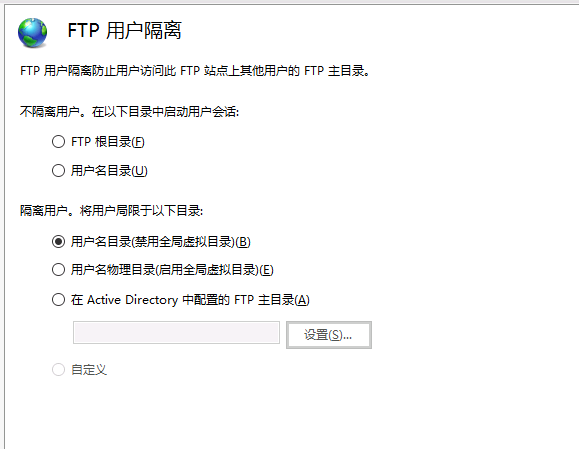
所以用powershell方式来定期清理目录下的数据@echo on 命令的作用是使得接下来的命令在执行前都会被打印出来,包括命令本身和其执行结果
start cmd
powershell rm -r C:\FTP\localuser\user1\*
powershell rm -r C:\FTP\localuser\user2\*
powershell rm -r C:\FTP\localuser\user3\*
powershell rm -r C:\FTP\localuser\user4\*
powershell rm -r C:\FTP\localuser\user5\*
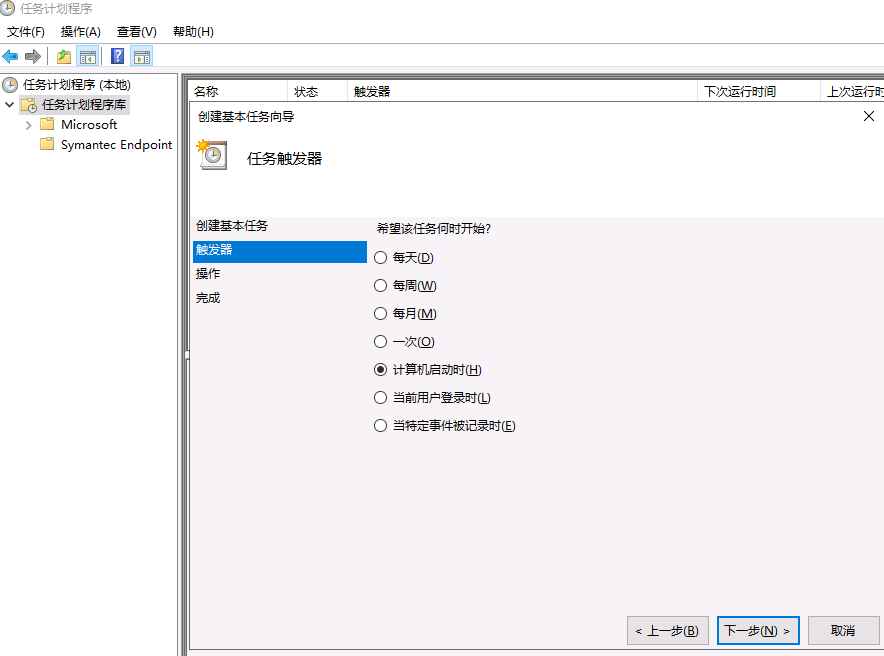
将bat文件加入到任务计划开启定期清理FTP用户目录下的数据
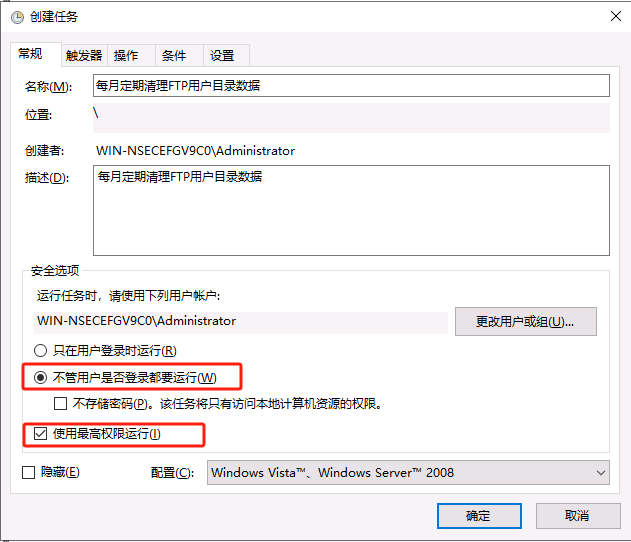
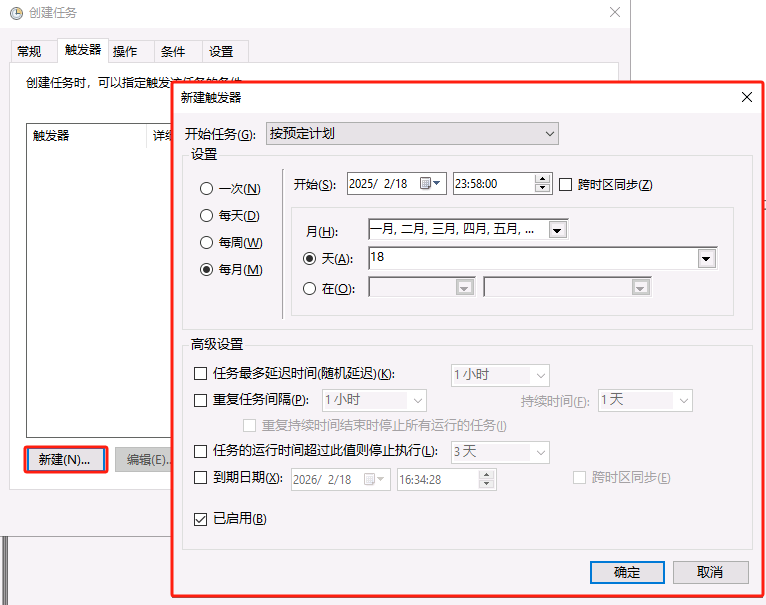
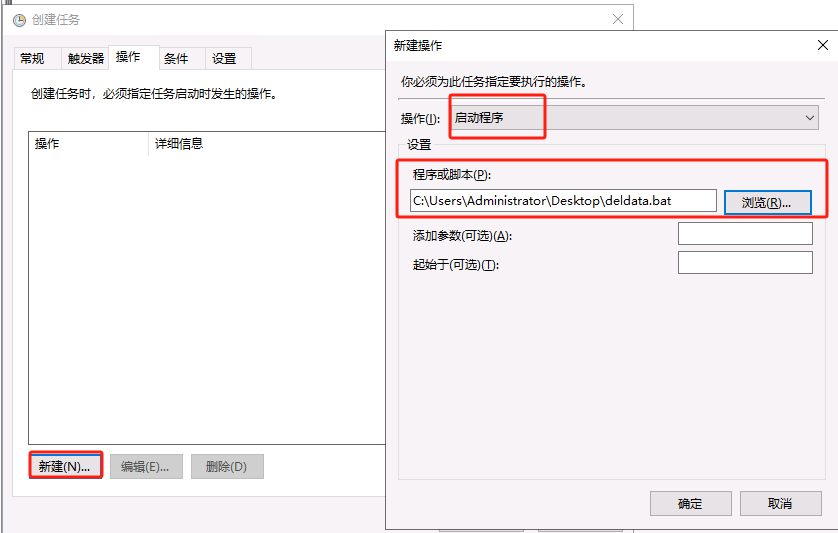
最后点击确定会提示输入管理员密码
在user目录下新建文件夹以及文件 运行此任务验证成功删除
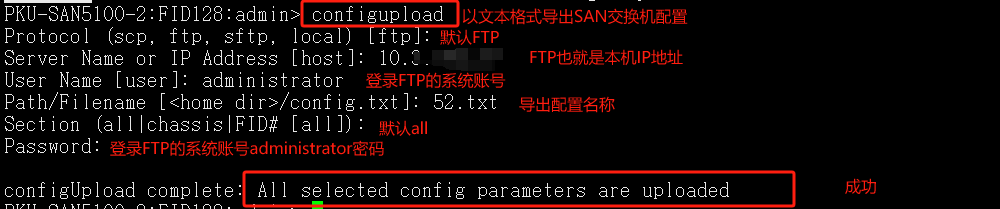
导出SAN交换机配置到2008R2 服务器
参考链接:https://wenku.baidu.com/view/642db9fc482fb4daa48d4b53.html?_wkts_=1736989616551&bdQuery=san%E4%BA%A4%E6%8D%A2%E6%9C%BA%E9%85%8D%E7%BD%AE%E5%AF%BC%E5%87%BA
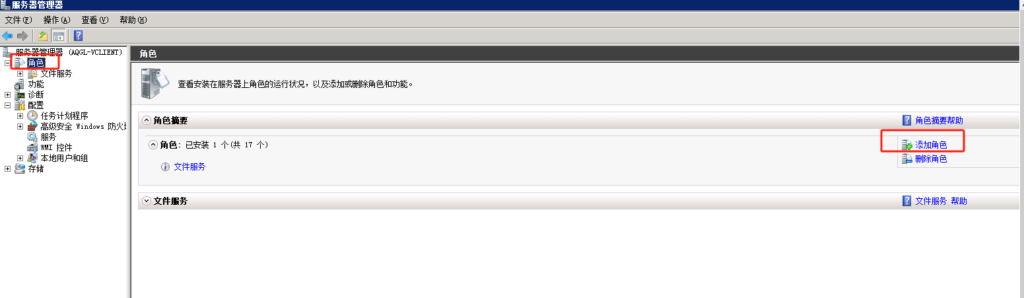
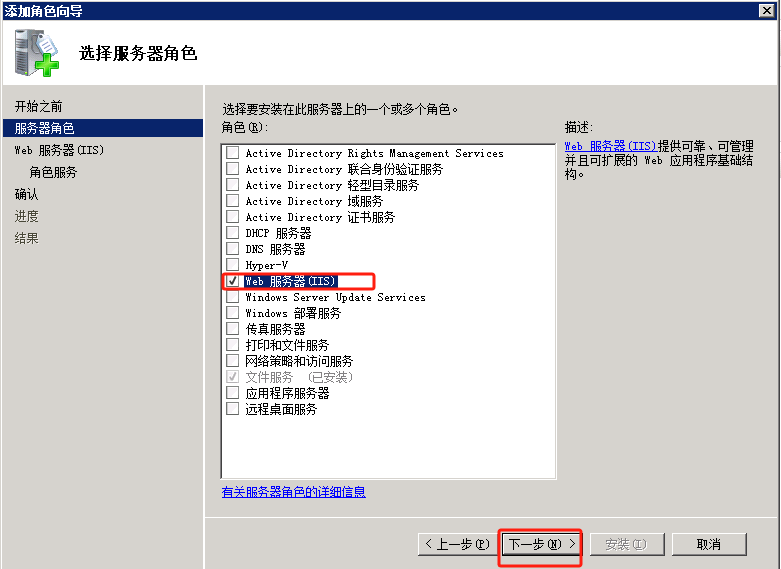
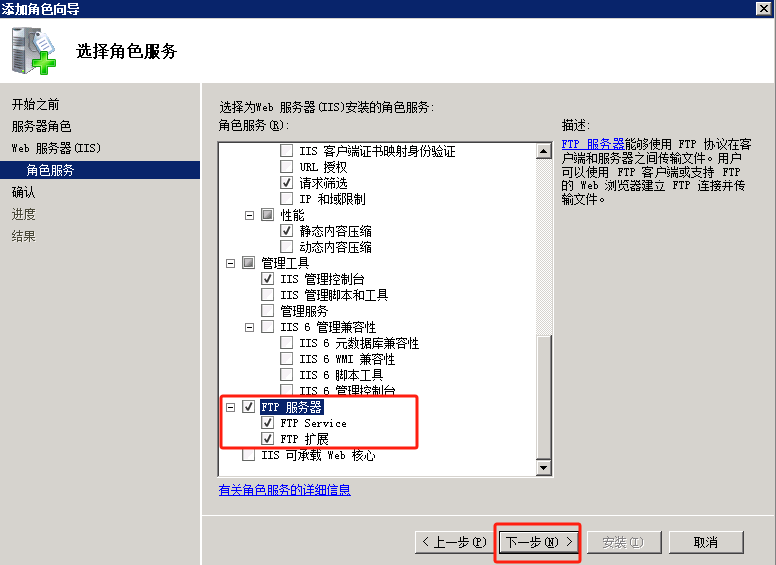
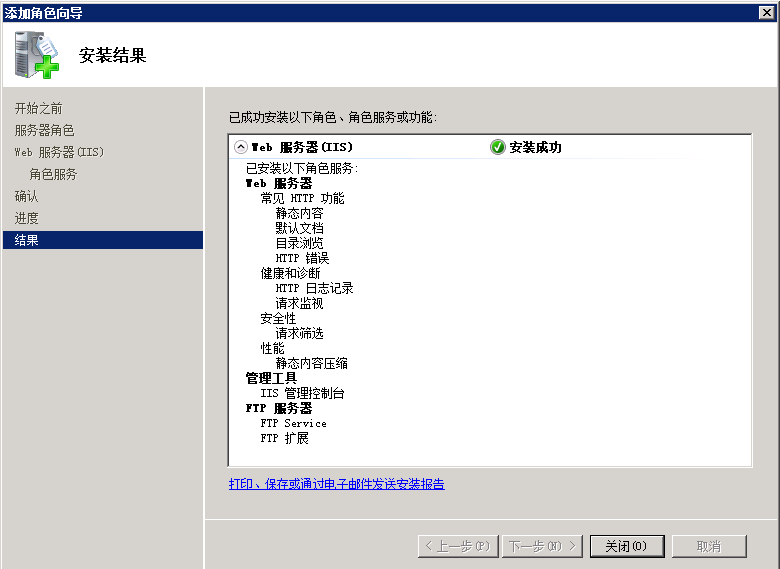
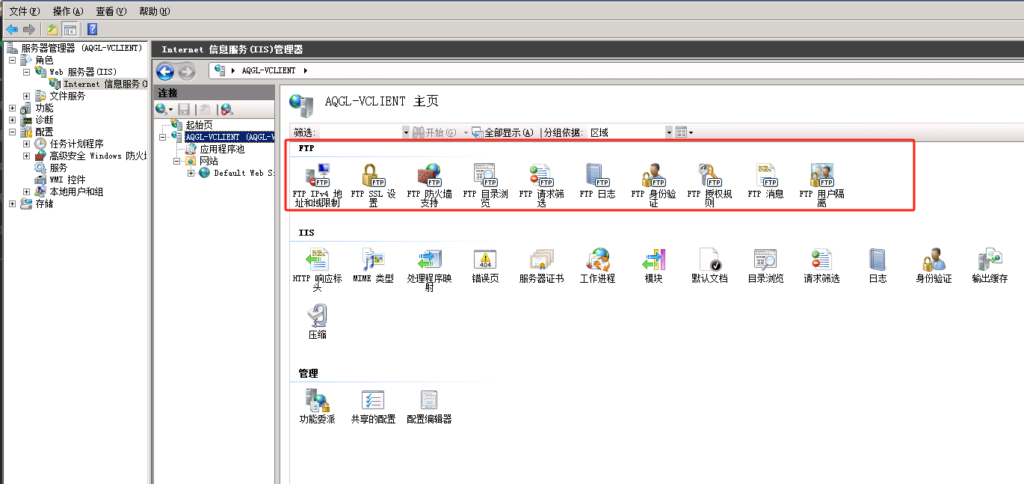
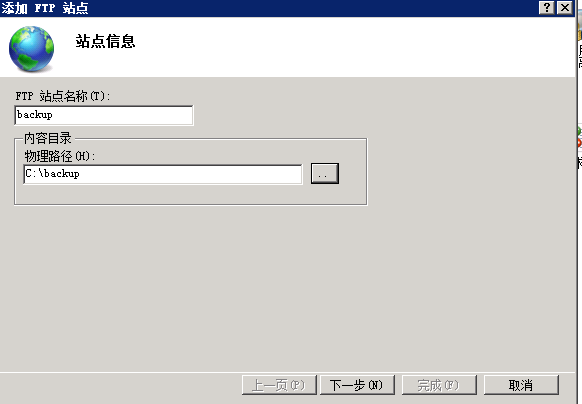
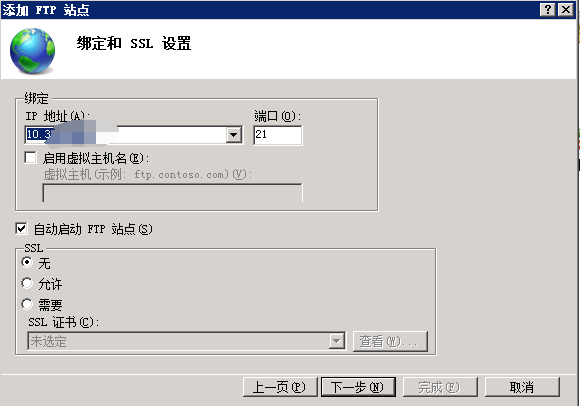
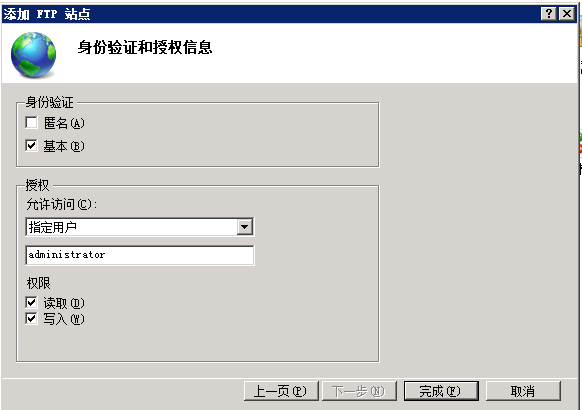
配置导出 到 FTP站点目录
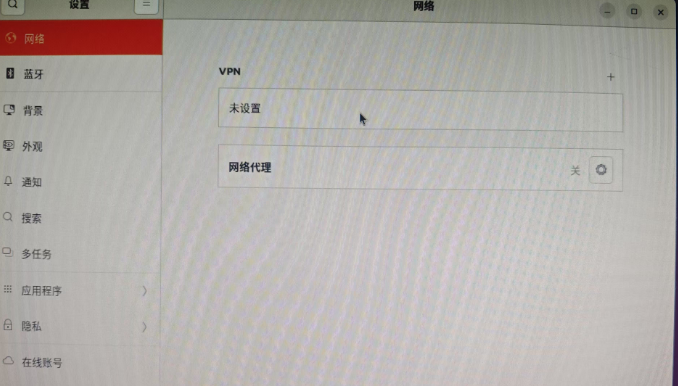
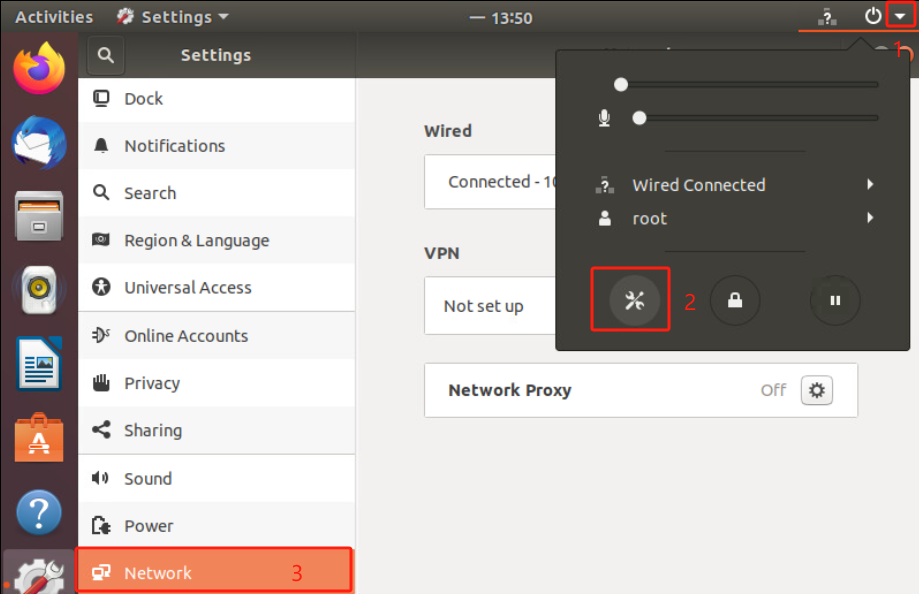
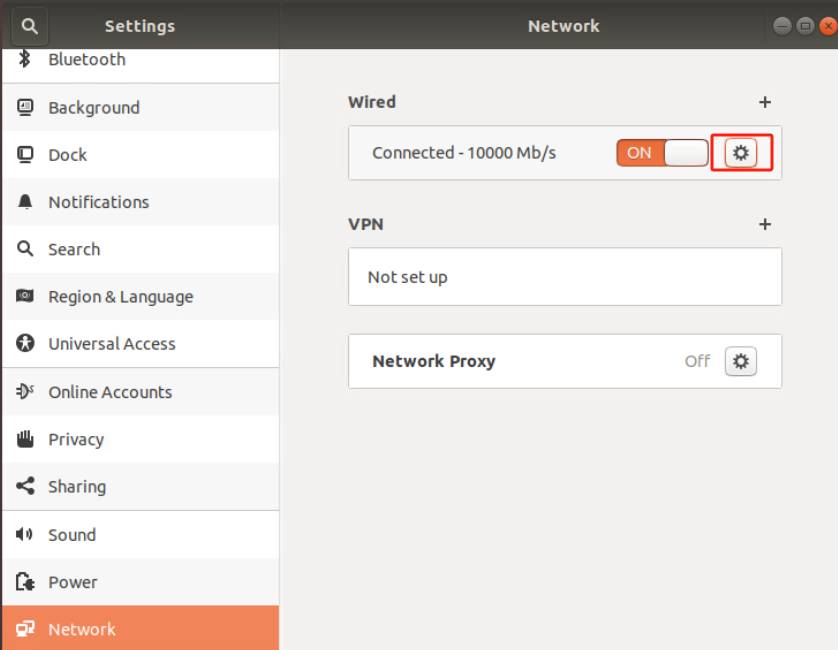
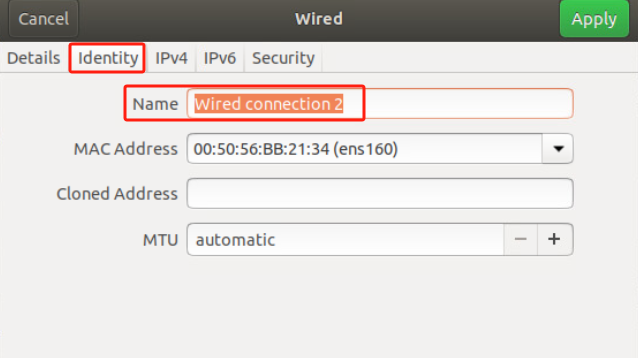
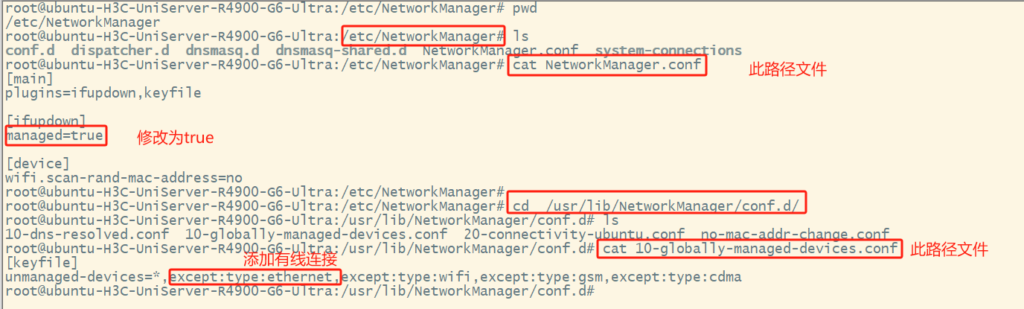
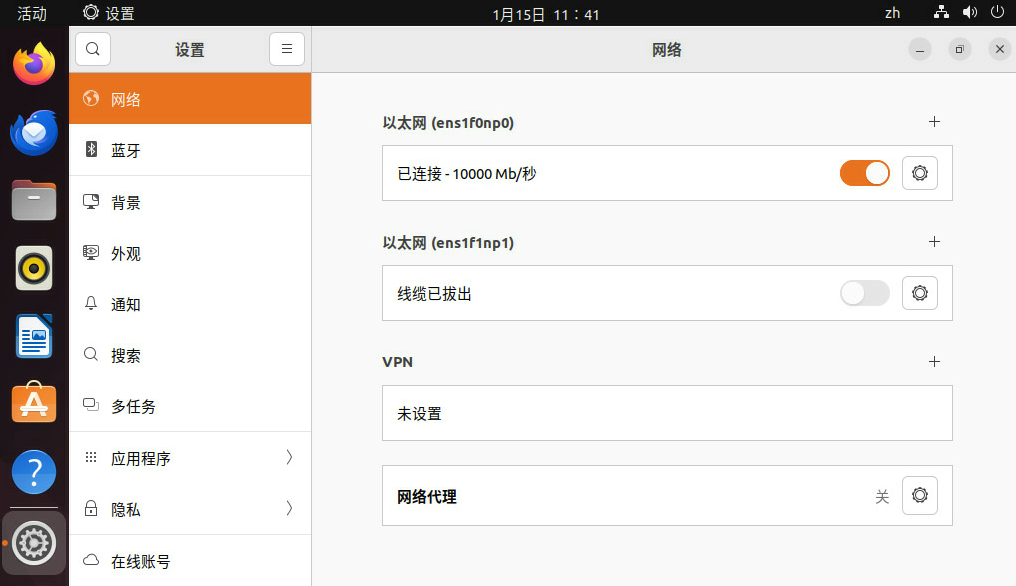
安装Ubuntu系统重启后发现 图形界面设置>网络选项看不到有线连接 但是命令行ip a可以看到网卡 但无IP地址 网络依然不正常 (同一个镜像别的机器没这个问题纳闷)
设置/etc/NetworkManager/NetworkManager.conf配置文件中的managed=true
/usr/lib/NetworkManager/conf.d/10-globally-managed-devices.conf配置文件中添加except:type:ethernet,
重启机器后正常
参考链接:https://developer.aliyun.com/article/1314180
docker network create –subnet 172.18.0.0/24 –gateway 172.18.0.254 –driver bridge wangjiale-network
指定网段–subnet 172.18.0.0/24
指定网关–gateway 172.18.0.254
网络类型:–driver bridge
网络名字 wangjiale-network
存储卷:
存储卷是Docker管理的,独立于容器生命周期的。
存储卷数据可以被多个容器共享。
存储卷数据默认存储在宿主机的 /var/lib/docker/volumes/ 目录下。
通常提供更好的性能,尤其是在Docker Desktop上相比于Mac和Windows宿主机上的Bind Mount。
需要额外docker volume create my_volume
绑定挂载:
绑定挂载将宿主机上的文件或目录直接挂载到容器内部。
绑定挂载的路径与宿主机上的文件系统结构紧密相关。
绑定挂载可以是只读的,也可以是可读写的。
Bind Mount的性能通常非常好,但它们依赖于宿主机的文件系统具有特定的目录结构。
使用Bind Mount时,如果宿主机上的路径不存在,Docker不会自动创建它,而是会报错。
docker run时 指定-v参数 -v 宿主机目录(需要已经存在):容器内目录
Bind mounts和Volumes行为上的差异
如果你将一个空Volume挂载到一个非空容器目录上,那么这个容器目录中的文件会被复制到Volume中,即容器目录原有文件不会被Volume覆盖。
如果你使用Bind mounts将一个宿主机目录挂载到容器目录上,此容器目录中原有的文件会被隐藏,从而只能读取到宿主机目录下的文件
-P 容器端口随机映射到宿主机端口
-p 指定宿主机端口映射容器端口
宿主机端口:容器端口 443:443 (TCP)
-p 5000:5000/udp 宿主机UDP5000映射到容器内UDP5000
/wordpress下放的是wordpress网站文件
phpmyadmin 在/wordpress/phpmyadmin
以下使用bind mount(绑定挂载)方式 -p 端口映射方式
-i 和 -t 使得容器拥有一个交互式终端 d 使得容器以分离模式在后台运行
-name 指定容器名字
–net wangjiale-network 指定容器使用的网络名字
–ip 172.18.0.1 指定容器IP地址
-h nginx 指定主机名
-v Bind mounts 持久化存储将宿主机目录挂载到容器内目录
-e 指定环境变量 设置容器时区
-p 端口映射 宿主机TCP 443 80 映射到容器内TCP 443 80
–privileged=true 允许容器内的进程获得宿主机上的超级用户权限,这意味着容器可以访问宿主机的所有硬件设备和系统资源,包括挂载文件系统、访问网络设备等。这种权限设置使得容器能够执行一些需要高权限的操作,例如加载内核模块、绕过SELinux策略等
–restart=always
Docker的重启策略包括以下几种:
no:容器退出时不重启容器
on-failure:只有在容器非正常退出时(退出状态非0)才重启容器
on-failure:在容器非正常退出时重启容器,最多重启N次
always:无论退出状态如何,都重启容器
nginx:1.20.1 镜像名字
nginx -g “daemon off;” https://blog.csdn.net/lgxzzz/article/details/123123110
-v /wordpress:/wordpress 指定php容器中WordPress网站存放路径 nginx处理静态页面以及图片若不指定会出现静态页面以及图片404错误
宿主机关于log日志的权限我这里都给了777否容器运行失败
以下宿主机目录或者文件需要是已存在的否则容器 run 失败 可以通过docker logs 容器ID或者容器名字查看到大概原因
docker run -itd –name nginx –net wangjiale-network –ip 172.18.0.1 -h nginx \
-v /nginx:/etc/nginx -v /wordpress:/wordpress -v /var/log/nginx/access.log:/var/log/nginx/access.log -v /var/log/nginx/error.log:/var/log/nginx/error.log \
-e TZ=Asia/Shanghai \
-p 443:443 -p 80:80 –privileged=true –restart=always nginx:1.20.1 nginx -g “daemon off;”
我这里mysql迁移数据是直接把mysql数据目录拷贝到宿主机/mysql下的运行使用没问题
宿主机关于log日志的权限都给777否则容器运行失败
docker run -itd –name mysql –net wangjiale-network –ip 172.18.0.2 -h mysql \
-v /mysql:/var/lib/mysql -v /my.cnf:/etc/my.cnf -v /var/log/mysql/mysqld.log:/var/log/mysqld.log -v /etc/localtime:/etc/localtime:ro \
-p 3306:3306 –privileged=true –restart=always -e TZ=Asia/Shanghai -e MYSQL_ROOT_PASSWORD=xxxxx密码 mysql:5.7.44
-v /wordpress:/wordpress 指定php容器中WordPress网站存放路径 php处理php动态页面
docker run -itd –name php –net wangjiale-network –ip 172.18.0.3 -h php \
-v /php.ini:/usr/local/etc/php/php.ini -v /wordpress:/wordpress \
-p 9000:9000 -e TZ=Asia/Shanghai –privileged=true –restart=always php:7.4.33-fpm

nginx配置文件注意事项:
访问报错404 File not found或者502 Bad Gateway是如下问题
假如写宿主机IP地址 错误的写php容器网站存放路径会导致404 File not found
假如写php容器IP地址 错误的写php容器网站存放路径会导致502 Bad Gateway
location ~ \.php$ {
root /wordpress; ###意思是指定php容器中网站存放路径/wordpress
fastcgi_pass 172.18.0.3:9000; ###经验证写宿主机或php容器的IP地址都可以 只不过是访问走的路不一样宿主机是172.18.0.254 - 24/Nov/2024:21:24:02 +0800 "GET /index.php" 500 php容器是172.18.0.1 - 24/Nov/2024:21:13:07 +0800 "GET /index.php" 500
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
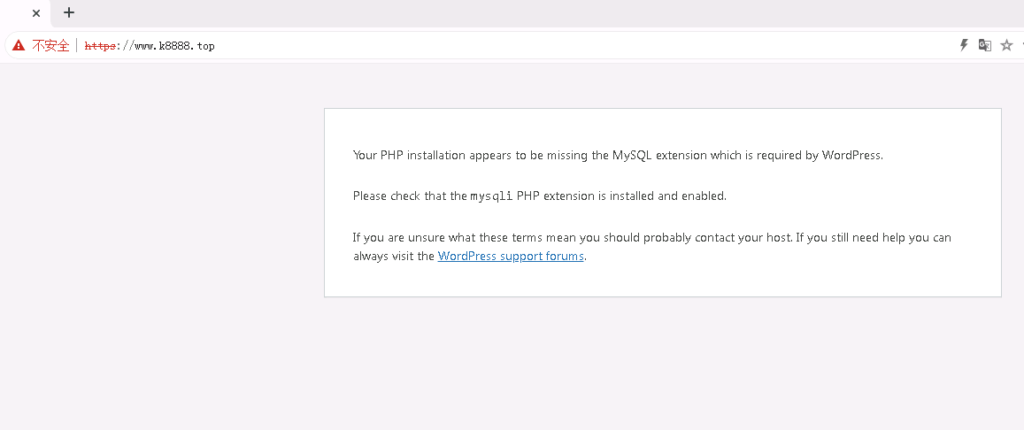
}访问wordpress报错500
172.18.0.254 – 24/Nov/2024:21:24:08 +0800 “GET /index.php” 500
Your PHP installation appears to be missing the MySQL extension which is required by WordPress.
Please check that the mysqli PHP extension is installed and enabled.
If you are unsure what these terms mean you should probably contact your host. If you still need help you can always visit the WordPress support forums.
需要安装PHP的mysql扩展进入到php容器下执行
docker-php-ext-install mysqli 安装扩展
php -m 查看是否成功
重启php容器生效
访问phpMyAdmin – 错误
缺少 mysqli 扩展。请检查 PHP 配置。 详情请查看我们的文档
进入到php容器下执行
docker-php-ext-install mysqli 安装扩展
php -m 查看是否成功
重启php容器生效
我这里的原因是因为php.ini文件内多写了个此参数pdo_mysql.default_socket但是pdo_mysql扩展没安装找不到所以提示缺少扩展
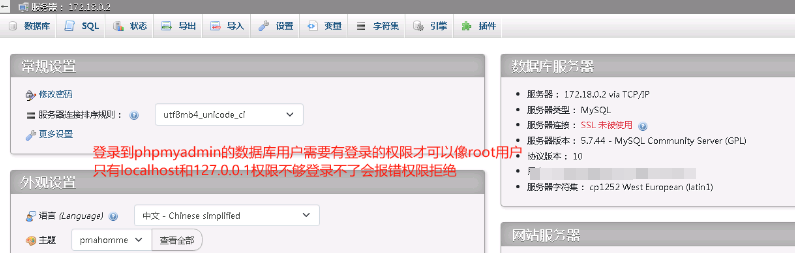
登录phpmyadmin报错mysqli::real_connect(): (HY000/2002): No such file or directory
网上说原因是php.ini中配置的mysqli没有与实际的mysql.sock对应正确
但是咱们不是本地sock方式连接的数据库 咱们是容器之间连接也就是TCP/IP方式 如果是单机部署的lnmp可以试一试这个解决方法
如果不配置php.ini里面的mysqli.default_socket那么默认值是/tmp/mysql.sock
my.cnf
[mysqld]
socket=/var/lib/mysql/mysql.sock
php.ini
mysqli.default_socket =/var/lib/mysql/mysql.sock
mysql.sock文件的作用有:
提供本地套接字通信:当客户端程序通过本地套接字连接到mysql.sock文件时,可以直接与MySQL服务器进行通信,而不需要通过网络连接。
优化通信性能:与通过TCP/IP进行网络连接相比,通过本地套接字连接的通信性能更高。因此,使用mysql.sock文件可以提高MySQL服务器与客户端程序之间的通信性能。
管理连接:mysql.sock文件还用于管理客户端程序与MySQL服务器之间的连接。服务器会维护mysql.sock文件中的连接信息,包括客户端的身份验证、会话状态等。
总而言之,mysql.sock文件在MySQL服务器和客户端程序之间提供了一个本地套接字通信通道,用于高效地进行数据交互和连接管理。
如上方法解决不了 /wordpress/phpmyadmin/libraries/config.default.php配置文件内如下 没问题的
$cfg[‘PmaAbsoluteUri’] = ‘https://域名/重命名的名字/index.php’; ###这里验证出只是记录phpmyadmin的访问网址 并无它用
$cfg[‘Servers’][$i][‘host’] = ”; ###MySQL的IP地址
$cfg[‘Servers’][$i][‘port’] = ”; ###MySQL数据库端口号 不写默认3306
$cfg[‘Servers’][$i][‘user’] = ”; ###MySQL的用户
$cfg[‘Servers’][$i][‘password’] = ”; ###MySQL的密码
$cfg[‘Servers’][$i][‘auth_type’] = ‘cookie’; ###在此有四种模式可供选择,cookie,http,http,config config方式即输入phpmyadmin的访问网址即可直接进入,无需输入用户名和密码,是不安全的,不推荐
使用。
$cfg[‘blowfish_secret’] = ”; ###如果认证方法设置为cookie,就需要设置短语密码,置于设置为什么密码,随意 ,但是不能留空,否则会在登录phpmyadmin时提示错误
wordpress网站正常写入 phpmyadmin连接不上那就不是数据库的问题了 就是phpmyadmin的问题了后来百度发现配置文件应是phpmyadmin目录下的config.inc.php而不是phpmyadmin/libraries目录下config.default.php奇了怪了非docker部署phpmyadmin配置文件是config.default.php生效的
那就将phpmyadmin目录下config.sample.inc.php复制一份重命名为config.inc.php
修改下面参数 经验证/wordpress/phpmyadmin/libraries/config.default.php和phpmyadmin/config.inc.php这两个文件都需要存在生效
$cfg[‘blowfish_secret’] 与config.default.php中的配置一致
$cfg[‘Servers’][$i][‘auth_type’] = ‘cookie’;
$cfg[‘Servers’][$i][‘host’] = ”;
设置docker-ce镜像源docker-ce为社区免费版本
yum-config-manager –add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo ###添加repo源
sed -i ‘s/download.docker.com/mirrors.aliyun.com\/docker-ce/g’ /etc/yum.repos.d/docker-ce.repo ###sed -i ‘s/要被替换的字符串/新的字符串/g’ 文件名
yum makecache fast ###makecache表示生成或更新缓存 fast是一个选项,用来告诉 yum 尽可能快地(但不完整)更新缓存,而不是下载所有可用的元数据,它通常会获取最新的 repomd.xml 文件和一些基本的包信息,以便进行基本的包搜索和安装操作。
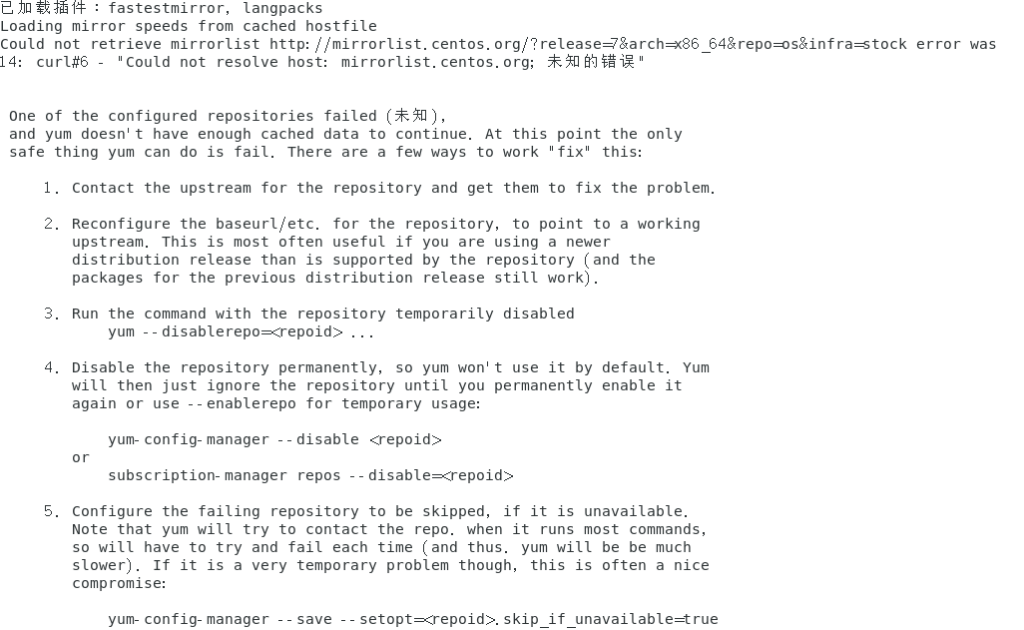
yum -y install docker-ce ###安装docker-ce 若报错如下 是yum源问题 将yum源更新至ali源最新即可 wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
不使用镜像加速会报如下错误:
Error response from daemon: Get “https://registry-1.docker.io/v2/”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
来自守护进程的错误响应:Get“https://registry-1.docker”。. io/v2/”: net/http:请求在等待连接时被取消。等待报头时超时
如下方式网上说管用 经验证不起作用
获取镜像加速器地址 https://cr.console.aliyun.com/cn-beijing/instances
ACR会为每一个账号(阿里云账号或RAM用户)生成一个镜像加速器地址,配置镜像加速器前,您需要获取镜像加速器地址。
1、登录容器镜像服务控制台。
2、在左侧导航栏选择镜像工具 > 镜像加速器
3、在镜像加速器页面获取加速器地址。
20241120日验证下面方法可以正常pull但是search是不成功的
cat /etc/docker/daemon.json
{
“registry-mirrors” :
[
“https://docker.m.daocloud.io”,
“https://noohub.ru”,
“https://huecker.io”,
“https://dockerhub.timeweb.cloud”
]
}
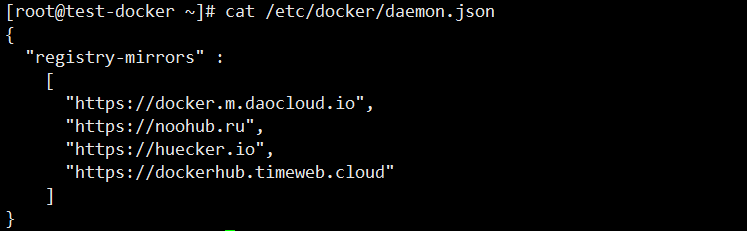
[root@test-docker ~]# docker search nginx ###search不成功
Error response from daemon: Get “https://index.docker.io/v1/search?q=nginx&n=25”: dial tcp 202.160.129.36:443: i/o timeout
[root@test-docker ~]# docker pull nginx:1.20.1
1.20.1: Pulling from library/nginx
b380bbd43752: Pull complete
83acae5e2daa: Pull complete
33715b419f9b: Pull complete
eb08b4d557d8: Pull complete
74d5bdecd955: Pull complete
0820d7f25141: Pull complete
Digest: sha256:a98c2360dcfe44e9987ed09d59421bb654cb6c4abe50a92ec9c912f252461483
Status: Downloaded newer image for nginx:1.20.1
docker.io/library/nginx:1.20.1
[root@test-docker ~]# docker pull mysql:5.7.44
5.7.44: Pulling from library/mysql
20e4dcae4c69: Pull complete
1c56c3d4ce74: Pull complete
e9f03a1c24ce: Pull complete
68c3898c2015: Pull complete
6b95a940e7b6: Pull complete
90986bb8de6e: Pull complete
ae71319cb779: Pull complete
ffc89e9dfd88: Pull complete
43d05e938198: Pull complete
064b2d298fba: Pull complete
df9a4d85569b: Pull complete
Digest: sha256:4bc6bc963e6d8443453676cae56536f4b8156d78bae03c0145cbe47c2aad73bb
Status: Downloaded newer image for mysql:5.7.44
docker.io/library/mysql:5.7.44
[root@test-docker ~]# docker pull php:7.4.33-fpm
7.4.33-fpm: Pulling from library/php
a603fa5e3b41: Pull complete
c428f1a49423: Pull complete
156740b07ef8: Pull complete
fb5a4c8af82f: Pull complete
972155ae644b: Pull complete
a8e3b94fe6c1: Pull complete
93346a3f46bc: Pull complete
b922b67ca46b: Pull complete
6137f893bda6: Pull complete
79b1a1b78461: Pull complete
Digest: sha256:3ac7c8c74b2b047c7cb273469d74fc0d59b857aa44043e6ea6a0084372811d5b
Status: Downloaded newer image for php:7.4.33-fpm
docker.io/library/php:7.4.33-fpm
[root@test-docker ~]# docker images -a
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql 5.7.44 5107333e08a8 11 months ago 501MB
php 7.4.33-fpm 38f2b691dcb8 2 years ago 443MB
nginx 1.20.1 c8d03f6b8b91 3 years ago 133MB

参考链接:https://blog.csdn.net/zzchances/article/details/127993610
https://blog.csdn.net/fengyuyeguirenenen/article/details/133978999
服务的管理是通过 systemd,而 systemd 的配置文件大部分放置于 /usr/lib/systemd/目录内。但是 Red Hat 官方文件指出, 该目录的文件主要是原本软件所提供的设置,建议不要修改!而要修改的位置应该放置于 /etc/systemd/system/目录内。
cat /etc/systemd/system/node_exporter.service
[Unit]
Description= Prometheus node exporter ###描述
After=network.target ###表示本 unit 应该在某服务之后启动
[Service]
Type=simple ###默认值 服务为主进程启动
User=root ###根据实际情况修改用户
ExecStart=/root/node_exporter-1.8.2.linux-amd64/node_exporter –web.listen-address=:19000 ###服务启动时执行的命令和参数 执行脚本路径以及端口采用19000
Restart=on-failure ###on-failure 仅在服务进程异常退出时重启,所谓“异常退出”是指:退出码不为”0″
[Install]
WantedBy=multi-user.target
chmod 644 node_exporter.service
systemctl daemon-reload
systemctl start node_exporter.service
systemctl enable node_exporter.service
systemctl status node_exporter.service
如果启动失败可以用journalctl -p err -b来查看错误日志 排查原因;
nohup 执行脚本 & ###即使退出终端任务依然运行
nohup /root/node_exporter-1.8.2.linux-amd64/./node_exporter &
nohup /root/oracledb_exporter-0.5.2.linux-amd64/./oracledb_exporter &
设置开机自动执行脚本
/etc/rc.d/rc.local 用于添加开机启动命令/etc/rc.local是/etc/rc.d/rc.local的软连接 软连接相当于windows的快捷键
chmod 777 /etc/rc.local 设置权限
vi /etc/rc.local
nohup /root/node_exporter-1.8.2.linux-amd64/./node_exporter &
nohup /root/oracledb_exporter-0.5.2.linux-amd64/./oracledb_exporter &
phpMyAdmin MySQL的管理工具,web方式管理MySQL
官网下载源码包链接:https://www.phpmyadmin.net/downloads/
也可以用我下载好的源码包
官网源码包的SHA256值
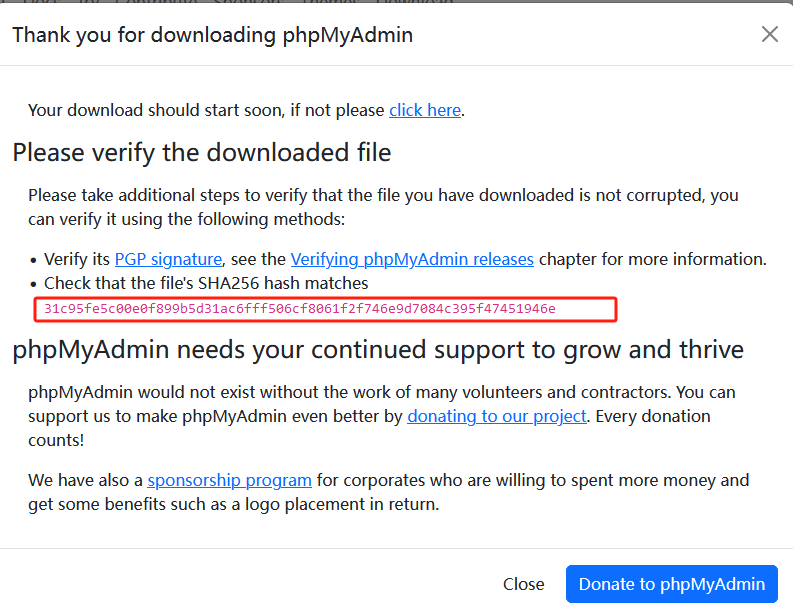
下载到本地Windows电脑的SHA256值
Get-FileHash .\phpMyAdmin-5.2.1-all-languages.zip -Algorithm SHA256

上传到centos服务器的SHA256值 可以看到三个值一致
sha256sum phpMyAdmin-5.2.1-all-languages.zip

unzip phpMyAdmin-5.2.1-all-languages.zip ###解压
mv phpMyAdmin-5.2.1-all-languages 重命名的名字 ###重命名
mv 重命名的名字 到网站根目录下 ###移动到网站根目录
cd 到网站根目录下
chmod 777 -R 重命名的名字/ ### -R 递归授权phpmyadmin及其下属777授权
cd /网站根目录/重命名的名字/libraries/
cp config.default.php config.default.php.bak ###备份默认配置文件
vim config.default.php ###更改配置文件内容
$cfg[‘PmaAbsoluteUri’] = ‘https://域名/重命名的名字/index.php’; ###这里验证出只是记录phpmyadmin的访问网址 并无它用
$cfg[‘Servers’][$i][‘host’] = ”; ###MySQL的IP地址
$cfg[‘Servers’][$i][‘port’] = ”; ###MySQL数据库端口号 不写默认3306
$cfg[‘Servers’][$i][‘user’] = ”; ###MySQL的用户
$cfg[‘Servers’][$i][‘password’] = ”; ###MySQL的密码
$cfg[‘Servers’][$i][‘auth_type’] = ‘cookie’; ###在此有四种模式可供选择,cookie,http,http,config config方式即输入phpmyadmin的访问网址即可直接进入,无需输入用户名和密码,是不安全的,不推荐
使用。
当该项设置为cookie,http或http时,登录phpmyadmin需要DB的用户名和密码进行验证
具体如下:php安装模式为apache,可以使用http和cookie;php安装模式为cgi,可以使用cookie
$cfg[‘blowfish_secret’] = ”; ###如果认证方法设置为cookie,就需要设置短语密码,置于设置为什么密码,随意 ,但是不能留空,否则会在登录phpmyadmin时提示错误
浏览器输入https://域名/重命名的名字/index.php 输入MySQL的账号密码即可登录;
转载于:
https://blog.csdn.net/Perfect886/article/details/120658206
https://blog.csdn.net/ZCZC946/article/details/117690747
https://www.cnblogs.com/daoguanmao/p/17203571.html
https://www.cnblogs.com/littlecc/p/18290823
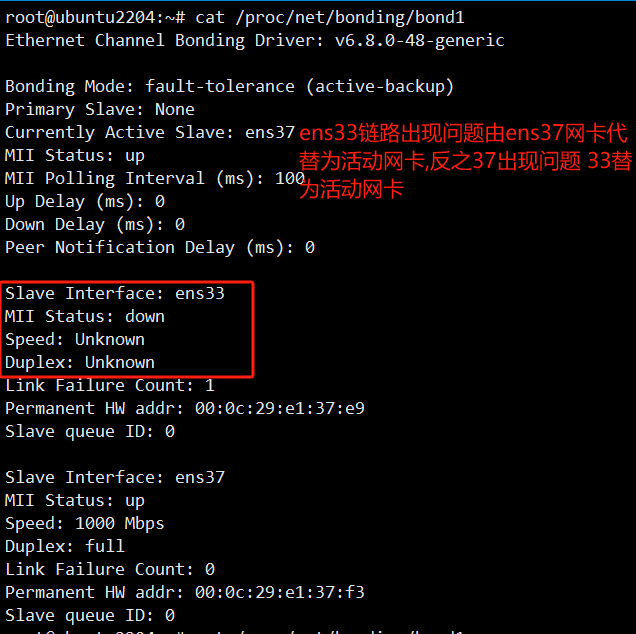
bonding 驱动提供了一个将多个物理网络端口捆绑为单个逻辑网络端口的方法,用于网络负载均衡、冗余和提升网络的性能
1、mode=0(balance-rr)(平衡抡循环策略)
链路负载均衡,增加带宽,支持容错,一条链路故障会自动切换正常链路。交换机需要配置聚合口,思科叫port channel。
特点:传输数据包顺序是依次传输(即:第1个包走eth0,下一个包就走eth1….一直循环下去,直到最后一个传输完毕),此模式提供负载平衡和容错能力;但是我们知道如果一个连接
或者会话的数据包从不同的接口发出的话,中途再经过不同的链路,在客户端很有可能会出现数据包无序到达的问题,而无序到达的数据包需要重新要求被发送,这样网络的吞吐量就会下降
2、mode=1(active-backup)(主-备份策略)
这个是主备模式,只有一块网卡是active,另一块是备用的standby,所有流量都在active链路上处理,交换机配置的是捆绑的话将不能工作,因为交换机往两块网卡发包,有一半包是丢弃的,不需要交换机特别配置,配置access端口就可以了。
特点:只有一个设备处于活动状态,当一个宕掉另一个马上由备份转换为主设备。mac地址是外部可见得,从外面看来,bond的MAC地址是唯一的,以避免switch(交换机)发生混乱。
此模式只提供了容错能力;由此可见此算法的优点是可以提供高网络连接的可用性,但是它的资源利用率较低,只有一个接口处于工作状态,在有 N 个网络接口的情况下,资源利用率为1/N
3、mode=2(balance-xor)(平衡策略)
表示XOR Hash负载分担,和交换机的聚合强制不协商方式配合。(需要xmit_hash_policy,需要交换机配置port channel)
特点:基于指定的传输HASH策略传输数据包。缺省的策略是:(源MAC地址 XOR 目标MAC地址) % slave数量。其他的传输策略可以通过xmit_hash_policy选项指定,此模式提供负载平衡和容错能力
4、mode=3(broadcast)(广播策略)
表示所有包从所有网络接口发出,这个不均衡,只有冗余机制,但过于浪费资源。此模式适用于金融行业,因为他们需要高可靠性的网络,不允许出现任何问题。需要和交换机的聚合强制不协商方式配合。
特点:在每个slave接口上传输每个数据包,此模式提供了容错能力
5、mode=4(802.3ad)(IEEE 802.3ad 动态链接聚合)
表示支持802.3ad协议,和交换机的聚合LACP方式配合(需要xmit_hash_policy).标准要求所有设备在聚合操作时,要在同样的速率和双工模式,而且,和除了balance-rr模式外的其它bonding负载均衡模式一样,任何连接都不能使用多于一个接口的带宽。
特点:创建一个聚合组,它们共享同样的速率和双工设定。根据802.3ad规范将多个slave工作在同一个激活的聚合体下。
外出流量的slave选举是基于传输hash策略,该策略可以通过xmit_hash_policy选项从缺省的XOR策略改变到其他策略。需要注意的 是,并不是所有的传输策略都是802.3ad适应的,
尤其考虑到在802.3ad标准43.2.4章节提及的包乱序问题。不同的实现可能会有不同的适应 性。
必要条件:
条件1:ethtool支持获取每个slave的速率和双工设定
条件2:switch(交换机)支持IEEE 802.3ad Dynamic link aggregation
条件3:大多数switch(交换机)需要经过特定配置才能支持802.3ad模式
6、mode=5(balance-tlb)(适配器传输负载均衡)
是根据每个slave的负载情况选择slave进行发送,接收时使用当前轮到的slave。该模式要求slave接口的网络设备驱动有某种ethtool支持;而且ARP监控不可用。
特点:不需要任何特别的switch(交换机)支持的通道bonding。在每个slave上根据当前的负载(根据速度计算)分配外出流量。如果正在接受数据的slave出故障了,另一个slave接管失败的slave的MAC地址。
必要条件:
ethtool支持获取每个slave的速率
7、mode=6(balance-alb)(适配器适应性负载均衡)
在5的tlb基础上增加了rlb(接收负载均衡receive load balance).不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的.
特点:该模式包含了balance-tlb模式,同时加上针对IPV4流量的接收负载均衡(receive load balance, rlb),而且不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的。bonding驱动截获本机发送的ARP应答,并把源硬件地址改写为bond中某个slave的唯一硬件地址,从而使得不同的对端使用不同的硬件地址进行通信。
来自服务器端的接收流量也会被均衡。当本机发送ARP请求时,bonding驱动把对端的IP信息从ARP包中复制并保存下来。当ARP应答从对端到达 时,bonding驱动把它的硬件地址提取出来,并发起一个ARP应答给bond中的某个slave。
使用ARP协商进行负载均衡的一个问题是:每次广播 ARP请求时都会使用bond的硬件地址,因此对端学习到这个硬件地址后,接收流量将会全部流向当前的slave。这个问题可以通过给所有的对端发送更新 (ARP应答)来解决,应答中包含他们独一无二的硬件地址,从而导致流量重新分布。
当新的slave加入到bond中时,或者某个未激活的slave重新 激活时,接收流量也要重新分布。接收的负载被顺序地分布(round robin)在bond中最高速的slave上
当某个链路被重新接上,或者一个新的slave加入到bond中,接收流量在所有当前激活的slave中全部重新分配,通过使用指定的MAC地址给每个 client发起ARP应答。下面介绍的updelay参数必须被设置为某个大于等于switch(交换机)转发延时的值,从而保证发往对端的ARP应答 不会被switch(交换机)阻截。
必要条件:
条件1:ethtool支持获取每个slave的速率;
条件2:底层驱动支持设置某个设备的硬件地址,从而使得总是有个slave(curr_active_slave)使用bond的硬件地址,同时保证每个bond 中的slave都有一个唯一的硬件地址。如果curr_active_slave出故障,它的硬件地址将会被新选出来的 curr_active_slave接管
其实mod=6与mod=0的区别:mod=6,先把eth0流量占满,再占eth1,….ethX;而mod=0的话,会发现2个口的流量都很稳定,基本一样的带宽。而mod=6,会发现第一个口流量很高,第2个口只占了小部分流量。
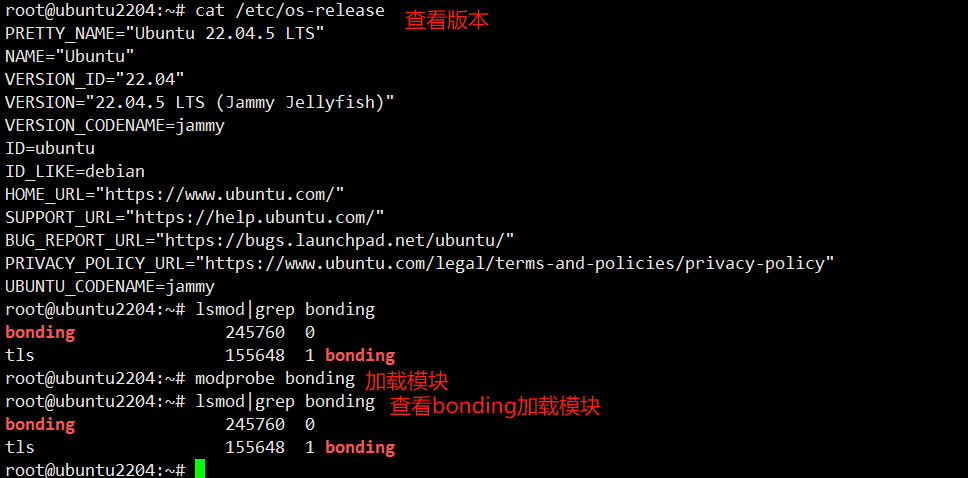
lsmod | grep bonding ###查看是否已加载bonding模块
sudo modprobe bonding ###加载bonding模块 默认是加载了的
vim /etc/modules ###编辑配置文件,不然通过命令加载模块,重启会失效
bonding mode=1 miimon=100
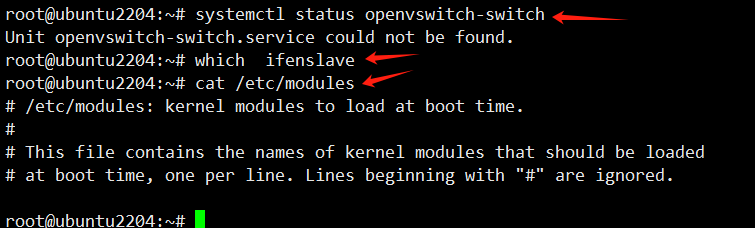
which ifenslave ###检查是否安装ifenslave
说明: 如果想移除某个模块,使用rmmod命令就行了。
例如移动 bonding 模块就是 rmmod bonding
查看网上资料需要做这几步操作 此案例没有vim /etc/modules 也没有安装ifenslave openvswitch-switch服务 依然可以主备切换成功 重启机器也可以切换成功
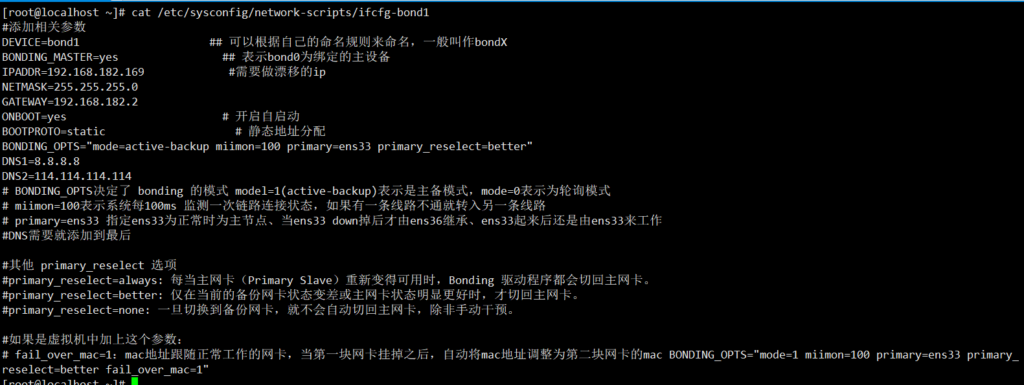
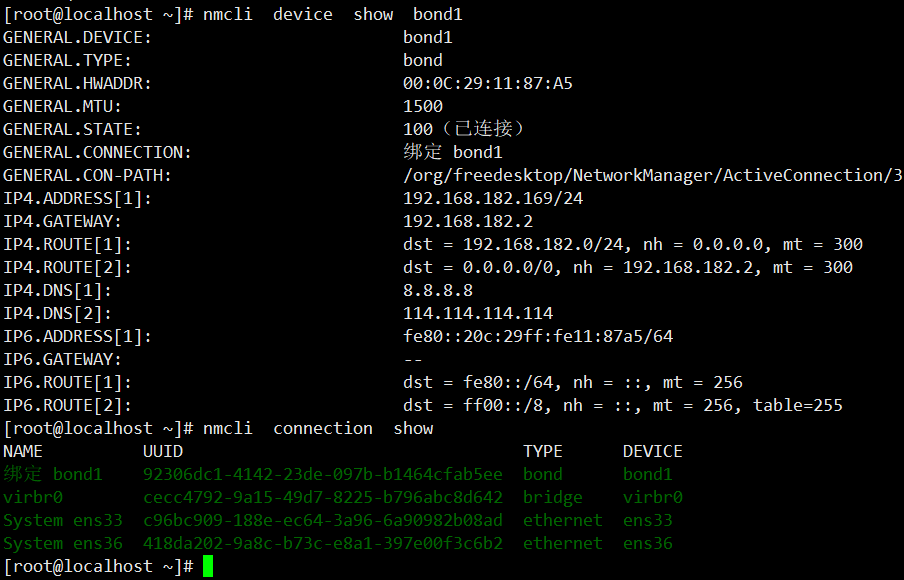
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-bond1
#添加相关参数
DEVICE=bond1 ## 可以根据自己的命名规则来命名,一般叫作bondX
BONDING_MASTER=yes ## 表示bond0为绑定的主设备
IPADDR=192.168.182.169 #需要做漂移的ip
NETMASK=255.255.255.0
GATEWAY=192.168.182.2
ONBOOT=yes # 开启自启动
BOOTPROTO=static # 静态地址分配
BONDING_OPTS="mode=active-backup miimon=100 primary=ens33 primary_reselect=better"
DNS1=8.8.8.8
DNS2=114.114.114.114
# BONDING_OPTS决定了 bonding 的模式 model=1(active-backup)表示是主备模式,mode=0表示为轮询模式
# miimon=100表示系统每100ms 监测一次链路连接状态,如果有一条线路不通就转入另一条线路
# primary=ens33 指定ens33为正常时为主节点、当ens33 down掉后才由ens36继承、ens33起来后还是由ens33来工作
#DNS需要就添加到最后
#其他 primary_reselect 选项
#primary_reselect=always: 每当主网卡(Primary Slave)重新变得可用时,Bonding 驱动程序都会切回主网卡。
#primary_reselect=better: 仅在当前的备份网卡状态变差或主网卡状态明显更好时,才切回主网卡。
#primary_reselect=none: 一旦切换到备份网卡,就不会自动切回主网卡,除非手动干预。
#如果是虚拟机中加上这个参数:
# fail_over_mac=1:mac地址跟随正常工作的网卡,当第一块网卡挂掉之后,自动将mac地址调整为第二块网卡的mac BONDING_OPTS="mode=1 miimon=100 primary=ens33 primary_reselect=better fail_over_mac=1"
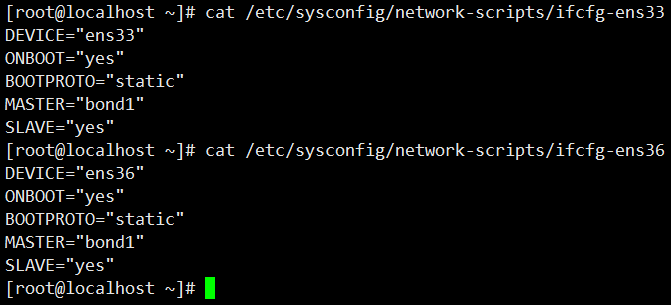
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE="ens33"
ONBOOT="yes"
BOOTPROTO="static"
MASTER="bond1"
SLAVE="yes"
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens36
DEVICE="ens36"
ONBOOT="yes"
BOOTPROTO="static"
MASTER="bond1"
SLAVE="yes"
转载于:
https://blog.csdn.net/Perfect886/article/details/120658206
https://blog.csdn.net/ZCZC946/article/details/117690747
https://www.cnblogs.com/daoguanmao/p/17203571.html
https://www.cnblogs.com/littlecc/p/18290823
bonding 驱动提供了一个将多个物理网络端口捆绑为单个逻辑网络端口的方法,用于网络负载均衡、冗余和提升网络的性能
1、mode=0(balance-rr)(平衡抡循环策略)
链路负载均衡,增加带宽,支持容错,一条链路故障会自动切换正常链路。交换机需要配置聚合口,思科叫port channel。
特点:传输数据包顺序是依次传输(即:第1个包走eth0,下一个包就走eth1….一直循环下去,直到最后一个传输完毕),此模式提供负载平衡和容错能力;但是我们知道如果一个连接
或者会话的数据包从不同的接口发出的话,中途再经过不同的链路,在客户端很有可能会出现数据包无序到达的问题,而无序到达的数据包需要重新要求被发送,这样网络的吞吐量就会下降
2、mode=1(active-backup)(主-备份策略)
这个是主备模式,只有一块网卡是active,另一块是备用的standby,所有流量都在active链路上处理,交换机配置的是捆绑的话将不能工作,因为交换机往两块网卡发包,有一半包是丢弃的,不需要交换机特别配置,配置access端口就可以了。
特点:只有一个设备处于活动状态,当一个宕掉另一个马上由备份转换为主设备。mac地址是外部可见得,从外面看来,bond的MAC地址是唯一的,以避免switch(交换机)发生混乱。
此模式只提供了容错能力;由此可见此算法的优点是可以提供高网络连接的可用性,但是它的资源利用率较低,只有一个接口处于工作状态,在有 N 个网络接口的情况下,资源利用率为1/N
3、mode=2(balance-xor)(平衡策略)
表示XOR Hash负载分担,和交换机的聚合强制不协商方式配合。(需要xmit_hash_policy,需要交换机配置port channel)
特点:基于指定的传输HASH策略传输数据包。缺省的策略是:(源MAC地址 XOR 目标MAC地址) % slave数量。其他的传输策略可以通过xmit_hash_policy选项指定,此模式提供负载平衡和容错能力
4、mode=3(broadcast)(广播策略)
表示所有包从所有网络接口发出,这个不均衡,只有冗余机制,但过于浪费资源。此模式适用于金融行业,因为他们需要高可靠性的网络,不允许出现任何问题。需要和交换机的聚合强制不协商方式配合。
特点:在每个slave接口上传输每个数据包,此模式提供了容错能力
5、mode=4(802.3ad)(IEEE 802.3ad 动态链接聚合)
表示支持802.3ad协议,和交换机的聚合LACP方式配合(需要xmit_hash_policy).标准要求所有设备在聚合操作时,要在同样的速率和双工模式,而且,和除了balance-rr模式外的其它bonding负载均衡模式一样,任何连接都不能使用多于一个接口的带宽。
特点:创建一个聚合组,它们共享同样的速率和双工设定。根据802.3ad规范将多个slave工作在同一个激活的聚合体下。
外出流量的slave选举是基于传输hash策略,该策略可以通过xmit_hash_policy选项从缺省的XOR策略改变到其他策略。需要注意的 是,并不是所有的传输策略都是802.3ad适应的,
尤其考虑到在802.3ad标准43.2.4章节提及的包乱序问题。不同的实现可能会有不同的适应 性。
必要条件:
条件1:ethtool支持获取每个slave的速率和双工设定
条件2:switch(交换机)支持IEEE 802.3ad Dynamic link aggregation
条件3:大多数switch(交换机)需要经过特定配置才能支持802.3ad模式
6、mode=5(balance-tlb)(适配器传输负载均衡)
是根据每个slave的负载情况选择slave进行发送,接收时使用当前轮到的slave。该模式要求slave接口的网络设备驱动有某种ethtool支持;而且ARP监控不可用。
特点:不需要任何特别的switch(交换机)支持的通道bonding。在每个slave上根据当前的负载(根据速度计算)分配外出流量。如果正在接受数据的slave出故障了,另一个slave接管失败的slave的MAC地址。
必要条件:
ethtool支持获取每个slave的速率
7、mode=6(balance-alb)(适配器适应性负载均衡)
在5的tlb基础上增加了rlb(接收负载均衡receive load balance).不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的.
特点:该模式包含了balance-tlb模式,同时加上针对IPV4流量的接收负载均衡(receive load balance, rlb),而且不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的。bonding驱动截获本机发送的ARP应答,并把源硬件地址改写为bond中某个slave的唯一硬件地址,从而使得不同的对端使用不同的硬件地址进行通信。
来自服务器端的接收流量也会被均衡。当本机发送ARP请求时,bonding驱动把对端的IP信息从ARP包中复制并保存下来。当ARP应答从对端到达 时,bonding驱动把它的硬件地址提取出来,并发起一个ARP应答给bond中的某个slave。
使用ARP协商进行负载均衡的一个问题是:每次广播 ARP请求时都会使用bond的硬件地址,因此对端学习到这个硬件地址后,接收流量将会全部流向当前的slave。这个问题可以通过给所有的对端发送更新 (ARP应答)来解决,应答中包含他们独一无二的硬件地址,从而导致流量重新分布。
当新的slave加入到bond中时,或者某个未激活的slave重新 激活时,接收流量也要重新分布。接收的负载被顺序地分布(round robin)在bond中最高速的slave上
当某个链路被重新接上,或者一个新的slave加入到bond中,接收流量在所有当前激活的slave中全部重新分配,通过使用指定的MAC地址给每个 client发起ARP应答。下面介绍的updelay参数必须被设置为某个大于等于switch(交换机)转发延时的值,从而保证发往对端的ARP应答 不会被switch(交换机)阻截。
必要条件:
条件1:ethtool支持获取每个slave的速率;
条件2:底层驱动支持设置某个设备的硬件地址,从而使得总是有个slave(curr_active_slave)使用bond的硬件地址,同时保证每个bond 中的slave都有一个唯一的硬件地址。如果curr_active_slave出故障,它的硬件地址将会被新选出来的 curr_active_slave接管
其实mod=6与mod=0的区别:mod=6,先把eth0流量占满,再占eth1,….ethX;而mod=0的话,会发现2个口的流量都很稳定,基本一样的带宽。而mod=6,会发现第一个口流量很高,第2个口只占了小部分流量。
lsmod | grep bonding ###查看是否已加载bonding模块
sudo modprobe bonding ###加载bonding模块 默认是加载了的
vim /etc/modules ###编辑配置文件,不然通过命令加载模块,重启会失效
bonding mode=1 miimon=100
which ifenslave ###检查是否安装ifenslave
说明: 如果想移除某个模块,使用rmmod命令就行了。
例如移动 bonding 模块就是 rmmod bonding
查看网上资料需要做这几步操作 此案例没有vim /etc/modules 也没有安装ifenslave openvswitch-switch服务 依然可以主备切换成功 重启机器也可以切换成功
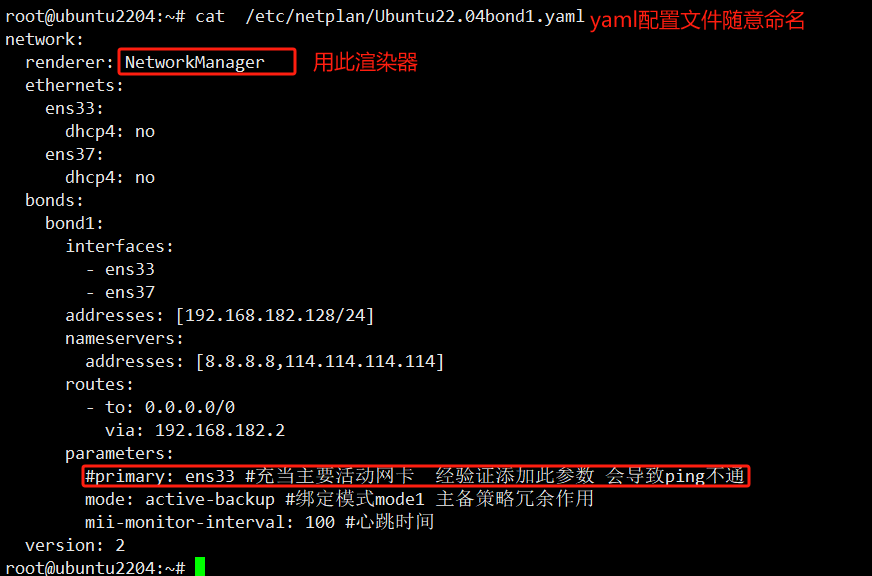
network:
renderer: NetworkManager
ethernets:
ens33:
dhcp4: no
ens37:
dhcp4: no
bonds:
bond1:
interfaces:
- ens33
- ens37
addresses: [192.168.182.128/24]
nameservers:
addresses: [8.8.8.8,114.114.114.114]
routes:
- to: 0.0.0.0/0
via: 192.168.182.2
parameters:
#primary: ens33 #充当主要活动网卡 经验证添加此参数 会导致ping不通
mode: active-backup #绑定模式mode1 主备策略冗余作用
mii-monitor-interval: 100 #心跳时间
version: 2netplan apply 重启网络
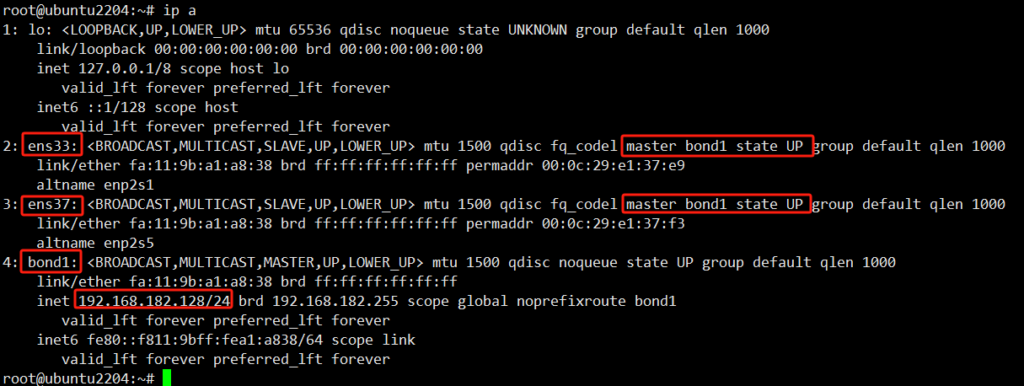
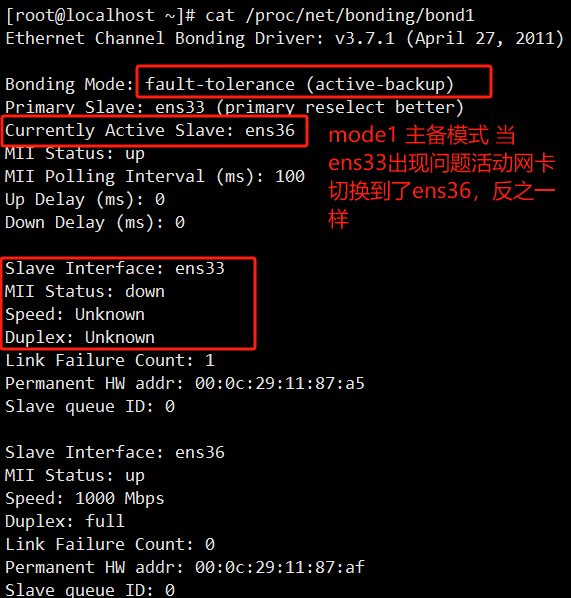
Active Slave:表示的是当前活动的网卡
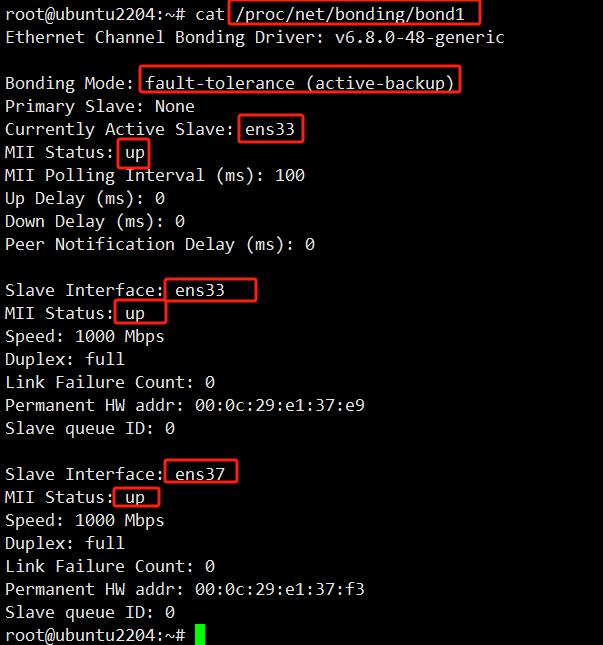
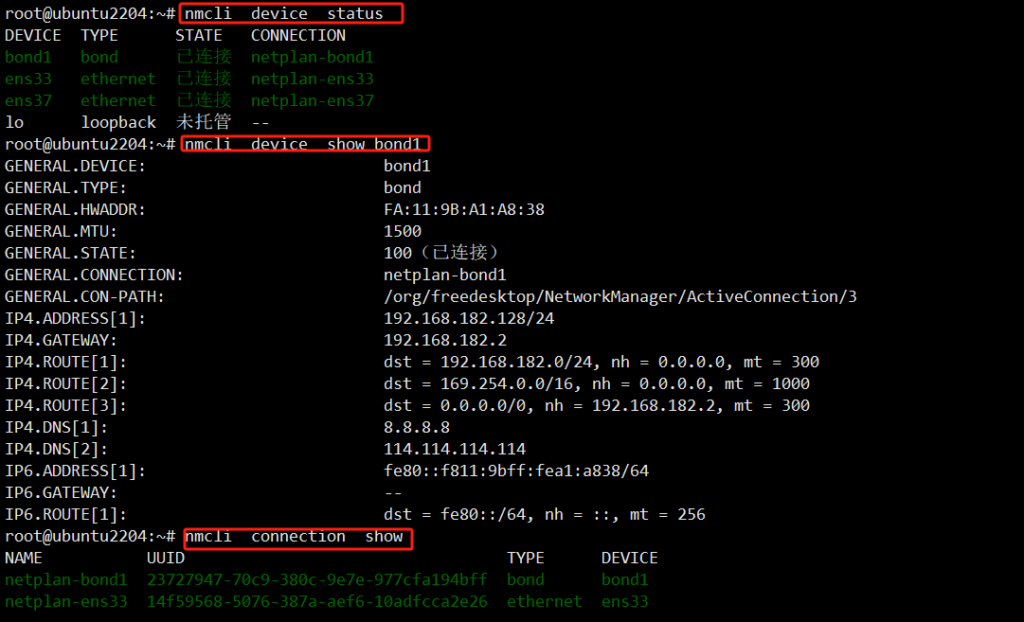
报错
vi /var/log/auth.log ###登录认证的信息记录
Oct 22 15:21:42 wangjiale-virtual-machine gdm-password]: pam_succeed_if(gdm-password:auth): requirement “user != root” not met by user “root”
root用户user != root不满足要求
Oct 22 15:21:48 wangjiale-virtual-machine gdm-password]: gkr-pam: unable to locate daemon control file
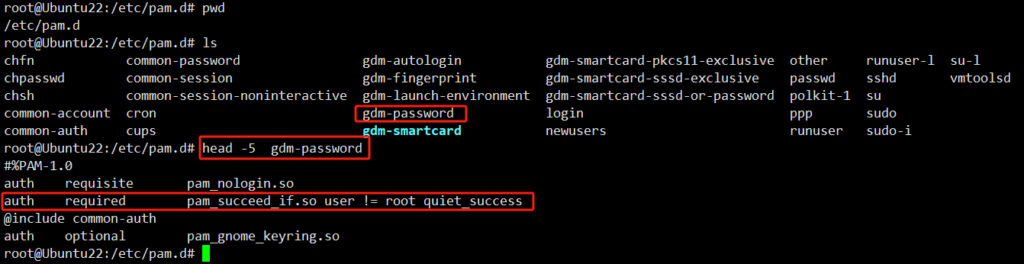
auth required pam_succeed_if.so user != root quiet_success
意思是
required:要求 pam_succeed_if.so:用户登录限制 user != root quiet_success:用户不等于(!=)root的取得成功
将此行注释掉即不生效 wq退出即可生效
#auth required pam_succeed_if.so user != root quiet_success
gdm-password:对应图形界面的登录认证模式 确保用户可以安全地登录到他们的桌面环境
也就是说限制登录本地图形界面的操作(CTRL+ALT+F1) (VNC图形化方式远程不清楚)
而(CTRL+ALT+F2/3/4/5…)本地命令行界面登录不受限制
login:对应本地命令行界面的登录认证模式
sshd:命令行远程方式的登录认证模式
gdm是一种图形显示管理器
GDM(GNOME Display Manager)是Linux系统中用于管理图形显示服务器并处理图形用户登录的程序

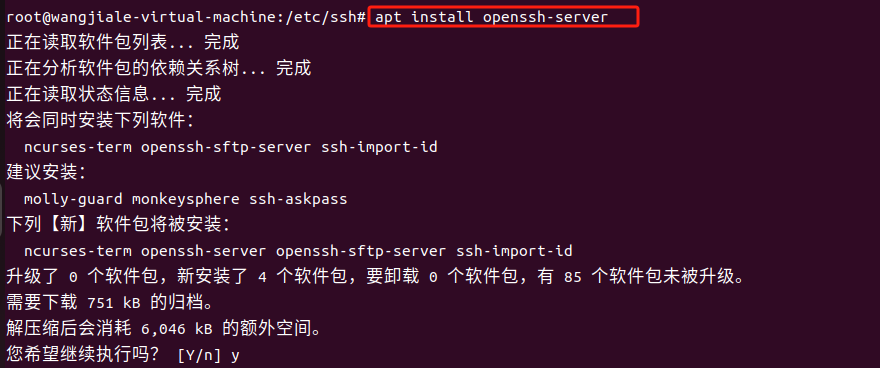
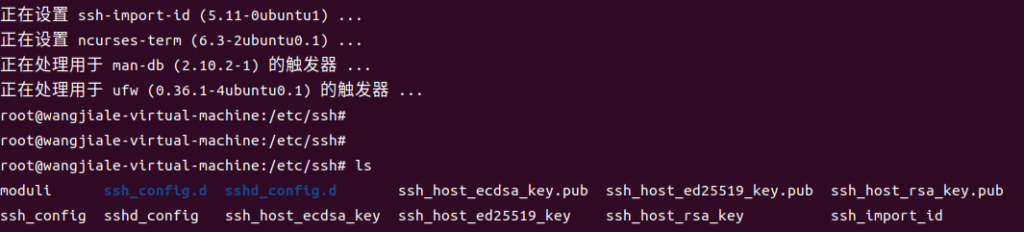
ubuntu安装openssh-server提示没有可安装候选错误 那就apt update 一下解决
PermitRootLogin prohibit-password/without-password/forced-commands-only/yes/no

| 参数选项 | 是否允许root ssh登录 | 登录方式 |
| prohibit-password | 允许 | 但是禁止以密码方式登录 |
| without-password | 允许 | 翻译中文是没有密码 具体不确定网上看博主资料应该是与此参数差不多prohibit-password |
| forced-commands-only | 允许 | 请参考网上资料 |
| yes | 允许 | 没有限制 |
| no | 不允许 | 不允许 |

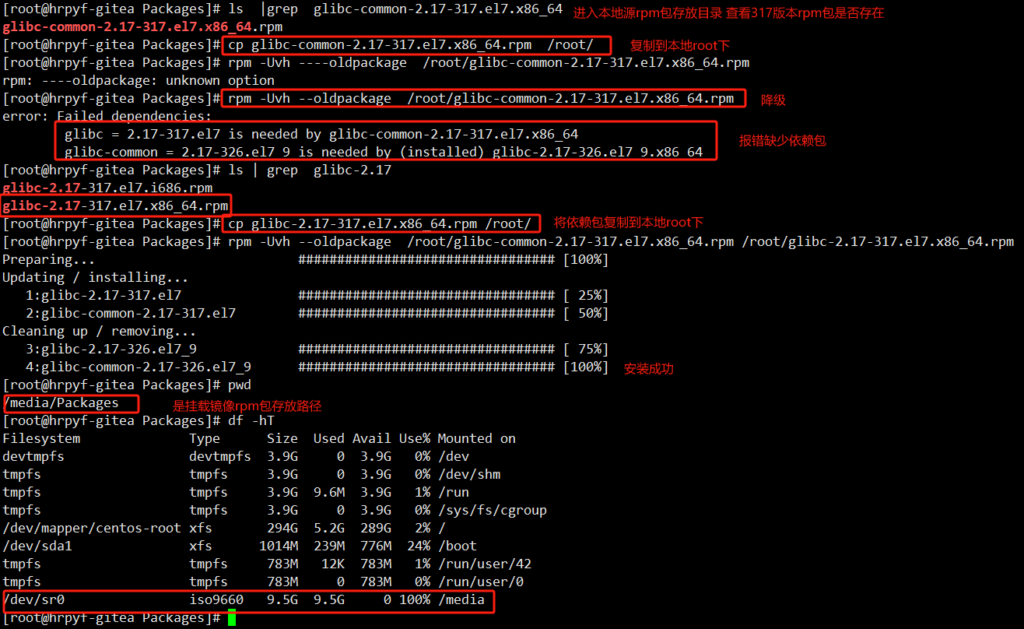
错误:Package: glibc-2.17-317.el7。i686(本地)
要求:glibc-common = 2.17-317.el7
安装:glibc -通用- 2.17 – 326. – el7_9。x86_64 (@updates)
Glibc-common = 2.17-326.el7_9
: glibc el7——常见的- 2.17 – 317.。x86_64(本地)
Glibc-common = 2.17-317.el7
您可以尝试使用——skip-broken来解决这个问题
你可以试着运行:rpm -Va——nofiles——nodigest
上面说要求:Available(可用): glibc-common-2.17-317.el7.x86_64 (local) 而系统内包是glibc-common-2.17-326.el7_9.x86_64 版本较新 所以将其降级即可
用本地源安装gcc要求的依赖包版本低 而本地依赖包版本高 所以在本地源拉取低版本依赖包 到本地降级安装
ls |grep glibc-common-2.17-317.el7.x86_64
cp glibc-common-2.17-317.el7.x86_64.rpm /root/
cp glibc-2.17-317.el7.x86_64.rpm /root/
rpm -Uvh --oldpackage /root/glibc-common-2.17-317.el7.x86_64.rpm /root/glibc-2.17-317.el7.x86_64.rpmPreparing… ################################# [100%]
Updating / installing…
1:glibc-2.17-317.el7 ################################# [ 25%]
2:glibc-common-2.17-317.el7 ################################# [ 50%]
Cleaning up / removing…
3:glibc-2.17-326.el7_9 ################################# [ 75%]
4:glibc-common-2.17-326.el7_9 ################################# [100%]
-Uvh:这是升级 (upgrade) 的简写形式,同时包含了 -v(verbose,详细模式)和 -h(hash marks,进度条显示)选项,用于在安装过程中提供更多信息和可视化的进度反馈。
–oldpackage:这个选项告诉 RPM 系统允许安装一个版本更低的包,即执行降级操作。
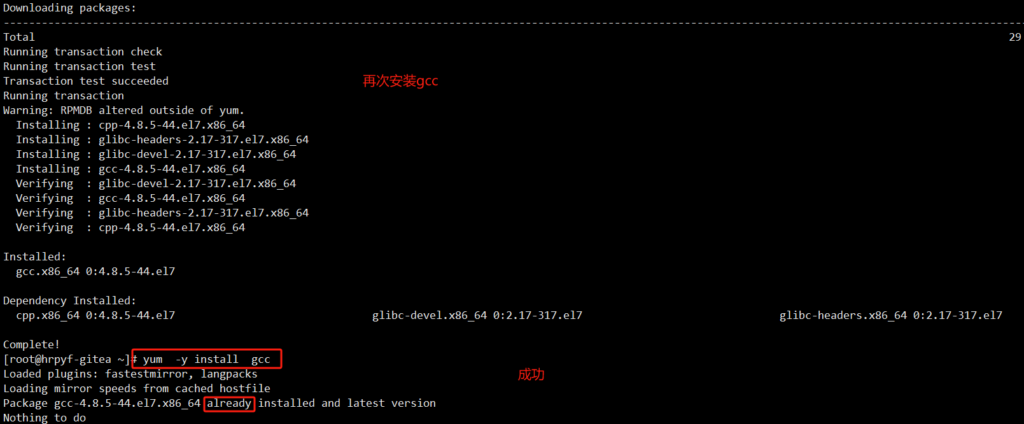
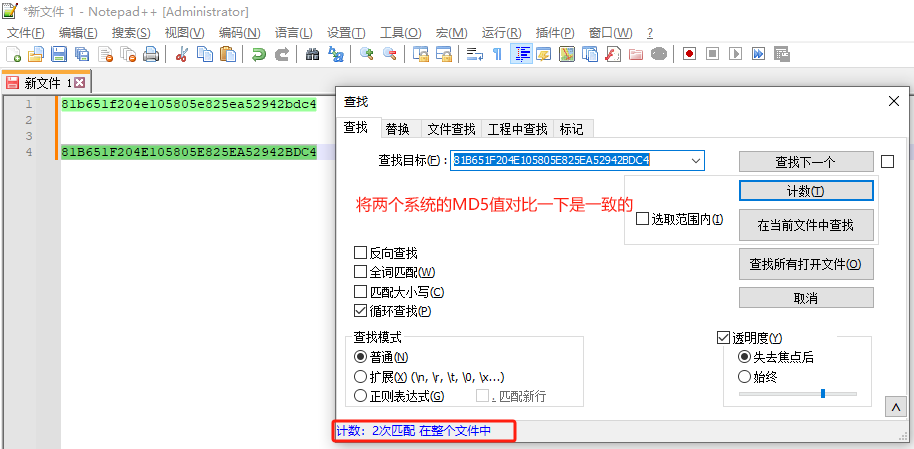
下载、传输文件后需要确定文件的安全性和完整性 此案例采用MD5方式
Get-FileHash .\Xshell.rar -Algorithm MD5

如果报错
‘Get-FileHash’ 不是内部或外部命令,也不是可运行的程序或批处理文件。
原因是PowerShell 版本太旧,不支持 Get-FileHash 命令。
下载安装下面powershell即可
md5sum Xshell.rar

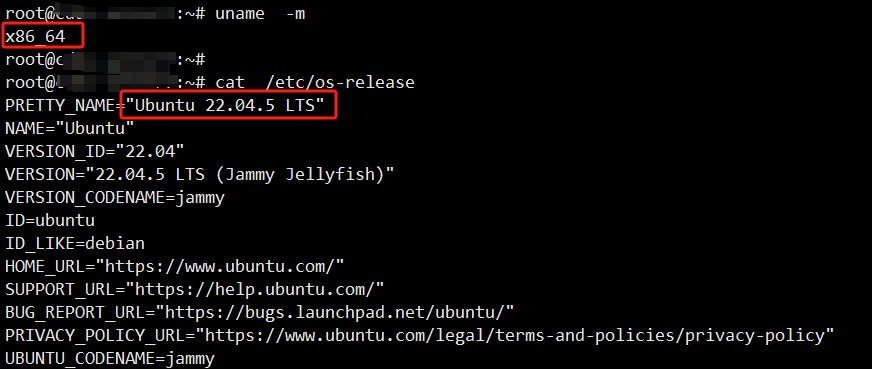
转载链接:https://zhuanlan.zhihu.com/p/682841091?utm_id=0
uname -m
如果看到x86_64,amd64或Intel你应该下载并安装 AMD 版本的软件包。
如果看到arm64或aarch64你应该下载并安装 ARM 版本的软件包。
cat /etc/os-release 看系统版本
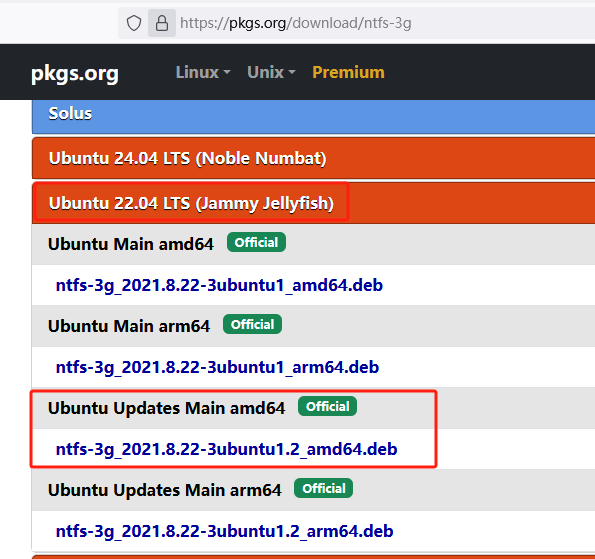
此链接有大部分系统ntfs-3g的离线包:https://pkgs.org/download/ntfs-3g
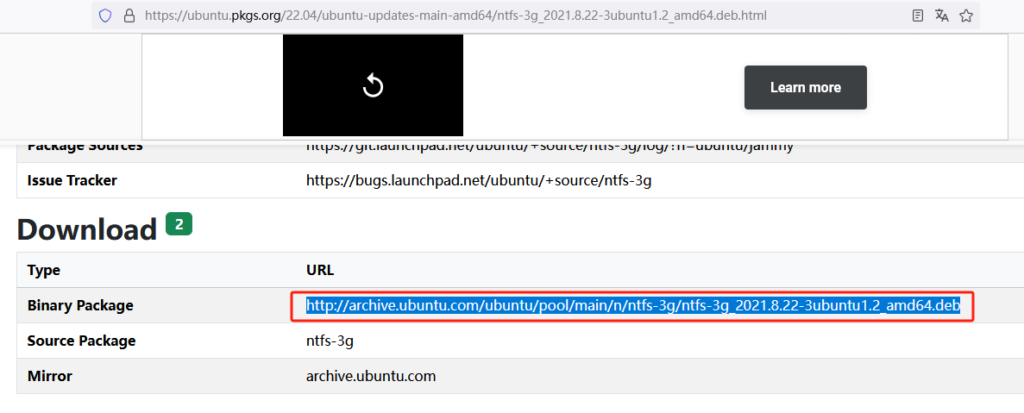
| Ubuntu 22.04 x86_64(AMD架构)deb包下载链接 | http://archive.ubuntu.com/ubuntu/pool/main/n/ntfs-3g/ntfs-3g_2021.8.22-3ubuntu1.2_amd64.deb |
|---|
dpkg -i ntfs-3g_2021.8.22-3ubuntu1.2_amd64.deb ###安装
mount /dev/sdd1 /file/ ###临时挂载 永久挂载需要添加/etc/fstab文件

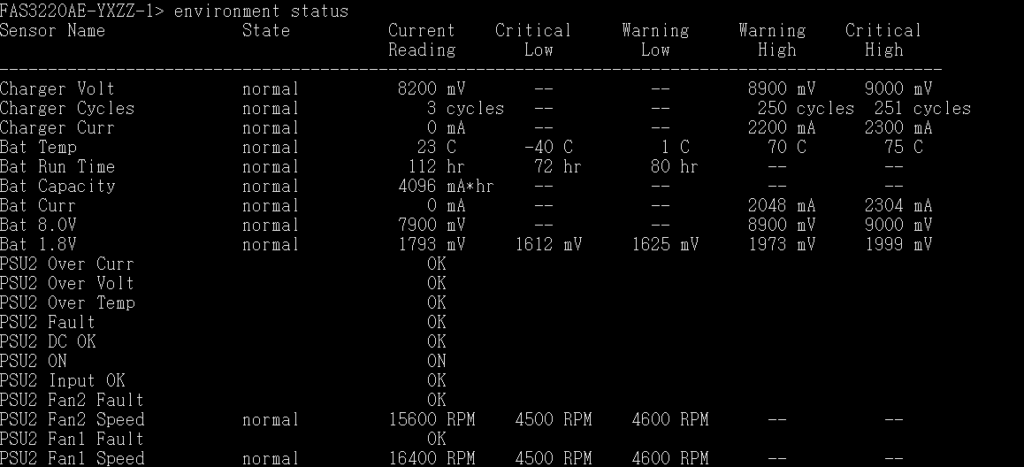
environment status
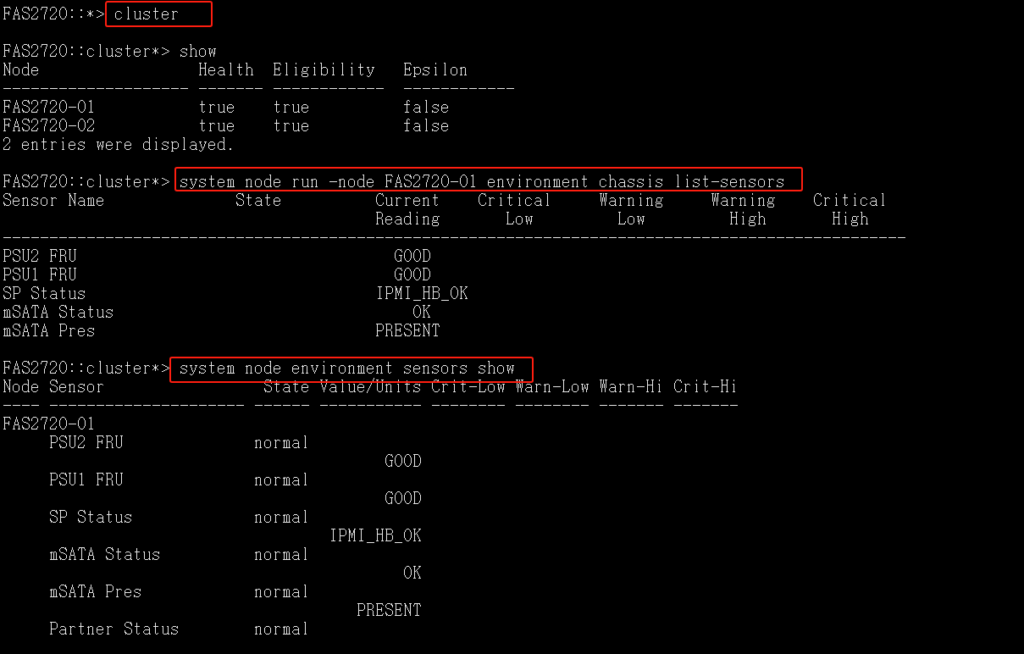
system node run -node FAS2720-01 environment chassis list-sensors
system node environment sensors show
转载链接:https://blog.51cto.com/tech4fei/1913547#:~:text=%E9%9A%8F%E7%9D%80%E5%85%AC%E5%8F%B8%E7%9A%84%E4%B8%9A%E5%8A%A1%E5%8F%91%E5%B1%95%EF%BC%8C
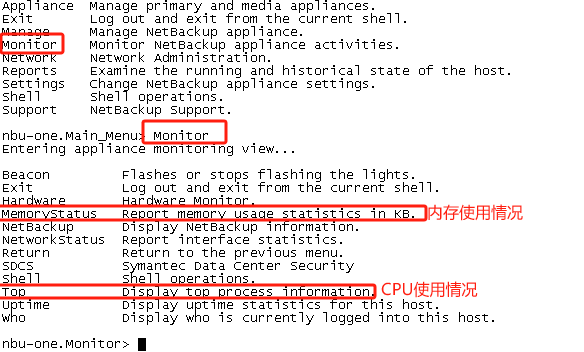
此链接看存储状态性能情况
https://blog.csdn.net/xiao_xx/article/details/136608791
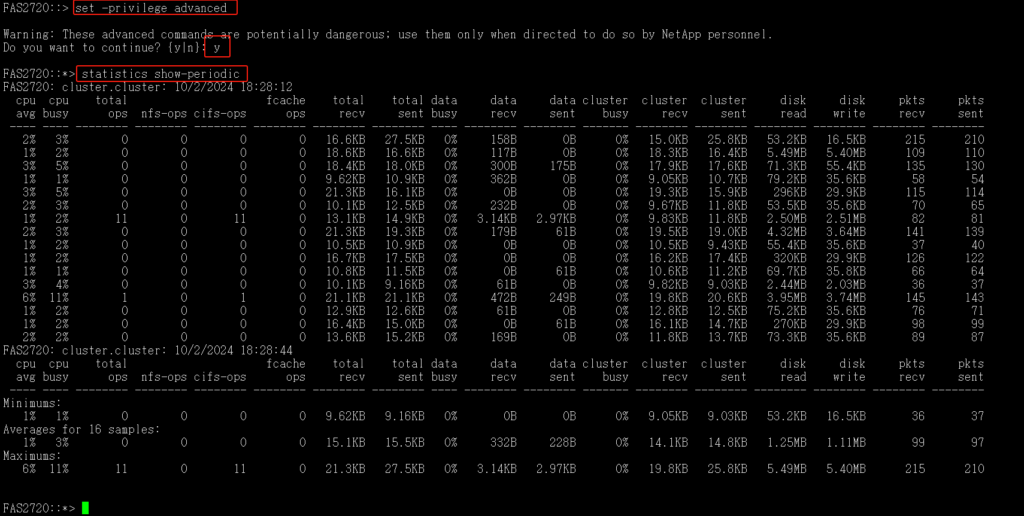
CPU使用情况查看:
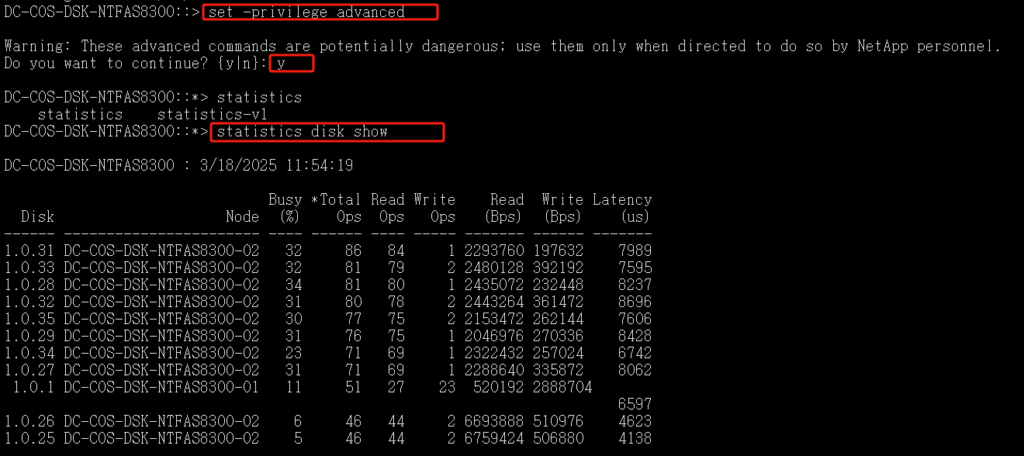
set -privilege advanced 或者priv set advanced该命令进入高级模式 按键y
statistics show-periodic 查看当前系统实时性能指标
磁盘使用情况查看:
set -privilege advanced 或者priv set advanced 该命令进入高级模式 按键y
statistics disk show 查询各个磁盘的延迟

参考链接:
https://blog.csdn.net/sjj222sjj/article/details/122763402
https://www.cnblogs.com/pipci/p/12699367.html
https://www.cnblogs.com/pipci/p/12672691.html
https://www.cnblogs.com/wanghongwei-dev/p/17573517.html
一个是基于WWPN/Alias,一个是基于物理端口,两种方式各有优劣,可根据实际情况进行选择,主要的区别在于以下两个场景:
1、当服务器HBA卡出现故障或者更换HBA卡过后,基于WWPN的方式需要更改配置中的相关WWPN号,而基于端口的方式无需更改任何配置
2、当SAN交换机接口出现故障需要更换端口时,基于端口的方式就需要重新更改端口进Zone,而此时基于WWPN的方式则配置无需做任何改动
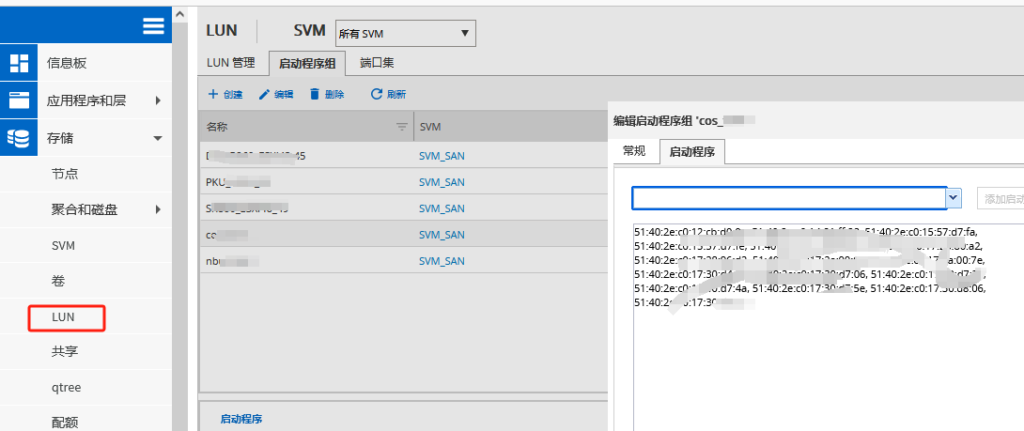
本案例是基于WWPN/Alias
旧HBA卡WWPN号

更换后新的HBA卡WWPN号

根据旧的WWPN找到对应的别名(alias)
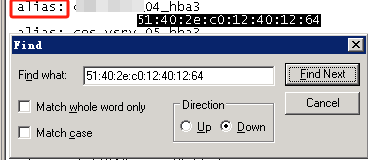
aliadd “cos_vsrv_04_hba3″,”51:40:2e:c0:14:81:ff:20”
##向别名中添加一个成员,如果别名不存在则不能添加 也可以别名中添加多个成员,用分号隔开
aliremove “cos_vsrv_04_hba3″,”51:40:2e:c0:12:40:12:64”
##在别名中移除一个成员,如果被移除的成员是最后一个成员,则移除后这个别名会被删除 也可以在别名中移除多个成员,用分号隔开
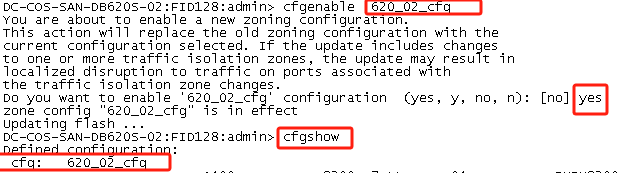
cfgenable 620_02_cfg
##cfgenable 配置文件名 不执行此命令cfgshow查看到的Effective configuration (有效的配置) 依然是旧的WWPN号 需要执行此命令让其做的操作生效
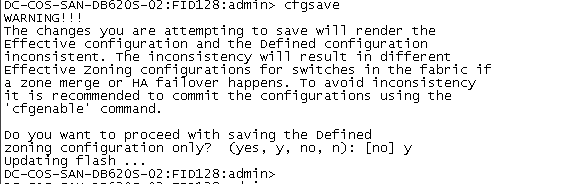
cfgsave
##保存所有配置 否则交换机重启会丢失之前配置
当需要更换故障HBA卡时,并且通过wwpn方式划分的zone,在更换前最好把新HBA卡的wwpn加入到旧的别名中后,再移除故障HBA卡的wwpn
更换HBA卡后是需要将两个WWPN号都更换51:40:2e:c0:12:40:12:64,51:40:2e:c0:12:40:12:66这里我举例子只列出了更换51:40:2e:c0:12:40:12:64的
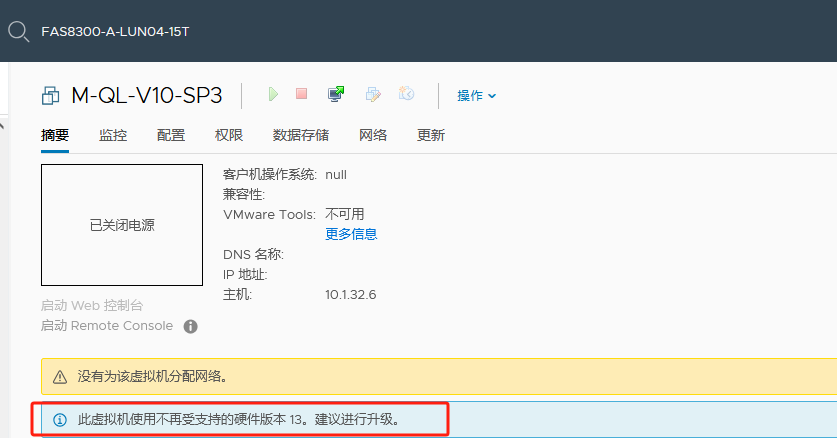
将新vcenter上创建的模版机注册到旧vcenter上 提示:
此虚拟机使用不再受支持的硬件版本13建议进行升级
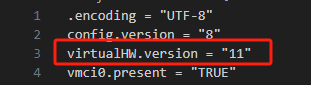
我的ESXI版本是6.0的其最高支持虚拟机硬件11版本 而模版机的硬件版本要高
也就是说vmx文件virtualHW.version = “11” 改为11
链接:https://knowledge.broadcom.com/external/article?legacyId=2007240
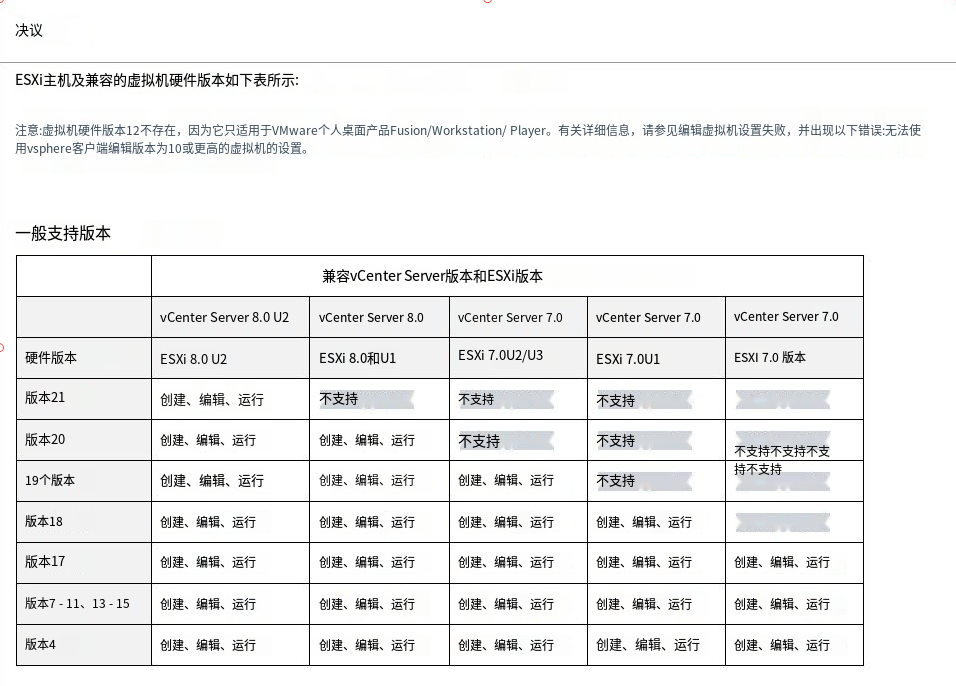
若有syslogadmin命令 请参考
syslogdipadd IP 配置syslog外送IP地址
syslogdipshow 查看syslog外送IP地址
syslogdfacility 查看本地log等级 加-l 指定等级[0-7]
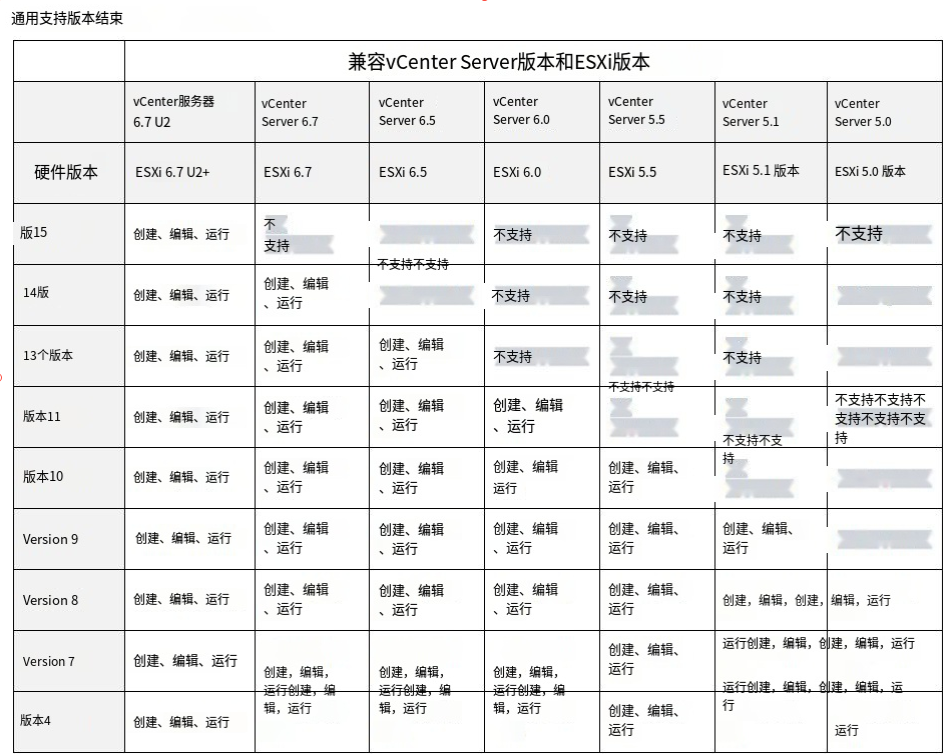
(建议)开启审计日志(AUDIT log),对于一些配置的记录更加详尽。
命令语法如下截图。
auditcfg –enable //启用审计日志
auditcfg –severity INFO //审计日志最低级别设置为INFO,可选范围为INFO, WARNING, ERROR, CRITICAL
auditcfg –class 1,2,3,4,5,7,8,9 //配置所有类别的操作均生成审计日志,可选范围为1-ZONE, 2-SECURITY, 3-CONFIGURATION, 4-FIRMWARE, 5-FABRIC, 7-LS, 8-CLI, 9-MAPS
auditcfg –show //查询审计日志配置结果
syslogadmin –show -ip查看当前配置
syslogadmin –set -ip添加syslog服务器地址,支持UDP和TCP协议,使用TCP协议参考上面链接,建议选择UDP协议。默认使用UDP协议 514端口
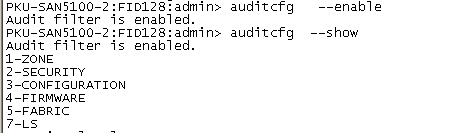
(建议)开启审计日志(AUDIT log),对于一些配置的记录更加详尽。
命令语法如下截图。
auditcfg –enable //启用审计日志
auditcfg –severity INFO //审计日志最低级别设置为INFO,可选范围为INFO, WARNING, ERROR, CRITICAL
auditcfg –class 1,2,3,4,5,7,8,9 //配置所有类别的操作均生成审计日志,可选范围为1-ZONE, 2-SECURITY, 3-CONFIGURATION, 4-FIRMWARE, 5-FABRIC, 7-LS, 8-CLI, 9-MAPS
auditcfg –show //查询审计日志配置结果
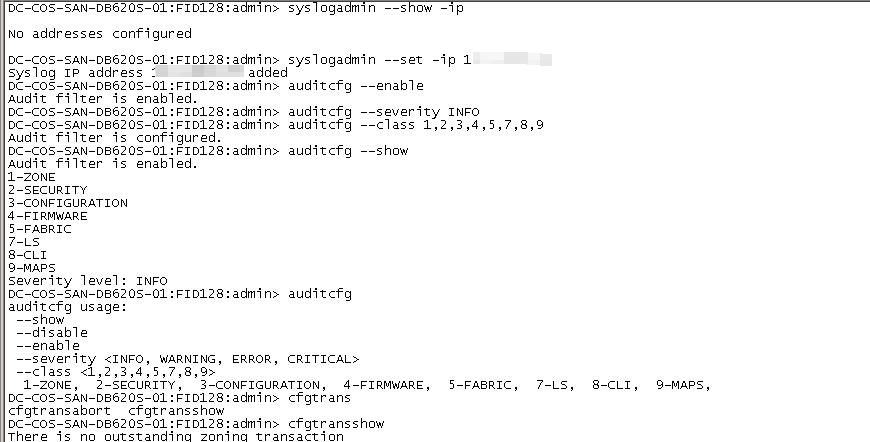
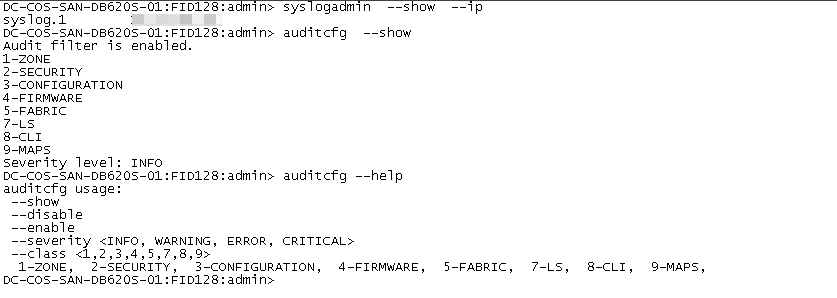
来自于厂商给的文档
NBU备份一体机从3.2版本开始提供了一个通过网页方式下载日志的方法,具体步骤如下:
登录一体机clish命令行,收集DataCollect日志:
Main_Menu>Support> DataCollect 注:如果版本为3.3.0.2MR2或者4.1.0.1MR2~5.0,建议执行 Main_Menu>Support> DataCollect v1
打开网页共享(有效时长12小时):
Main_Menu>Support> LogBrowser Start
通过网页浏览器访问如下地址,使用admin用户和密码登录:
https://一体机IP地址/appliance/logs/
下载DataCollect日志(针对3.2~3.3.0.2MR1和4.0~4.1.0.1MR1版本):
将页面下方的每页显示条目从默认的“5”改为“20”,导航到第二页或者第三页,找到“DataCollect.zip”文件:
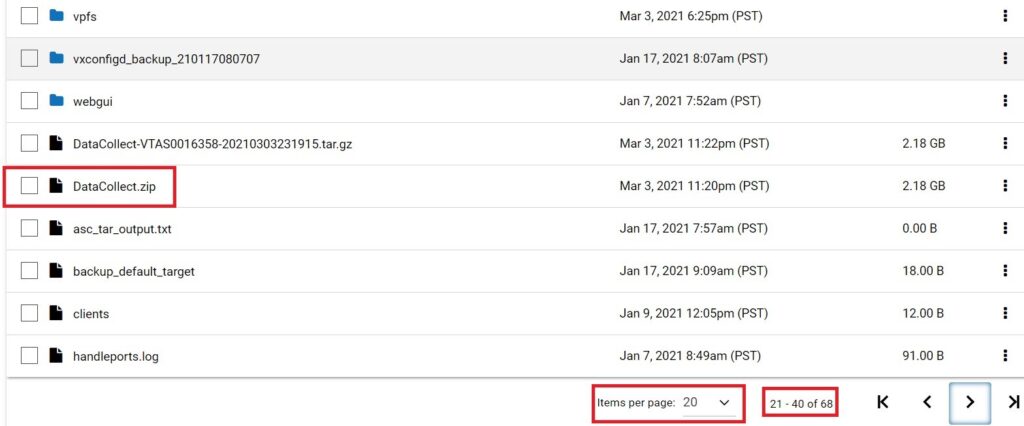
选中该文件后点击右面的“Download”下载:
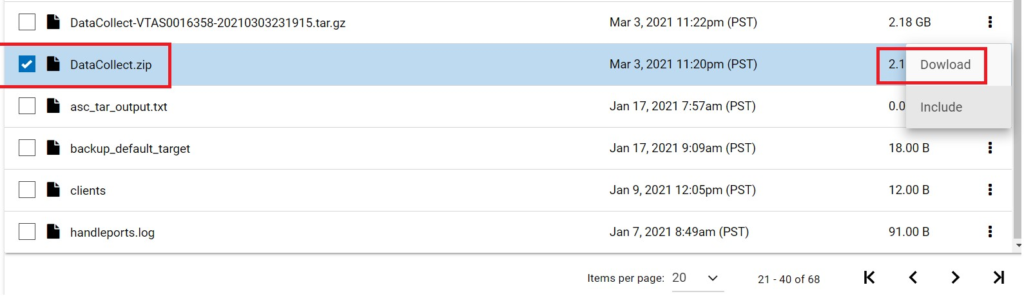
注:某些新版本(例如5.1.1)上收集DataCollect日志后,会生成到 datacollect 文件夹下,进入该文件夹,下载后缀为 xxx.tar.xz 的文件


未执行
执行重新扫描scsi设备
ls /sys/class/scsi_device/
1:0:0:0 2:0:0:0
echo 1 > /sys/class/scsi_device/1\:0\:0\:0/device/rescan
echo 1 > /sys/class/scsi_device/2\:0\:0\:0/device/rescan
执行之后
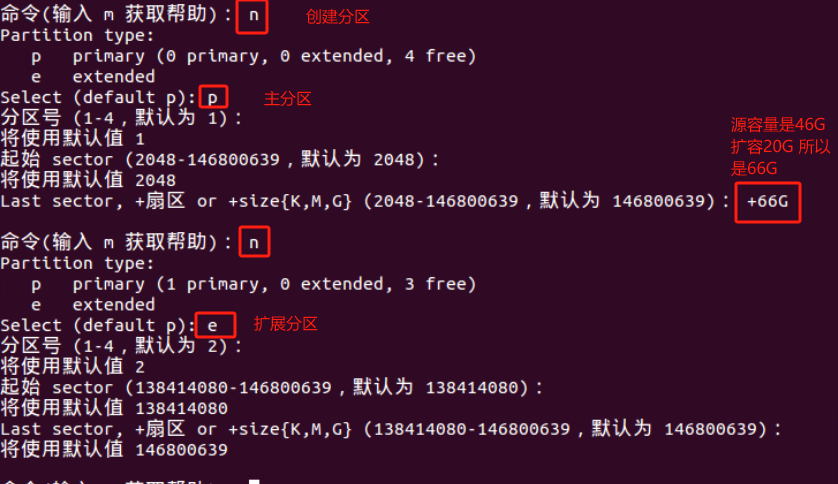
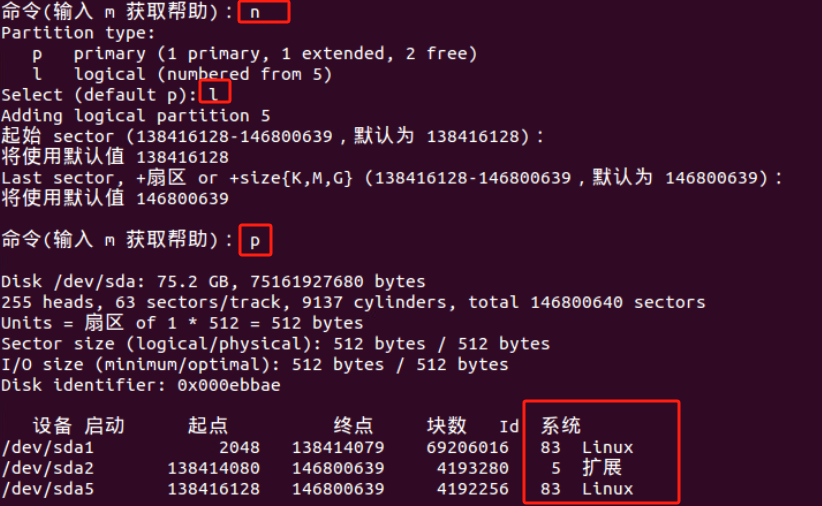
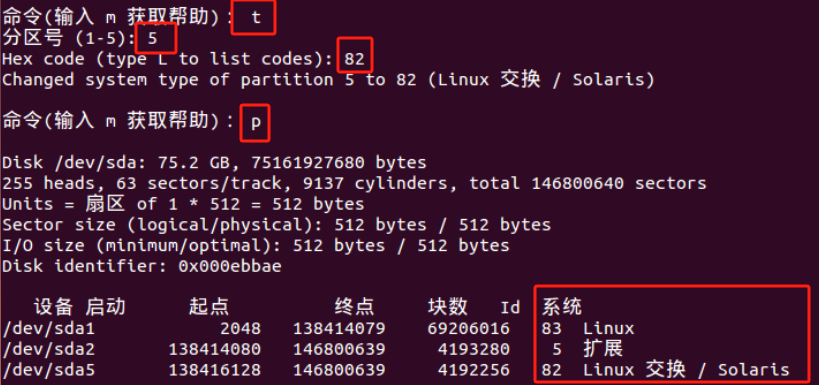
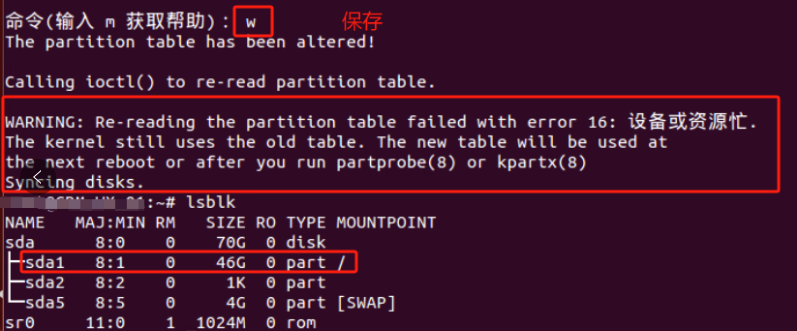
WARNING: Re-reading the partition table failed with error 16: 设备或资源忙.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
警告:重新读取分区表失败,错误16:设备或资源忙。
内核仍然使用旧的表。新桌子将在
下次重新启动或运行partprobe(8)或kpartx(8)之后
同步磁盘。
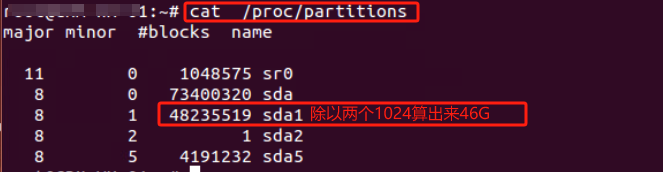
查看内核是否已经识别调整后的分区 cat /proc/partitions 如果内核没有识别调整后的分区表,我们需要重读磁盘分区表 告诉内核当前磁盘的分区情况 partx -u /dev/sda1
partx -u /dev/sda1命令是将partx –show /dev/sda1命令查看到存留在内存的分区情况重载给内核
执行完后partx:/dev/sda:error updating partition 1 报错没有解决 但重启机器后解决
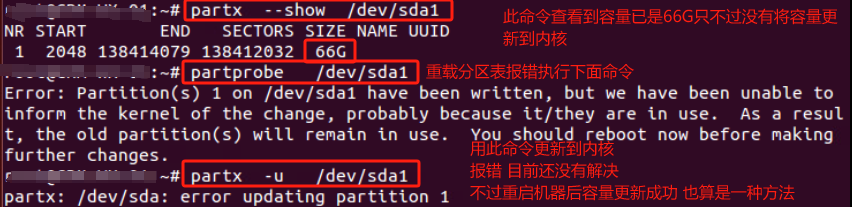
Error: Partition(s) 1 on /dev/sda1 have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result, the old partition(s) will remain in use. You should reboot now before making further changes.
错误:/dev/sda1上的分区1已被写入,但我们无法通知内核更改,可能是因为它/它们正在使用。因此,旧分区将继续使用。在进行进一步更改之前,您应该现在重新启动。
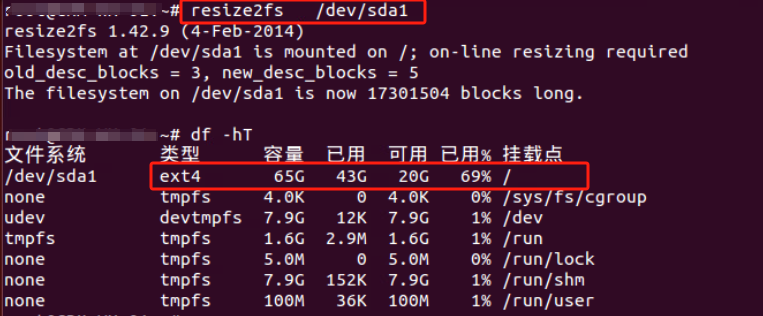
重启后lsblk看到已由46G更新为了66G
df -hT 看到文件系统大小还是46G 所以用resize2fs /dev/sda1 命令来重载文件系统大小
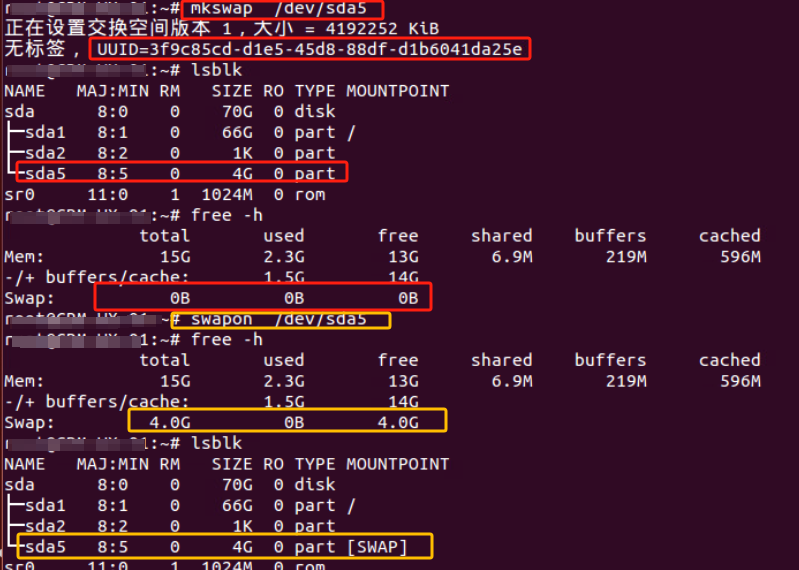
但发现sda5分区 没有了swap分区标识 有问题所以需要重建SWAP分区
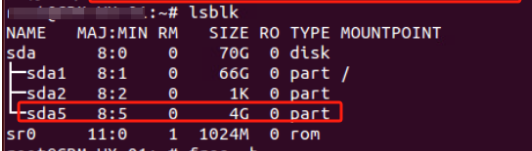
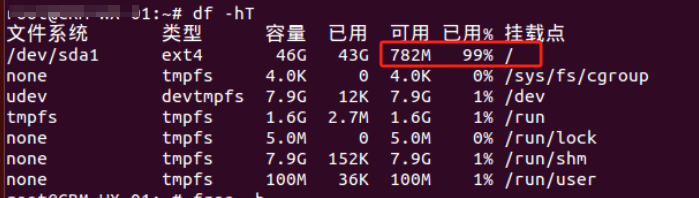
问题是我重启服务器后发现的 所以理论上 重启之前做这些操作更适合
参考链接:https://www.cnblogs.com/pipci/p/11413433.html
mkswap命令把分区格式化为swap分区
swapon /dev/sda5 使新添加的swap生效
swapon -s 显示swap的使用情况
将新添加的交换分区添加到/etc/fstab文件中使之开机启动 添加完后最好用swapon -a命令查看添加的是否有问题
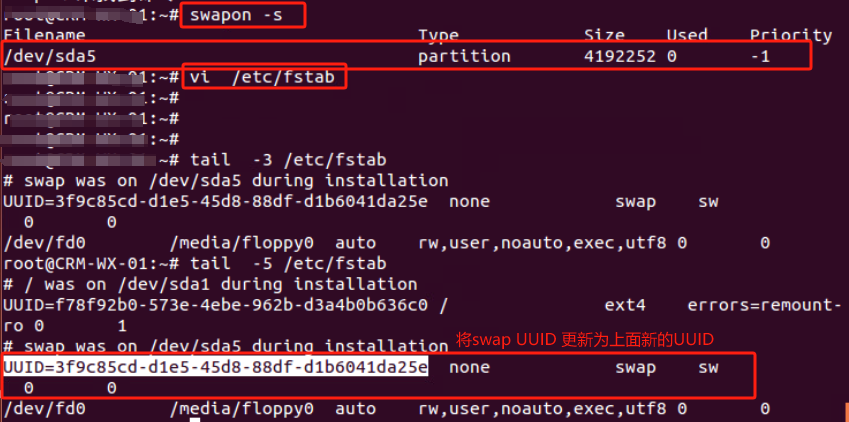
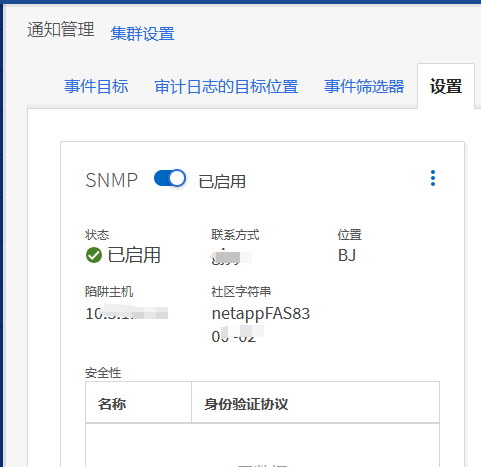
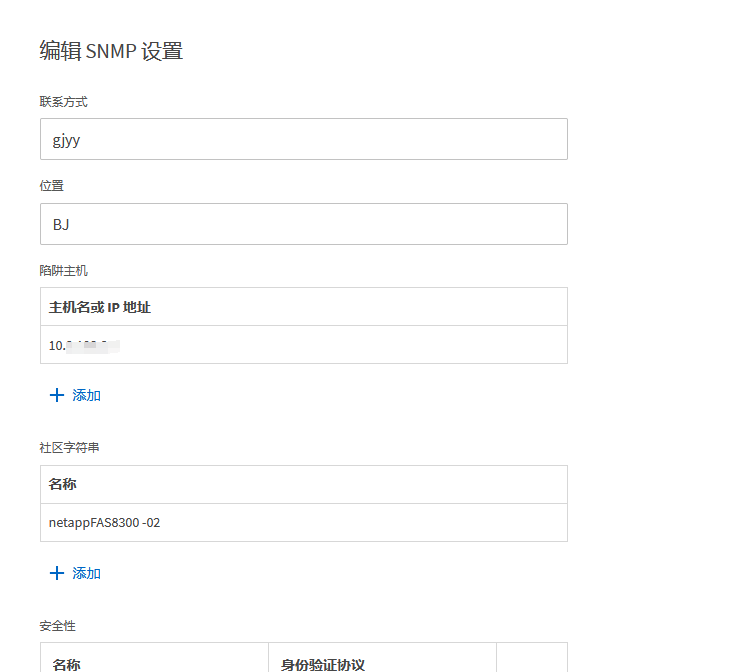
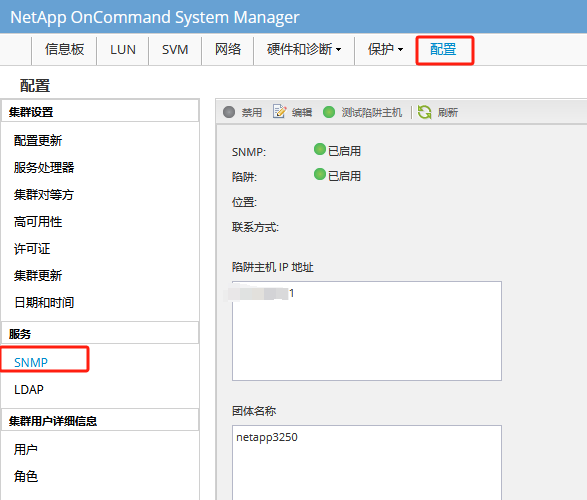
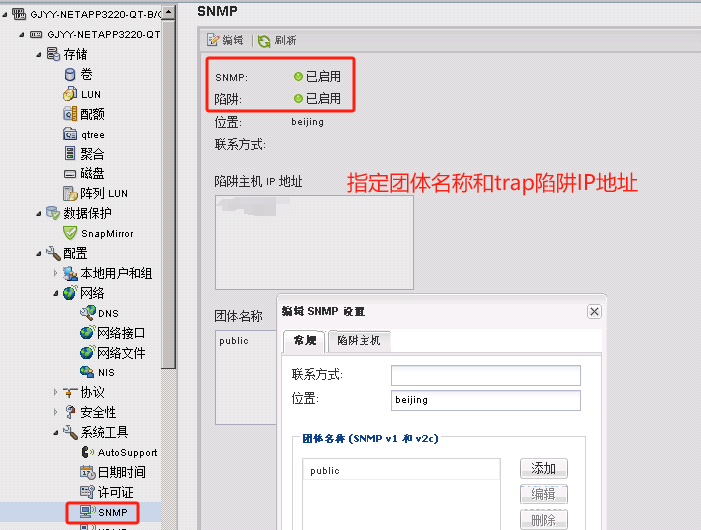
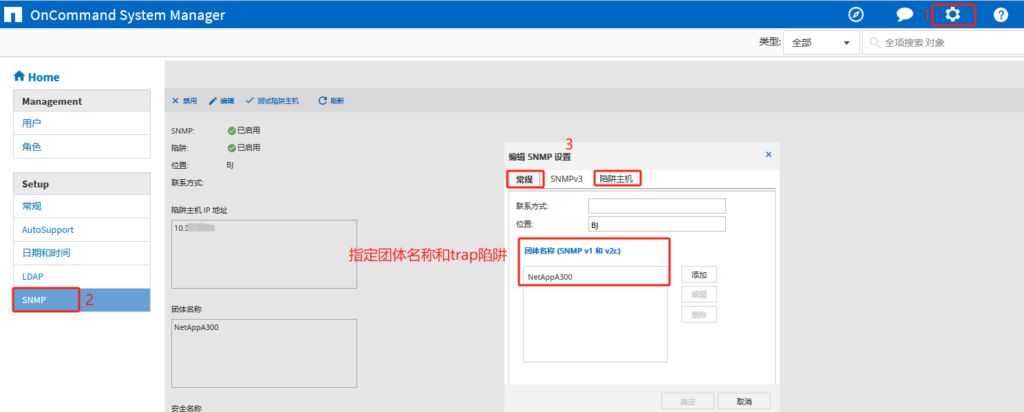
参考链接:https://info.support.huawei.com/info-finder/encyclopedia/zh/SNMP.html
https://support.huawei.com/enterprise/zh/knowledge/EKB1100115609
https://www.cnblogs.com/liulj0713/p/9895290.html
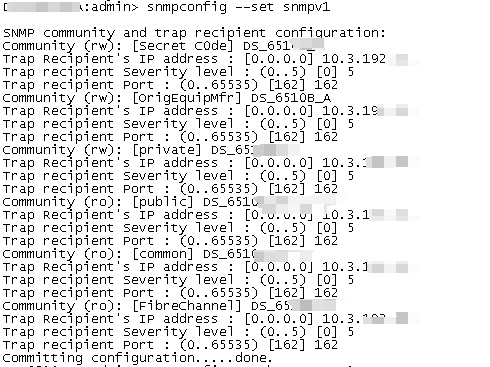
用以监测连接到网络上的设备是否有任何引起管理上关注的情况。通过“利用网络管理网络”的方式:
SNMP有三种版本:SNMPv1,SNMPv2c和SNMPv3。
SNMP端口是SNMP通信端点,SNMP消息传输通过UDP进行,通常使用UDP端口号161/162。有时也使用传输层安全性(TLS)或数据报传输层安全性(DTLS)协议
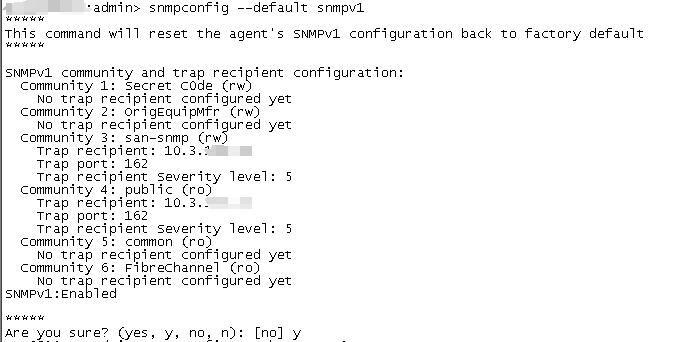
snmpconfig –default snmpv1
This command will reset the agent’s SNMPv1 configuration back to factory default
该命令将复位代理的SNMPv1配置回出厂默认值
snmpconfig –enable snmpv1
snmpconfig –set snmpv1
community:设置团体字
severity:配置发送Trap的级别,有效值为0-5,默认值为0
0表示不发送,2表示发送Error,Critical级别,3表示发送Warning,Error,Critical级别,4表示发送Informational,Warning,Error,Critical级别。
• 0: None
• 1: Critical
• 2: Error
• 3: Warning
• 4: Informational
• 5: Debug
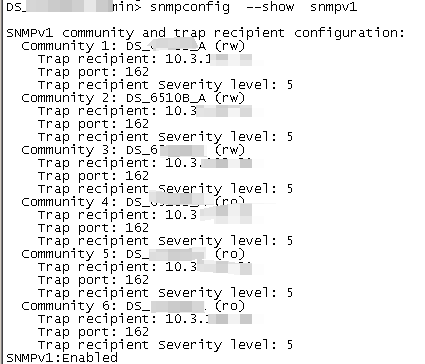
snmpconfig –show snmpv1
admin> snmptraps –send -ip_address 10.3.1xx.xx
Number of traps sent : 28
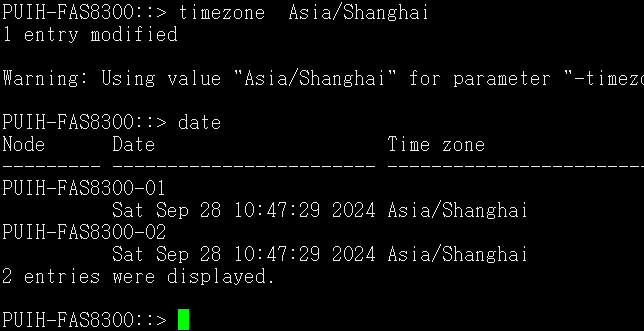
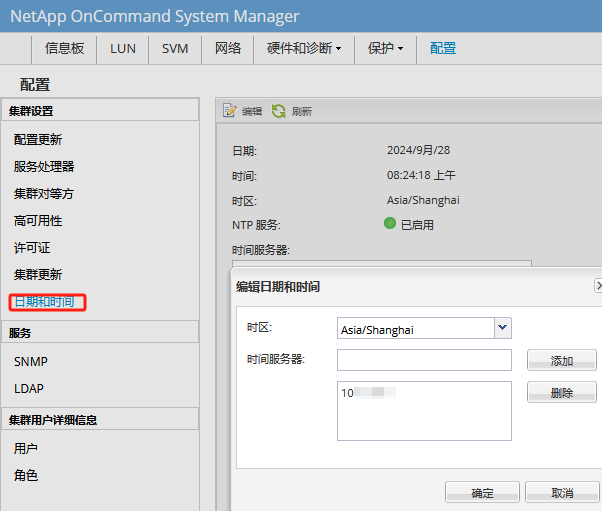
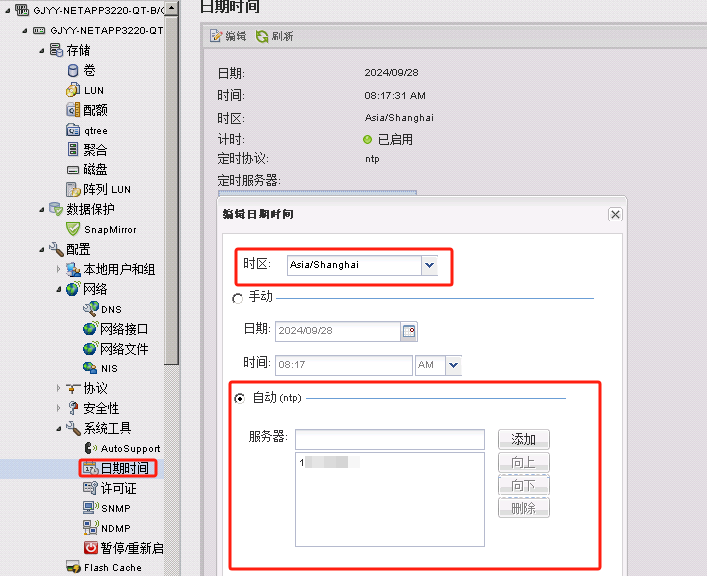
admin> date ###查看当前时间
Tue Sep 3 06:22:57 UTC 2024
admin> tstimezone ###查看当前时间时区 无
Time Zone Hour Offset: 0
Time Zone Minute Offset: 0
admin> tstimezone Asia/Shanghai ###设置时间时区为亚洲上海
System Time Zone change will take effect at next reboot ###提示:系统时区更改将在下次重新启动时生效
我更改3组不同型号的SAN交换机 验证出来 当改完时区有的SAN交换机直接由UTC(世界标准时间)更改为了CST(北京时间) 有的其他型号SAN交换机需要退出终端重新连接后才可以由UTC(世界标准时间)更改为了CST(北京时间)
admin> tstimezone ###查看当前时间时区
Asia/Shanghai
admin> tsclockserver “10.1.25x.x” ###设置NTP时间同步服务 交换机每隔64秒与NTP server同步一次。
Updating Clock Server configuration…done.
Updated with the NTP servers
admin> tsclockserver ###查看当前NTP时间同步服务地址
Active NTP Server 10.1.25x.x
Configured NTP Server List 10.1.25x.x
admin> tsclockserver “LOCL” ###设置NTP时间同步服务为LOCL(本地) 也可以理解为取消之前的NTP时间同步
admin> tsclockserver ###查看当前NTP时间同步服务地址
Active NTP Server LOCL
Configured NTP Server List LOCL
admin> tstimezone –interactive ###设置需要的时间时区
Please identify a location so that time zone rules can be set correctly.
Please select a continent or ocean.
1) Africa
2) Americas
3) Antarctica
4) Arctic Ocean
5) Asia 亚洲
6) Atlantic Ocean
7) Australia
8) Europe
9) Indian Ocean
10) Pacific Ocean
11) none – I want to specify the time zone using the POSIX TZ format.
Enter number or control-D to quit ?5
Please select a country.
1) Afghanistan 18) Israel 35) Palestine
2) Armenia 19) Japan 36) Philippines
3) Azerbaijan 20) Jordan 37) Qatar
4) Bahrain 21) Kazakhstan 38) Russia
5) Bangladesh 22) Korea (North) 39) Saudi Arabia
6) Bhutan 23) Korea (South) 40) Singapore
7) Brunei 24) Kuwait 41) Sri Lanka
8) Cambodia 25) Kyrgyzstan 42) Syria
9) China 中国26) Laos 43) Taiwan
10) Cyprus 27) Lebanon 44) Tajikistan
11) East Timor 28) Macau 45) Thailand
12) Georgia 29) Malaysia 46) Turkmenistan
13) Hong Kong 30) Mongolia 47) United Arab Emirates
14) India 31) Myanmar (Burma) 48) Uzbekistan
15) Indonesia 32) Nepal 49) Vietnam
16) Iran 33) Oman 50) Yemen
17) Iraq 34) Pakistan
Enter number or control-D to quit ?
1) Afghanistan 18) Israel 35) Palestine
2) Armenia 19) Japan 36) Philippines
3) Azerbaijan 20) Jordan 37) Qatar
4) Bahrain 21) Kazakhstan 38) Russia
5) Bangladesh 22) Korea (North) 39) Saudi Arabia
6) Bhutan 23) Korea (South) 40) Singapore
7) Brunei 24) Kuwait 41) Sri Lanka
8) Cambodia 25) Kyrgyzstan 42) Syria
9) China 26) Laos 43) Taiwan
10) Cyprus 27) Lebanon 44) Tajikistan
11) East Timor 28) Macau 45) Thailand
12) Georgia 29) Malaysia 46) Turkmenistan
13) Hong Kong 30) Mongolia 47) United Arab Emirates
14) India 31) Myanmar (Burma) 48) Uzbekistan
15) Indonesia 32) Nepal 49) Vietnam
16) Iran 33) Oman 50) Yemen
17) Iraq 34) Pakistan
Enter number or control-D to quit ?9
Please select one of the following time zone regions.
1) Beijing Time 北京时间
2) Xinjiang Time
Enter number or control-D to quit ?1
The following information has been given:
China
Beijing Time
Therefore TZ=’Asia/Shanghai’ will be used.
Local time is now: Tue Sep 3 14:07:07 CST 2024.
Universal Time is now: Tue Sep 3 06:07:07 UTC 2024.
Is the above information OK?
1) Yes
2) No
Enter number or control-D to quit ?1
admin> date ###最后更改完查看当前时间可以看到是CST(北京时间)
Tue Sep 3 14:23:47 CST 2024
转载于:https://www.cnblogs.com/hongzhuaxueni/p/5254762.html
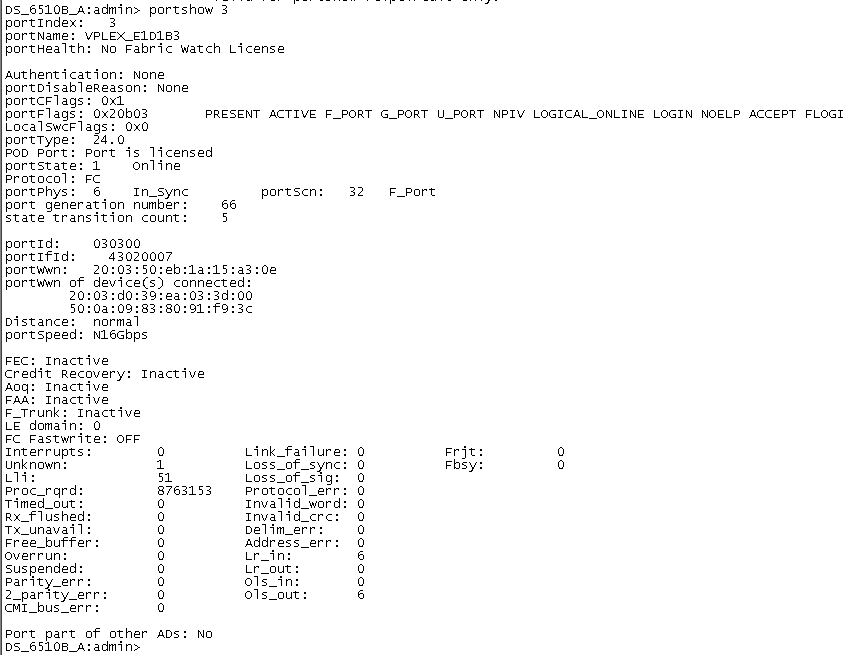
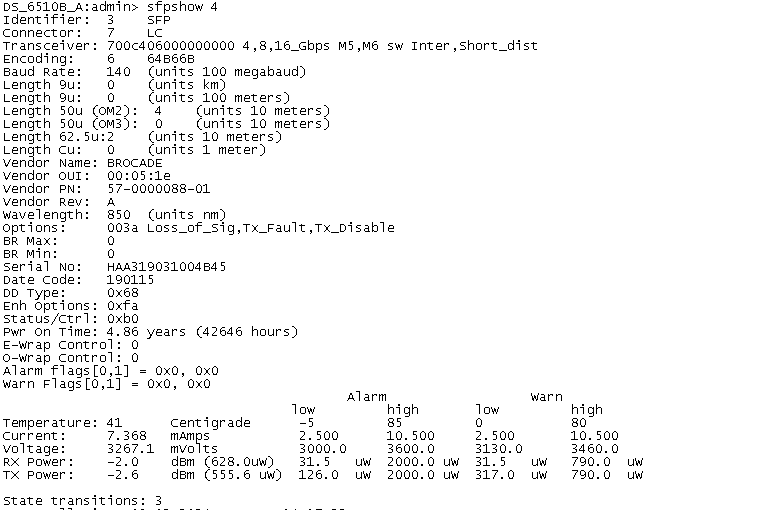
当计数器有效时,porterrshow的输出结果才有了意义
如下图0 和 23 端口crc_err报错值增长 经 更换两个端口的模块解决问题
为了方便查看是否有报错增长值使用portstatsclear +端口号命令清除该端口的报错值
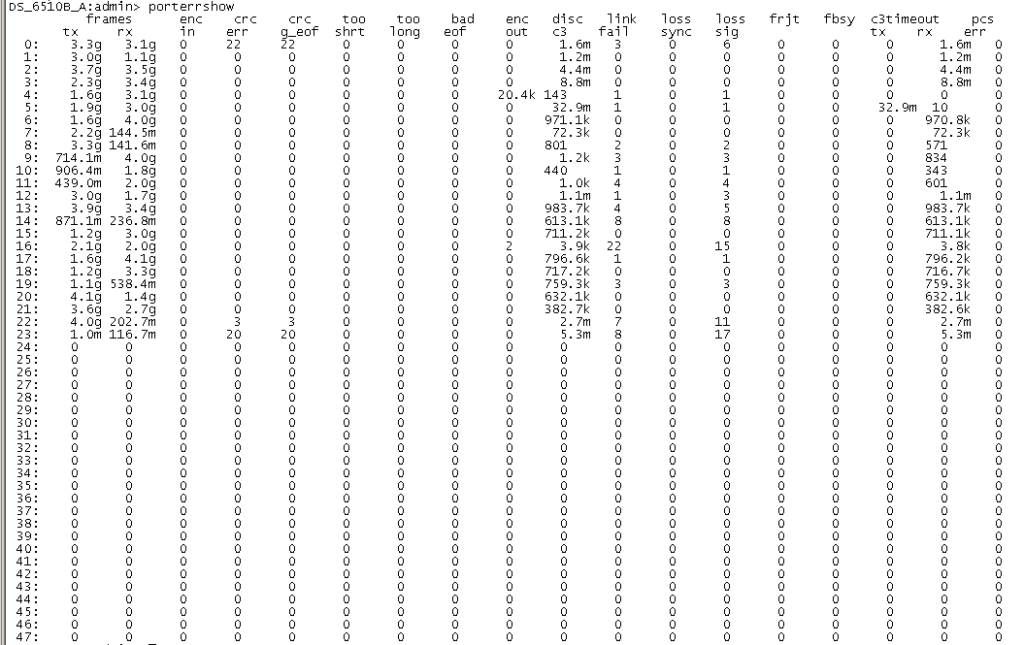
接下来我们解释一下各项指标代表的含义,以及我们在看到该项指标时都在关注些什么
frames tx/rx: tx代表端口发送的数据帧,rx代表端口收到的数据帧。这两个值反映了通过该端口的数据流量,通常可用来粗略判断哪些端口为使用中,哪些端口为闲置状态。
enc_in: 8bit/10bit数据帧帧内的编码错误。数据的损坏会造成该值增长,因此该项指标用于标记数据帧内的编码错误。有时相连末端设备重置/重启也会造成该值增长。
crc_err: 数据帧 CRC 校验错误。数据帧在Payload之后,在EOF (end of frame)之前会添加一个可用于接收端口校验所接收数据是否损坏的校验码。若数据帧损坏,接收端会发现该值不一致,继而该报错值增长。
crc_g_eof: 数据帧 CRC 校验错误,且数据帧 EOF是好的。当数据帧首次被交换机检测到CRC错误时,交换机在转发该帧时,会把EOF置为bad(EOFni);所以后续接收该帧的交换机的端口上,只会有crc_err增长,而crc_g_eof的值保持不变,这样就能很直观的找到产生CRC错误的源头。
too_long: 通常FC数据帧最大为 2148 字节。若EOF损坏或数据帧生成不正确,则该值随之增长。
too_short: 如果在SOF (start of frame) 和EOF间的长度小于28(24 Header+ 4 CRC)个字节,则该值随之增长。数据发送方故障和链路的不稳定均可能造成该计数器的增长。
bad_eof: 数据帧 EOF 报错。
enc_out: 8bit/10bit 数据帧帧外编码错误造成的错误值累积,通常反映了线缆质量问题,或末端设备异常。此外,由于末端设备的重启带来的端口上下线也可能会引起enc_out的增长。
disc c3: Class 3数据帧被交换机丢弃。若目标地址不可达或者源端口还没有登录到交换机,以及由于拥塞产生超时丢帧(timeout discards)后,该值均会增长。这个参数仅仅代表有丢包发生,但不能说是这个端口本身存在故障。在Brocade Fabric OS微码版本v6.3.1之前,c3 timeout discards值是不分方向的,v6.3.1之后被分为er_rx_c3_timeout和er_tx_c3_timeout两项,rx表示接收数据,tx表示发送数据。当端口发送或者接收帧之后,会消耗掉相应的方向上的缓存,Buffer-to-Buffer credit值减少。如果超过500毫秒(默认情况下,依配置不同可能会有改变)credit值始终为0,则认为后续分发动作无法完成,丢弃尚在缓存中的帧,计数器值增加。有大量er_tx_c3_timeout数值累积的F_Port通常为性能问题的故障点,也就是我们常说的瓶颈设备。关于瓶颈设备的检查,请参照之前的Blog“如何在博科交换机的SAN环境中排查瓶颈设备(Slow Drain Device)?”:https://community.emc.com/community/support/chinese/storagehw/blog
link fail: 当交换机端口在 LR (Link Reset)接收状态的时间超过 R_A_TOV值时,该错误计数器增长。Link Reset的超时通常会导致Link Failure,且该状态通常说明端口loss of signal 或loss of sync的时长大于R_A_TOV。
loss sync: bit 或者 transmission-word无法被准确区分确认时会引起信号同步失败。末端设备的重启,光纤线的拔插,或交换机端口的上下线均可能带来该问题。
loss sig: 接收方没有成功收到信号。与loss sync类似,末端设备的重启,光纤线的拔插,或交换机端口的上下线都有可能信号的丢失。
link fail, loss sync, loss sig这三个报错在链路初始化的过程中都会产生。而当链路不稳定时,这些错误计数值通常也会随之增长。
frjt: class 2数据帧无法处理时会返回F_RJT报错。
fbsy: class 2数据帧无法在E_D_TOV时间内处理时会被丢弃并返回F_BSY报错。
frjt和fbsy用于 class 2。通常说来,FC SAN多用class 3数据帧,因此这两类错误较少见,一般多出现在FICON环境中。
porterrshow的输出结果能够使我们对当前网络中的所有端口报错有一个全局性的了解,当遇到具体问题时,还需查看日志中的其它输出以定位故障点。

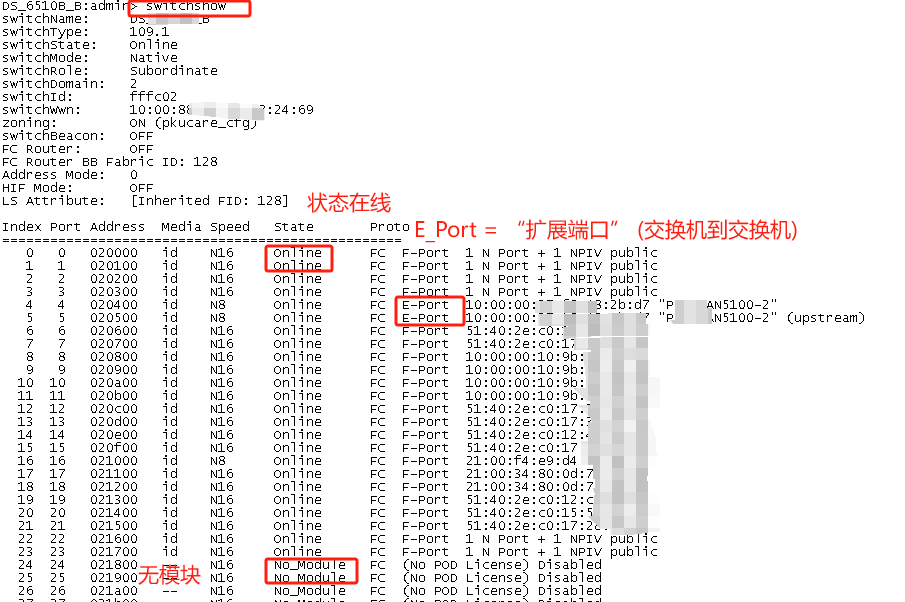

显示SAN交换机配置


cd /vmfs/volumes
vmkfstools -B naa.600a098038314e323424574fxxxxxxxx:1

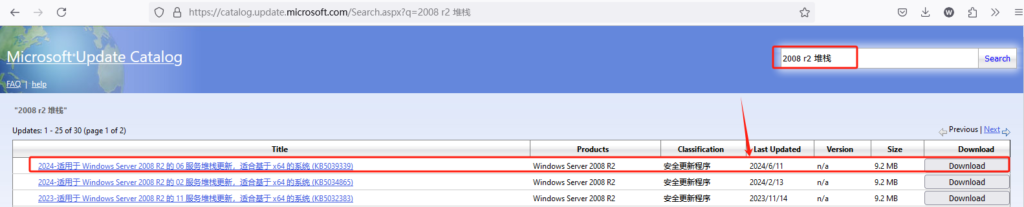
缺少最新的服务堆栈,下载最新的服务堆栈补丁,装上再安装其它补丁就不会再提示这个错误了。
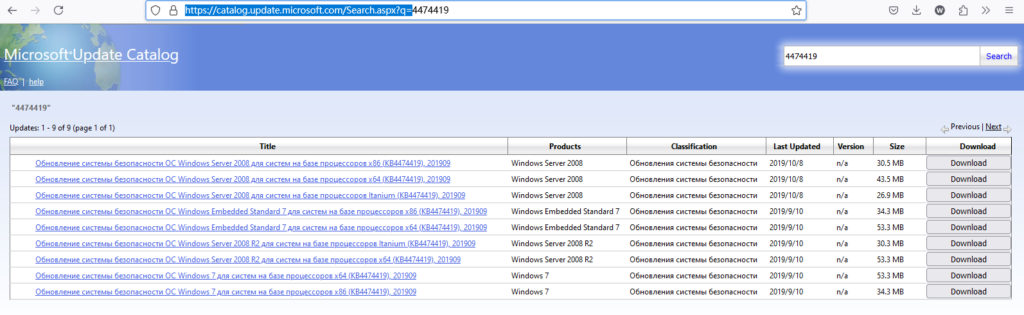
访问如下网址,找到最新的服务堆栈补丁下载安装即可
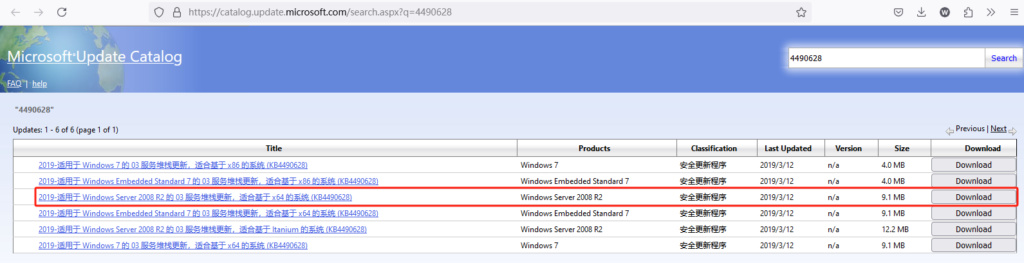
https://catalog.update.microsoft.com/Search.aspx?q= 访问此链接输入2008 r2 堆栈查找下载安装最新补丁即可
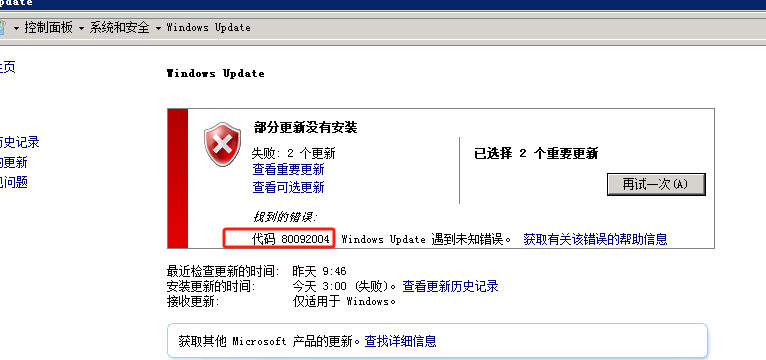
加密验证由 SHA1 改成 SHA2,在 SHA2 验证的这块发生了问题,因此出现 80092004 錯誤。从微软的说明来看,窗口 7 (2008 R2) 需要安装 KB4474419 和 KB4490628 这两个 KB,查了我的电脑,有安装 KB4474419,但缺了 KB4490628 所以下载 KB4490628补丁即可解决
参考链接:https://it-help.tips/zh/windows-7-update-80092004-error/
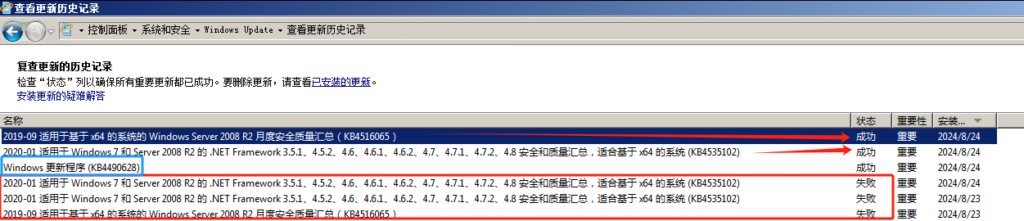
官方链接:https://catalog.update.microsoft.com/Search.aspx?q=4490628
根据网上资料修改注册表以及重置TCP都没有解决 误打误撞更新了补丁之后解决
如果在打sp1之前装了KB2667402补丁,打完SP1后重启系统远程桌面会连不上。
打补丁之前先看看有没有这个补丁,如果有需要先卸载这个补丁
一般来说sp1补丁都已打好
先安装sp1补丁包,再安装KB3020369,最后安装KB3125574。
可以粗略的理解为这些补丁作用是更新自动更新功能 不安装的话可能很难检测到更新
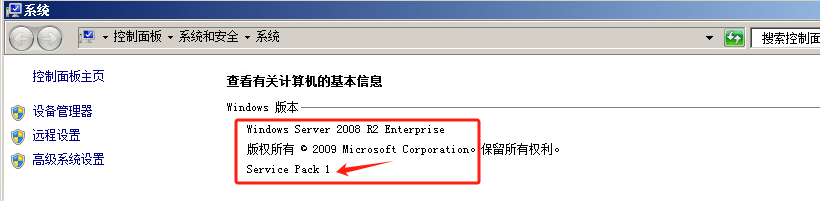
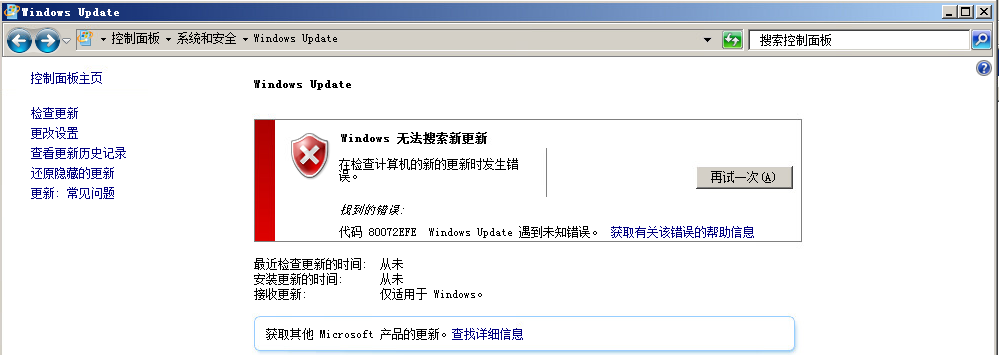
这些补丁作用是更新自动更新功能 不安装的话可能很难检测到更新
如果在打sp1之前装了KB2667402补丁,打完SP1后重启系统远程桌面会连不上。
打补丁之前先看看有没有这个补丁,如果有需要先卸载这个补丁
一般来说sp1补丁都已打好
先安装sp1补丁包,再安装KB3020369,最后安装KB3125574。
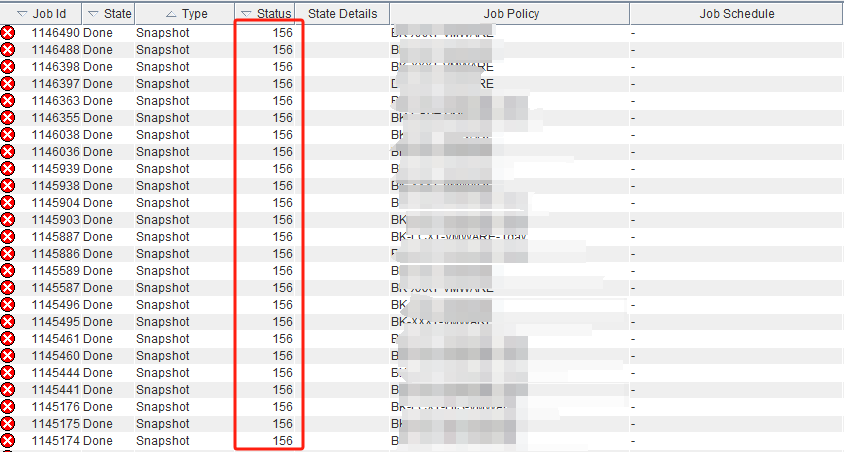
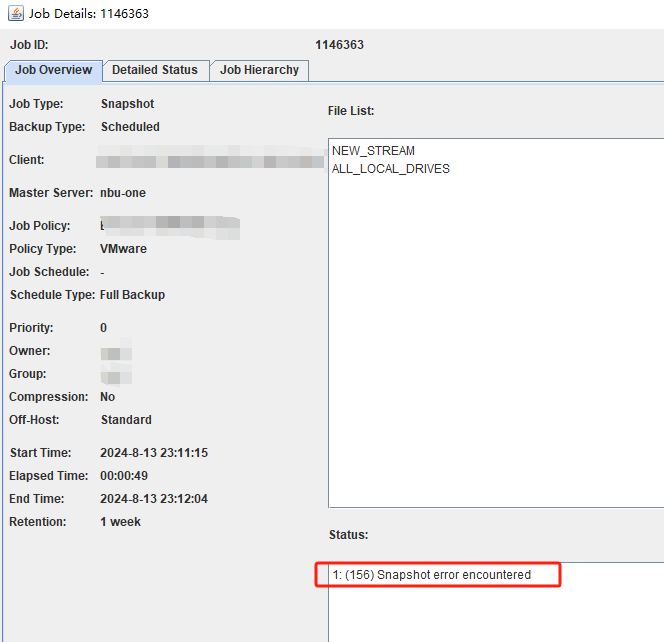
VMWARE 虚拟机备份过程中 虚拟机做静默快照失败问题导致156状态码报错
解决创建静默快照失败问题
参考链接:
转载于:https://blog.csdn.net/weixin_43570089/article/details/104892686
1、检查虚拟机所在数据存储可用空间是否充足?
2、检查虚拟机VMTools是否正常运行状态?
3、检查虚拟机上是否安装了最新版的 VMware Tools?
4、在VMware Tools升级过程中必须明确指定VSS组件,VSS不能以非交互模式安装。
5、尝试手动为虚拟机创建静默快照,是否成功?
6、检查备份及创建静默快照时Windows必要服务是否正常运行?
需确保以下服务在备份期间运行正常,详细服务列表如下:
1) COM+ System Application 列为“已启动”,且启动类型列为“手动”。
2) COM+ Event System 服务列为“已启动”,且启动类型列为“自动”。
3) Volume Shadow Copy 服务可以为已启动,且启动类型列为“手动”。
4) Microsoft Software Shadow Copy Provider 服务的启动类型列为“手动”。
5) VMware Snapshot Provider 列为“已启动”,且启动类型列为“手动”。
6)Virtual Disk 列为“已启动”,且启动类型列为“手动”。
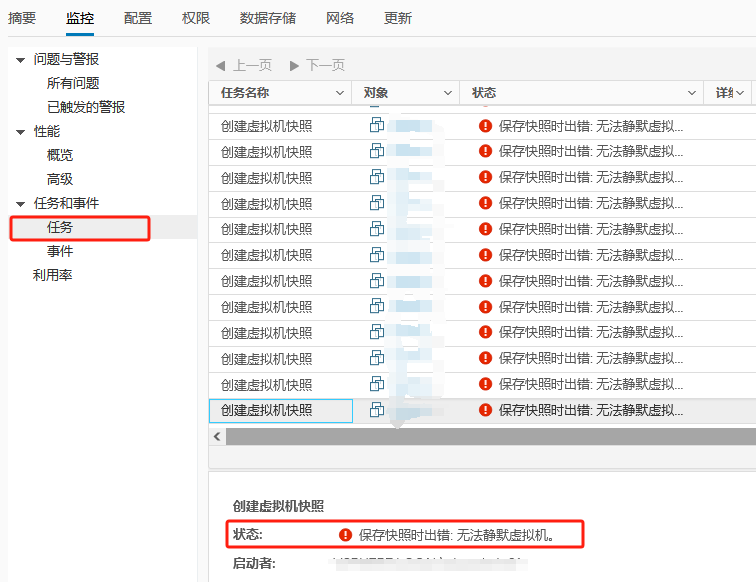
任务中创建快照报错:保存快照时出错: 无法静默虚拟机。
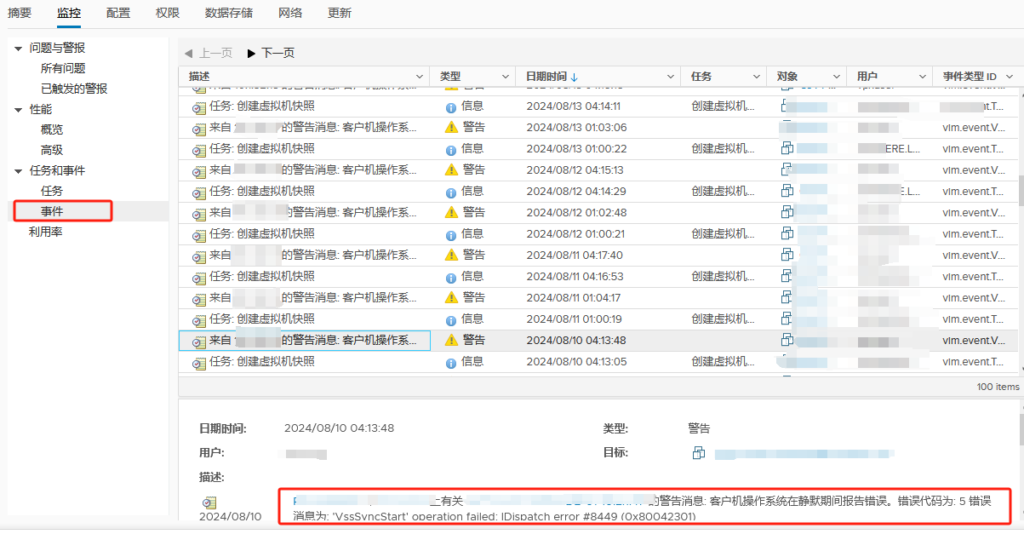
事件报错:客户机操作系统在静默期间报告错误。错误代码为: 5 错误消息为: ‘VssSyncStart’ operation failed: IDispatch error #8449 (0x80042301)
根据排查条件挨个排查重启服务器解决
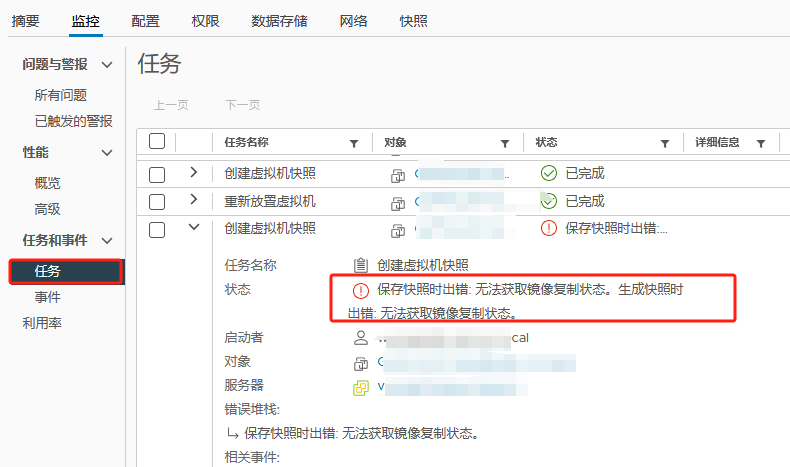
任务中创建快照报错:保存快照时出错: 无法获取镜像复制状态。 生成快照时出错: 无法获取镜像复制状态。
迁移虚拟机计算资源到其他ESXI主机后成功解决
转载于:https://blog.csdn.net/weixin_43570089/article/details/104892686
1、检查虚拟机所在数据存储可用空间是否充足?
2、检查虚拟机VMTools是否正常运行状态?
3、检查虚拟机上是否安装了最新版的 VMware Tools?
4、在VMware Tools升级过程中必须明确指定VSS组件,VSS不能以非交互模式安装。
5、尝试手动为虚拟机创建静默快照,是否成功?
6、检查备份及创建静默快照时Windows必要服务是否正常运行?
需确保以下服务在备份期间运行正常,详细服务列表如下:
1) COM+ System Application 列为“已启动”,且启动类型列为“手动”。
2) COM+ Event System 服务列为“已启动”,且启动类型列为“自动”。
3) Volume Shadow Copy 服务可以为已启动,且启动类型列为“手动”。
4) Microsoft Software Shadow Copy Provider 服务的启动类型列为“手动”。
5) VMware Snapshot Provider 列为“已启动”,且启动类型列为“手动”。
6)Virtual Disk 列为“已启动”,且启动类型列为“手动”。
升级VMWARE-tools后解决(此案例由10.0.6版本升级到12.0.0版本)
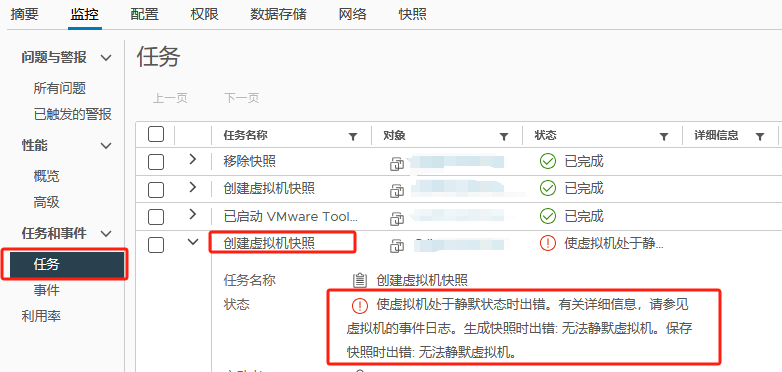
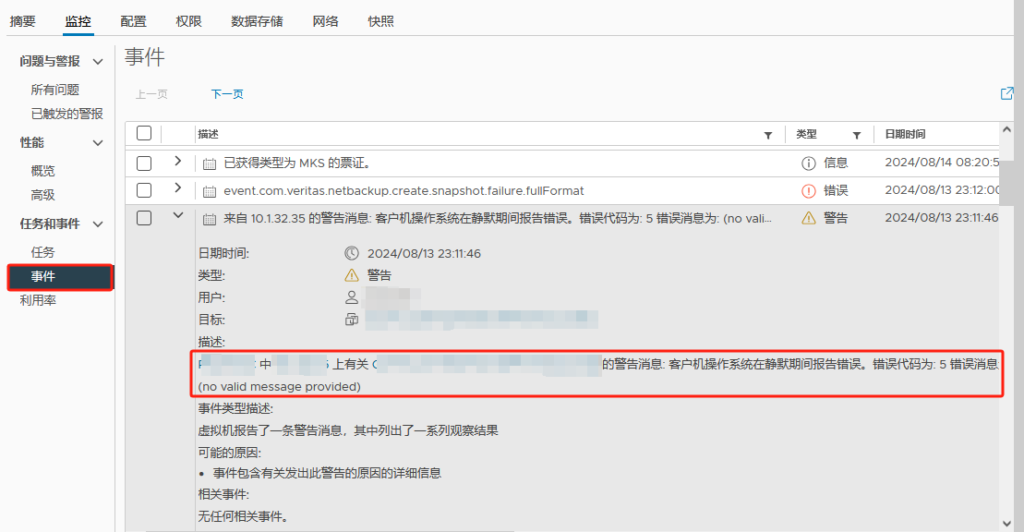
任务中创建虚拟机快照报错:使虚拟机处于静默状态时出错。有关详细信息,请参见虚拟机的事件日志。 生成快照时出错: 无法静默虚拟机。 保存快照时出错: 无法静默虚拟机。
事件报错:客户机操作系统在静默期间报告错误。错误代码为: 5 错误消息为: (no valid message provided)

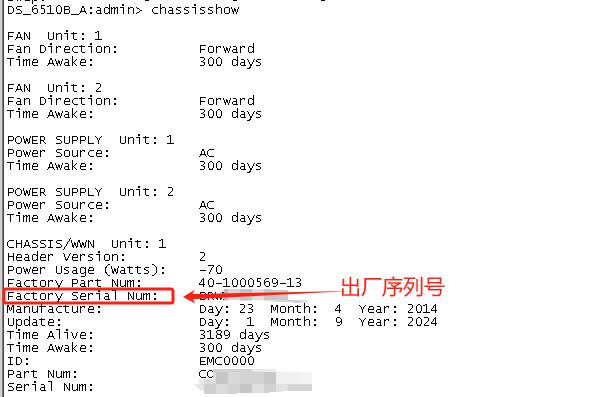
disk show -broken看坏(failed)盘

联系厂商 让厂商发盘 找到对应盘槽把坏盘拔下 插入新盘
FAS3250-DR-KF::> system node run FAS3250-DR-KF-01 ##上面看到盘是在控制器FAS3250-DR-KF-01 所以进到该控制器
FAS3250-DR-KF-01> disk show -v ###查看盘的状态信息
0a.23.23 Not Owned NONE KWKDB13U Block
FAS3250-DR-KF-01> disk assign 0a.23.23 -o FAS3250-DR-KF-01 ###disk assign 磁盘位置 -o 控制器名称 指定拥有控制器
FAS3250-DR-KF-01> disk show -v
0a.23.23 FAS3250-DR-KF-01(2015180633) Pool0 KWKDB13U FAS3250-DR-KF-01(2015180633) Block
FAS3250-DR-KF-01> aggr status -s ###aggr status -s 查看到spare盘还未零格式化(置零)not zeroed
Pool1 spare disks (empty)
Pool0 spare disks
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
——— —— ————- —- —- —- —– ————– ————–
Spare disks for block checksum
spare 0a.23.6 0a 23 6 SA:A 0 SAS 10000 560000/1146880000 572325/1172123568
spare 0a.23.23 0a 23 23 SA:A 0 SAS 10000 560000/1146880000 572325/1172123568 (not zeroed)
FAS3250-DR-KF-01> disk zero spares ###该命令将所有非清零 RAID 备用磁盘置零。
FAS3250-DR-KF-01> aggr status -s
Pool1 spare disks (empty)
Pool0 spare disks
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
——— —— ————- —- —- —- —– ————– ————–
Spare disks for block checksum
spare 0a.23.6 0a 23 6 SA:A 0 SAS 10000 560000/1146880000 572325/1172123568
spare 0a.23.23 0a 23 23 SA:A 0 SAS 10000 560000/1146880000 572325/1172123568 (zeroing, 13% done)
FAS3250-DR-KF-01> disk show -v 如果查看到新盘加入到控制器还是failed状态
0a.23.23 FAS3250-DR-KF-01(2015180633) FAILED 03G712MZ FAS3250-DR-KF-01(2015180633) Block
输入下面命令试一下不行的话联系厂商让其再发盘
priv set advanced
disk unfail -s 0a.23.23
tail -1 /etc/hosts
客户端IP地址 客户端主机名 客户端主机名
[root@centos ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.xx.xxx nbu-one nbu-one
10.1.xx.xxx nbu-two nbu-two
ll -h | grep NetBackup_8.1.2_CLIENTS2.tar.gz
-rw-r–r– 1 root root 3.4G 7月 27 18:29 NetBackup_8.1.2_CLIENTS2.tar.gz
tar -zxvf NetBackup_8.1.2_CLIENTS2.tar.gz
cd NetBackup_8.1.2_CLIENTS2
[root@centos NetBackup_8.1.2_CLIENTS2]# ls
Doc install LICENSE NBClients VSM_README
[root@centos NetBackup_8.1.2_CLIENTS2]# ./install
一路y 提示Master Server 名字 填写NBU master 主机名 回车 证书默认y
cat /usr/openv/netbackup/bp.conf
SERVER = NBU master hosts
CLIENT_NAME = client
CONNECT_OPTIONS = localhost 0 0 2
DB_SCRIPT_PATH = /usr/NBMySQLAgent/mysql_backscript.sh ##mysql备份代理客户端备份脚本指定的路径不写该参数会报错(5449) The script is not approved for executionNBU 5449错误状态码 (5449) The script is not approved for execution.NBU 5449错误状态码
ll -h | grep NBMySQLAgent_8.1.2.zip
unzip NBMySQLAgent_8.1.2
会得到三个目录
NBMySQLAgent_8.1.2_AMD64/ NBMySQLAgent_8.1.2_linuxR_x86/ NBMySQLAgent_8.1.2_linuxS_x86/
cd NBMySQLAgent_8.1.2_linuxR_x86/
cat README |grep NB
(Windows) NBMySQLAgent_8.1.2_AMD64/
(Linux RHEL) NBMySQLAgent_8.1.2_linuxR_x86/
(Linux SLES) NBMySQLAgent_8.1.2_linuxS_x86/
此环境是Redhat系列所以进到NBMySQLAgent_8.1.2_linuxR_x86/
ls
install LICENSE pkg.tar README
./install
一路y
cd /usr/NBMySQLAgent
ls
I18N_EN mysql_backscript.sh nbmysql nbmysql.conf nbmysql.log version.txt
mysql_backscript.sh ###mysql备份代理客户端备份脚本win环境下cmd后缀
cat mysql_backscript.sh
#!/bin/sh
#bcpyrght
#***************************************************************************
#* $Copyright: Copyright (c) 2017 Veritas Technologies LLC. All rights reserved VT25-0977-2658-84-51-3 $ *
#***************************************************************************
#ecpyrght
#NOTE:This is sample script can be changed according to the environment
RETURN_STATUS=0
echo "Execute $CMD_LINE"
CMD_LINE="/usr/NBMySQLAgent/nbmysql -o backup"
echo "Execute $CMD_LINE"
su - root -c "$CMD_LINE"
RETURN_STATUS=$?
exit $RETURN_STATUS
/usr/NBMySQLAgent/nbmysql.conf ###NBU mysql代理备份配置文件
cat nbmysql.conf | grep ^[A-Z]
DB_USER=root ###mysql数据库备份恢复权限用户
DB_PORT=3306 ###mysql数据库端口号
MYSQL_LIB_INSTALL_PATH=/usr/local/mysql/lib ###mysql安装的LIB路径
MASTER_SERVER_NAME=NBU master ###NBU master
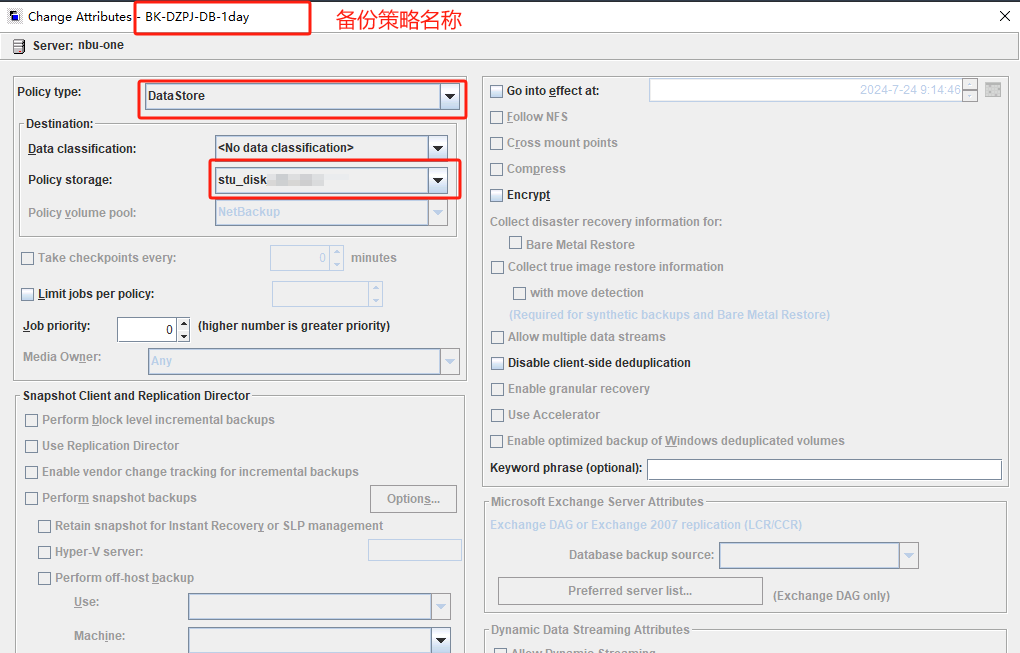
POLICY_NAME=BK-DZPJ-DB-1day ###备份策略名称
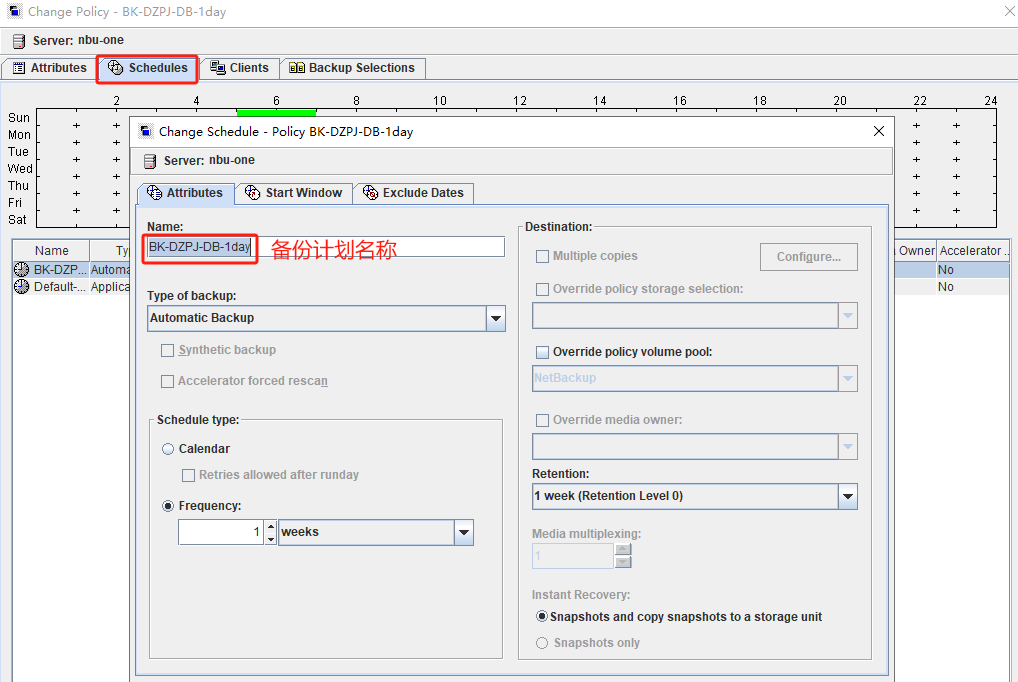
SCHEDULE_NAME=BK-DZPJ-DB-1day ###备份计划表名称
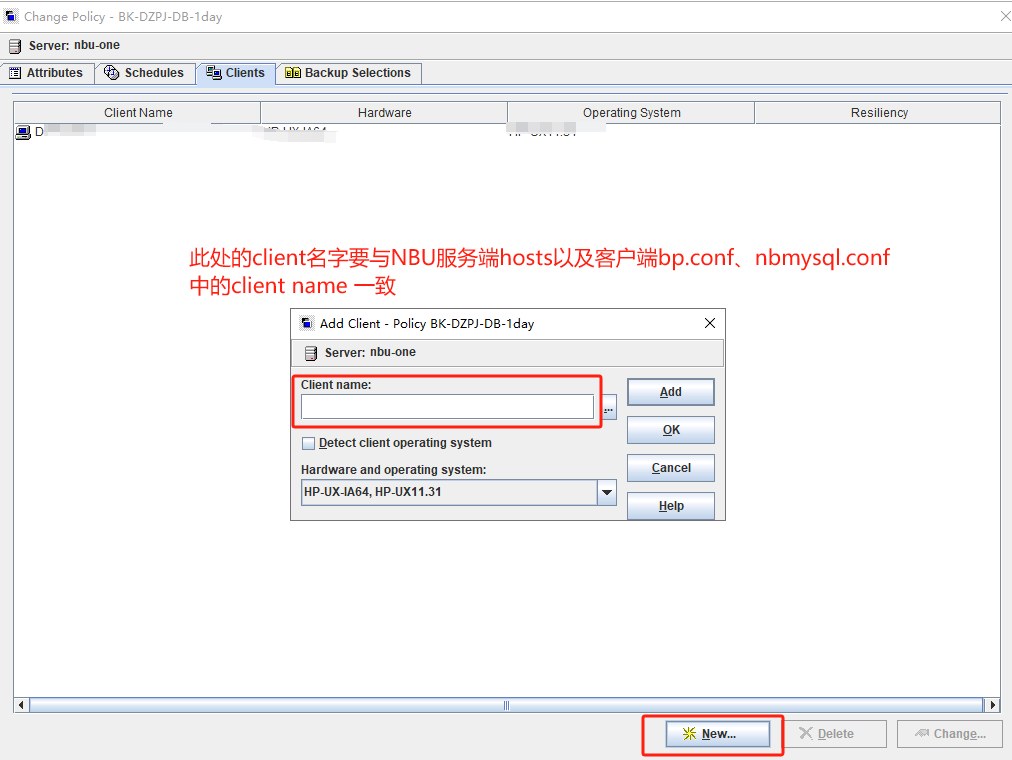
CLIENT_NAME=client ###客户端主机名称
SNAPSHOT_SIZE=500MB ###快照大小
NBMYSQL_LOG_LEVEL=4 ###日志等级 1 – ERR, 2 – WARN, 3 – INFO, 4 – DEBUG
DB_SCRIPT_PATH =/usr/NBMySQLAgent/mysql_backscript.sh ###备份脚本
更改配置文件后重启服务
service netbackup stop
service netbackup start

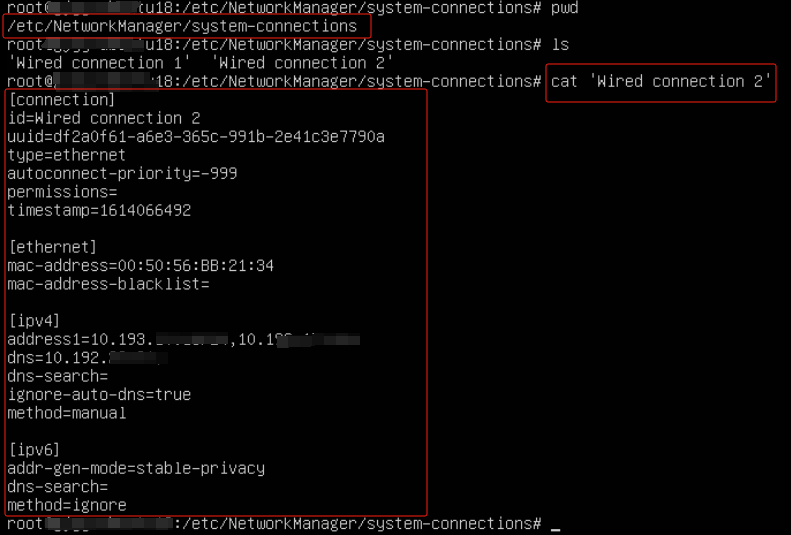
vi /etc/NetworkManager/system-connections/ens192.nmconnection
[connection]
id=ens192
type=ethernet
autoconnect-priority=-999
interface-name=ens192
[ethernet]
[ipv4]
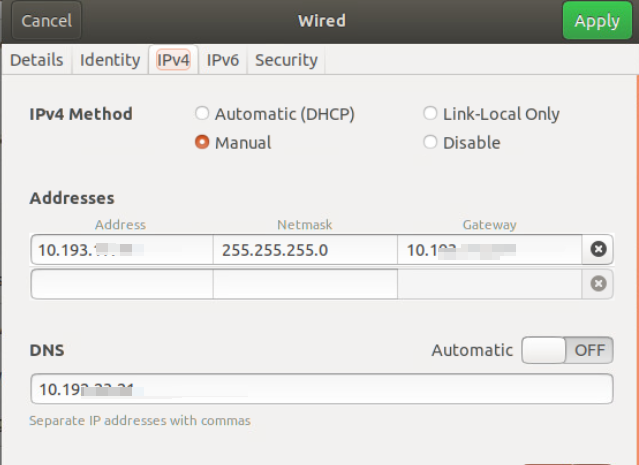
address=10.193.xx.xx/24,10.193.xx.xxx #IP地址/掩码,网关
dns=10.19x.xx.xx;10.19x.xx.xx #DNS
route1=IP地址或者IP段,网关
route2=IP地址或者IP段,网关
method=manual #将method=auto改为method=manual配置静态ip
[ipv6]
addr-gen-mode=eui64
method=auto
[proxy]
nmcli重启网卡
只加载单个网口配置文件 nmcli c load ens192.nmconnection
加载全部connection文件 nmcli c reload
启动指定网口 nmcli c up ens192
关闭指定网口 nmcli c down ens192
查看IP详细信息 nmcli dev show
查看路由条目
route -n
ip route show
使用 bptestbpcd 和 bptestnetconn 命令检查到所有版本 NetBackup 主机的端口连接。
bptestbpcd 命令仅位于 NetBackup 服务器上。
bptestnetconn 命令位于 NetBackup 服务器和客户端上。
服务端:
nbu-one:/usr/openv/netbackup/bin/admincmd # bptestbpcd -host client -verbose
nbu-one:/usr/openv/netbackup/bin/admincmd # bptestnetconn client
客户端:
/usr/openv/netbackup/bin/bptestnetconn nbuserver
检查解析是否正常
客户端:
/usr/openv/netbackup/bin/bpclntcmd -hn nbuserver
/usr/openv/netbackup/bin/bpclntcmd -hn client
/usr/openv/netbackup/bin/bpclntcmd -pn
服务端:
nbu-one:/usr/openv/netbackup/bin/admincmd # bpclntcmd -hn client
可以使用 vxlogview 查看 NetBackup 日志文件以及 PBX 日志文件。
要使用 vxlogview 命令查看 PBX 日志,请执行以下操作:
确保您是授权用户。 对于 Unix 和 Linux,您必须具有 root 权限。 对于 Windows,您必须具有管理员权限。
要指定 PBX 产品 ID,请在 vxlogview 命令行上输入 -p 50936 作为参数。
客户端:
日志排查
vi /usr/NBMySQLAgent/nbmysql.log
/usr/openv/netbackup/bin/./vxlogview -K client >> /root/nbu.logs -K显示主机名的所有日志
/usr/openv/netbackup/bin/./vxlogview -o 200 检查 nbftclnt 统一日志记录文件 (OID 200) 以了解错误信息
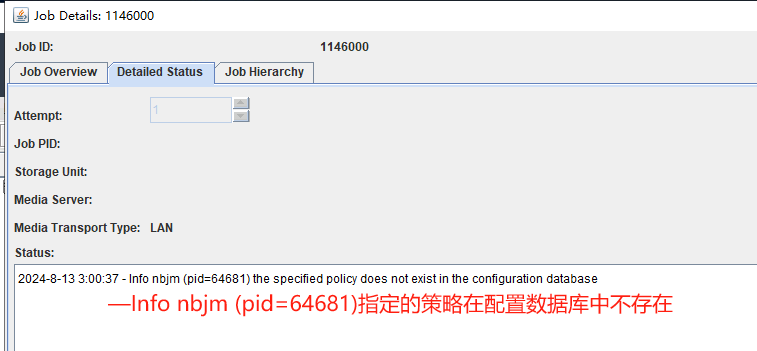
2024年07月27日 18:48:19.487 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
2024年07月27日 19:34:32.363 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
2024年07月27日 20:01:51.722 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
2024年07月27日 20:01:53.780 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
2024年07月29日 15:46:08.029 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
2024年07月30日 10:20:36.238 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
2024年07月30日 10:34:23.901 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
2024年07月30日 14:46:39.485 [nbftclnt] exiting, not configured as a SAN CLIENT – bp.conf missing SANCLIENT=1
V-1-1-13 NOTE: There were 1 corrupted log records.
nbftclnt日志文件路径 /usr/openv/logs/nbftclnt/log文件 客户端上的 nbftclnt 进程必须处于运行状态,您才能通过光纤通道启动 SAN 客户端备份或还原操作
bp.conf 配置文件配置SANCLIENT=1重启服务后解决 进程处于运行状态了
重新启动所有 NetBackup 服务。
service netbackup stop
service netbackup start
/usr/openv/netbackup/bin/./vxlogview -o 103 可使用 vxlogview 命令查看 PBX 和其他统一日志。PBX 的创建者 ID 为 103
fidsk /dev/sda
进行 删除旧根分区操作后 创建新根分区时候会提示如下图选择N即可 剩下操作跟扩容centosLVM 系统盘一样操作 扩容centosLVM 系统盘链接:centos系统扩容lvm系统盘
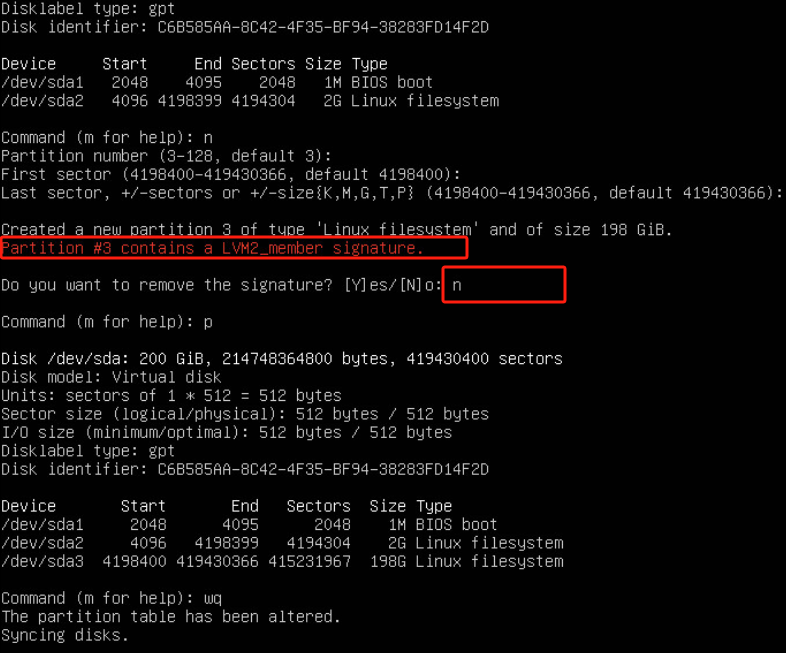
如果删除系统就崩了 选择N 依然使用旧的LVM签名
此环境是Linux 备份mysql数据库
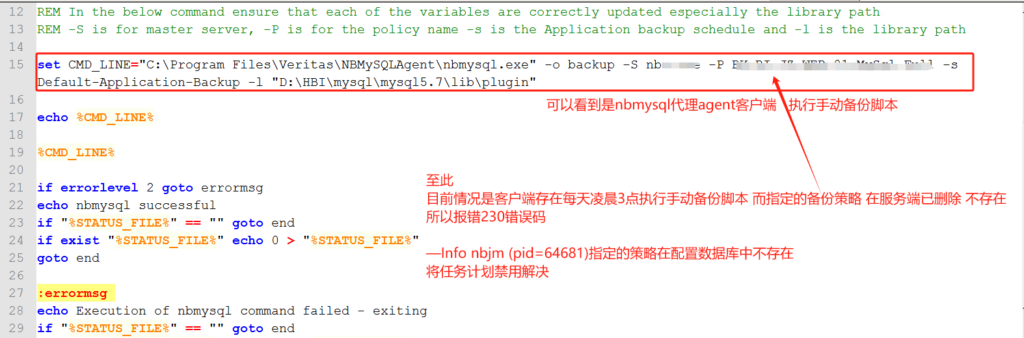
Linux环境下备份mysql 除了安装Linux环境下的NBU 客户端(NetBackup_8.1.2_CLIENTS2.tar.gz)还要安装对应系统的mysql代理客户端NBMySQLAgent_8.1.2.zip解压下的
((Linux RHEL) NBMySQLAgent_8.1.2_linuxR_x86)
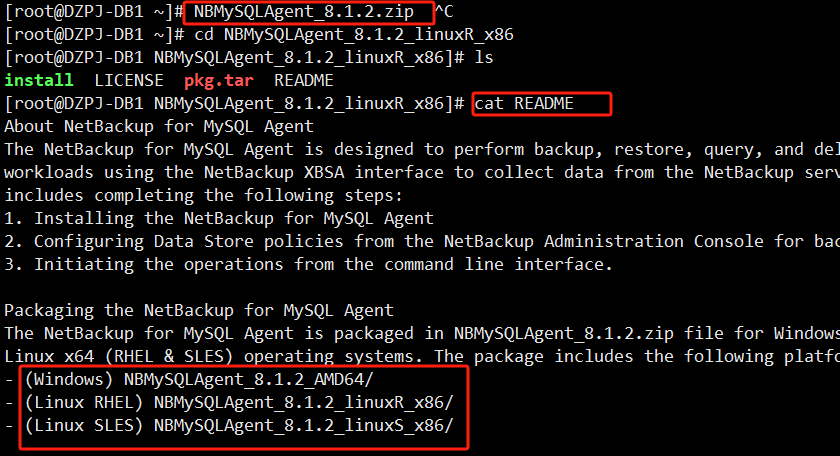
2024-7-27 21:16:33 – Info bphdb (pid=26092)脚本已被批准运行,并保存在本地。
2024-7-27 21:16:33 -连接中
2024-7-27 21:16:33 -连接;连接时间:0:00:00
2024-7-27 21:16:34 – Error bpbrm (pid=273340) from client xxxxx: ERR – bphdb exit status = 29:执行命令失败
2024-7-27 21:16:34 – Info bphdb (pid = 26092)。status: 29:执行命令失败
2024-7-27 21:16:34 -结束写作
试图执行命令失败(29)
此报错 允许脚本运行了 但是执行命令失败报错
咱们手动执行备份 /usr/NBMySQLAgent/nbmysql -o backup

进入/usr/NBMySQLAgent/nbmysql.log 日志看错误
Failed to load the MySQL library: /usr/lib64/mysql/lib/libmysqlclient.so: cannot open shared object file: No such file or directory
find / -name libmysqlclient.so 查找下路径
在/usr/NBMySQLAgent/nbmysql.conf 配置文件修改配置数据库LIB的正确路径
MYSQL_LIB_INSTALL_PATH=/usr/local/mysql/lib
更改配置文件后重启服务
service netbackup stop
service netbackup start
手动执行备份 /usr/NBMySQLAgent/nbmysql -o backup

原因是/usr/NBMySQLAgent/nbmysql.conf 配置文件没有写此参数 SNAPSHOT_SIZE=500MB
更改配置文件后重启服务
service netbackup stop
service netbackup start
手动执行备份 /usr/NBMySQLAgent/nbmysql -o backup

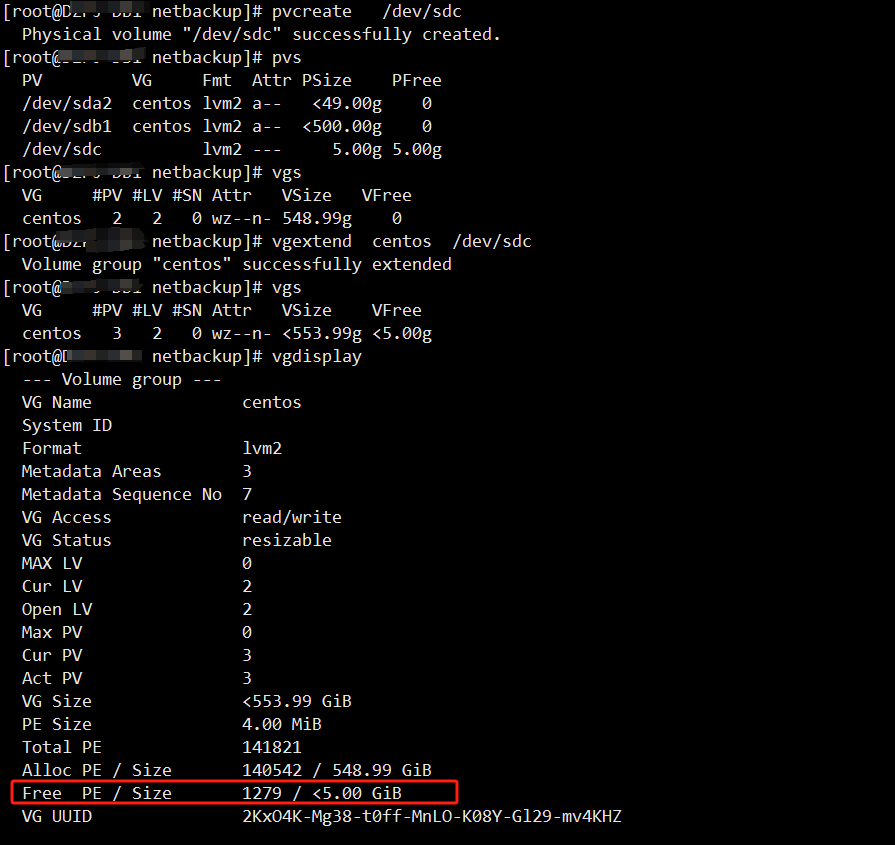
原因是free PE 大小为0 需要添加硬盘 切记需要新加一块硬盘 不能再源硬盘上扩容否则free空间不增加

报错解释:
NBU 指的是 NetBackup 备份软件。报错代码 58 通常表示 NetBackup 客户端无法连接到备份服务器。这可能是由于网络问题、客户端配置错误、服务未运行或认证问题等引起的。
解决方法:
(5449) The script is not approved for execution. (5449)脚本未被批准执行。

24-7-27 18:49:35 – Info bphdb (pid=16401)备份启动
24-7-27 18:49:35 -错误bpbrm (pid=51744) from client xxxxx: ERR -脚本未被批准运行。该脚本需要添加到客户机上的授权位置,然后才能运行。
2024-7-27 18:49:35 – Error bpbrm (pid=51744) from client xxxxx: ERR – bphdb exit status = 5449:脚本未被批准执行。
2024-7-27 18:49:35 – Info bphdb (pid = 16401)。status: 5449:不允许执行。
2024-7-27 18:49:35 -连接;连接时间:0:00:00
2024-7-27 18:49:35 -结束写作
脚本未被批准执行。(5449)

DB_SCRIPT_PATH = /usr/NBMySQLAgent/mysql_backscript.sh
更改配置文件后重启服务
service netbackup stop
service netbackup start
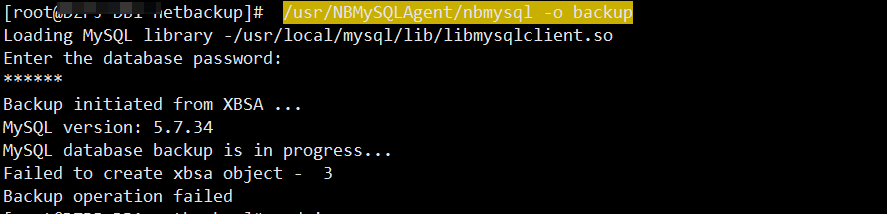
client host name could not be found 找不到客户端主机名
原因通常是因为NBU服务端/etc/hosts文件没有写入客户端的主机名或者错误导致
NBU服务端写入/etc/hosts链接: NBU 备份一体机5240进入shell界面编辑hosts文件
ssh 连接到NBU后输入 Support
nbu-one.Main_Menu> Support
Entering NetBackup support view…
输入Maintenance 提示输入密码
nbu-one.Support> Maintenance
maintenance’s password: 输入密码 通常是登录控制台的密码
maintenance-!> /opt/Symantec/sdcssagent/IPS/sisipsoverride.sh
#####执行/opt/Symantec/sdcssagent/IPS/sisipsoverride.sh
Symantec Data Center Security Server Policy Override
To override the policy and disable protection, enter your login password.
Password: 再次输入密码
Choose the type of override that you wish to perform:
Choose the amount of time after which to automatically re-enable:
Enter a comment. Press Enter to continue.
确定键后等待进度条走完即可
Please wait while the policy is being overridden.
…………………..
The policy was successfully overridden.
maintenance-!> elevate 输入elevate进入shell界面
nbu-one:/home/maintenance # vi /etc/hosts
127.0.0.1 localhost
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
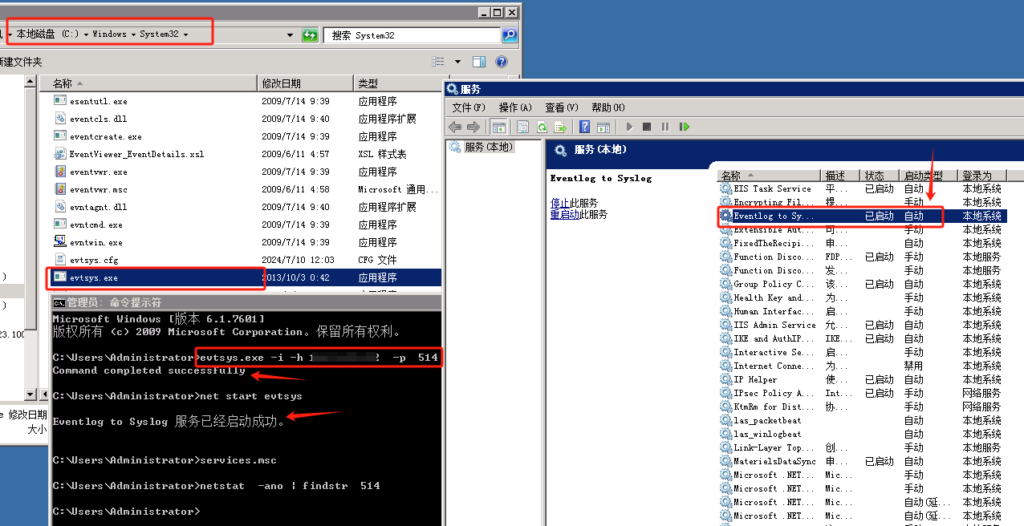
evtsys工具下载
默认 UDP协议的514端口
默认日志级别为0 所有级别
evtsys.exe -i -h 192.168.10.100 -p 514 安装服务#####
net start evtsys 启动服务#####
i是安装成Window服务;
h是syslog服务器地址;
p是syslog服务器的接收端口。
将压缩包里面的exe文件复制到C:\Windows\System32\目录下 打开cmd安装服务、启动服务。
node1,node2请替换成您实际节点名称
node-01.7z node-02.7z 请替换成您命名的名称
::> system node autosupport invoke -node node1 -type all -uri file://localhost/mroot/etc/log/node-01.7z
::> system node autosupport invoke -node node2 -type all -uri file://localhost/mroot/etc/log/node-02.7z
可以使用 “system node autosupport history show” 查看日志是否收集完成 100%收集完成

大约等待5分钟左右,浏览器导航到以下目录,导出日志文件node-01/02.7z
https://IP/spi/node_name/etc/log
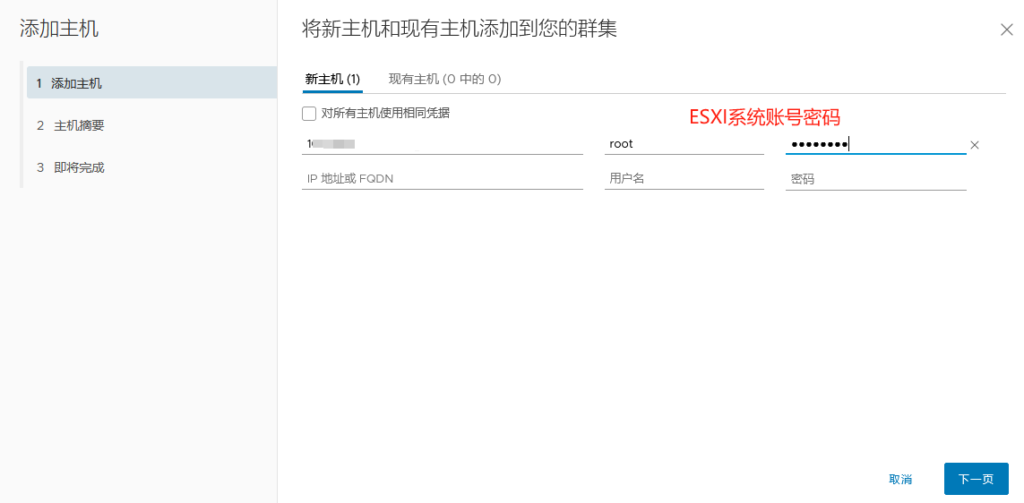
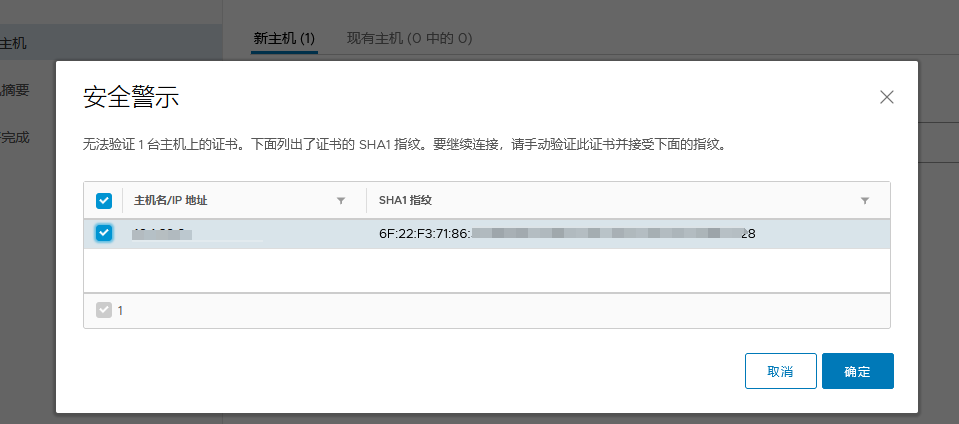
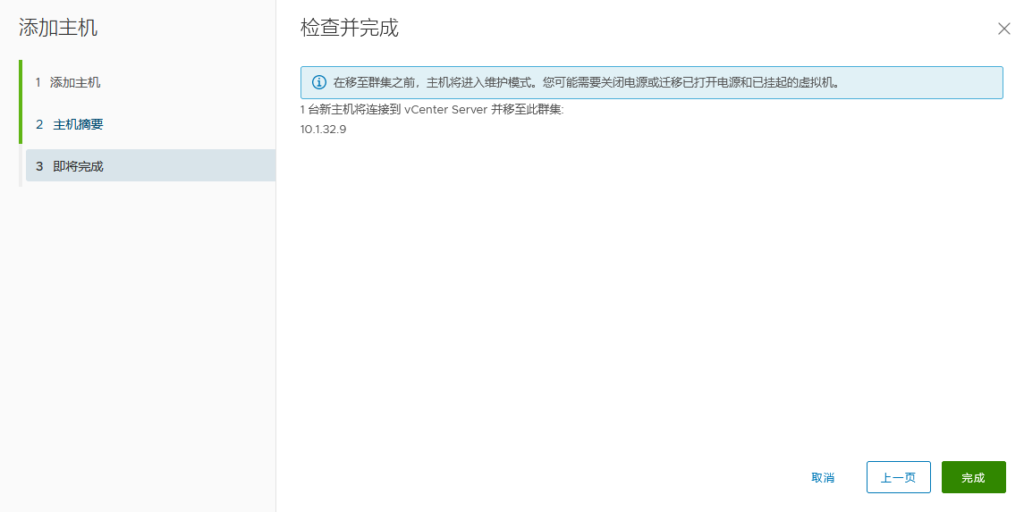
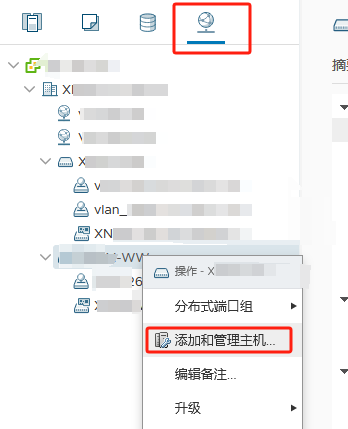
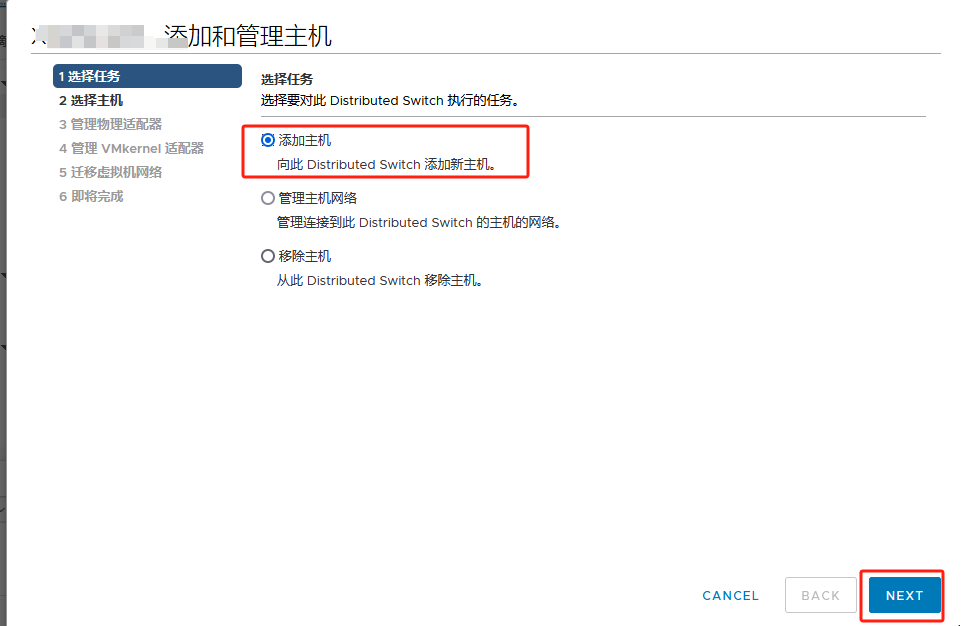
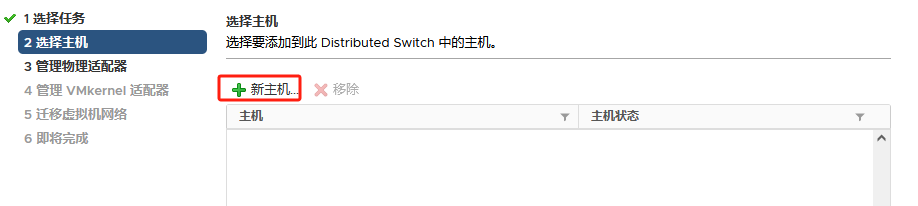
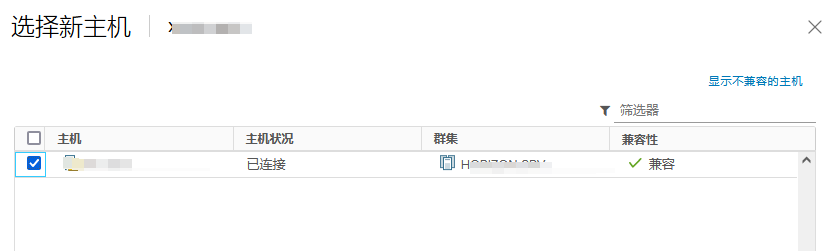
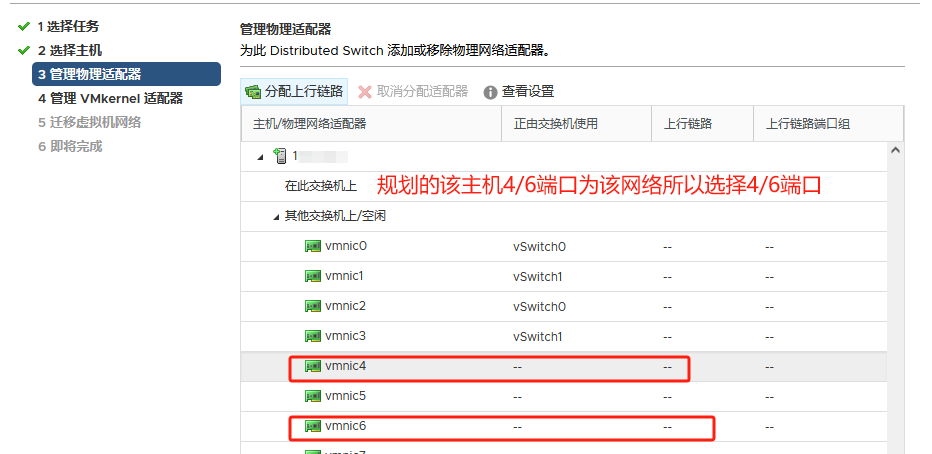
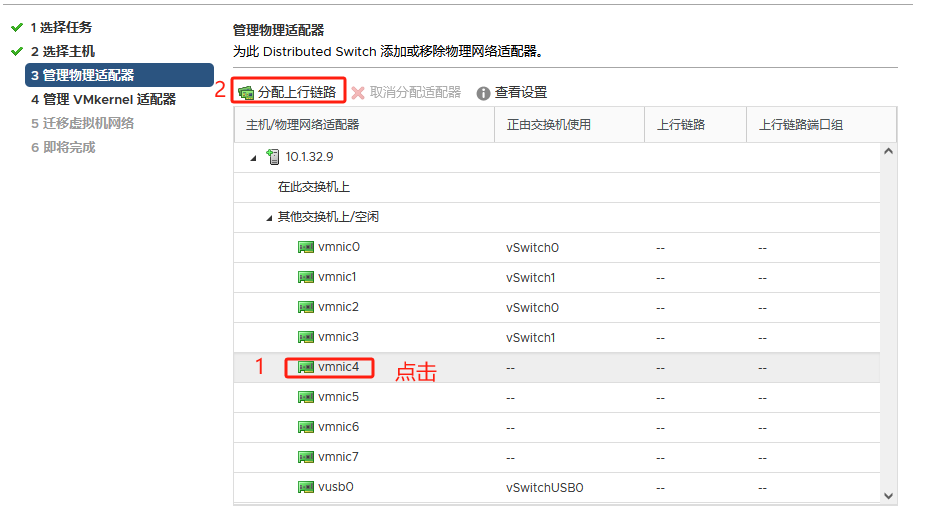
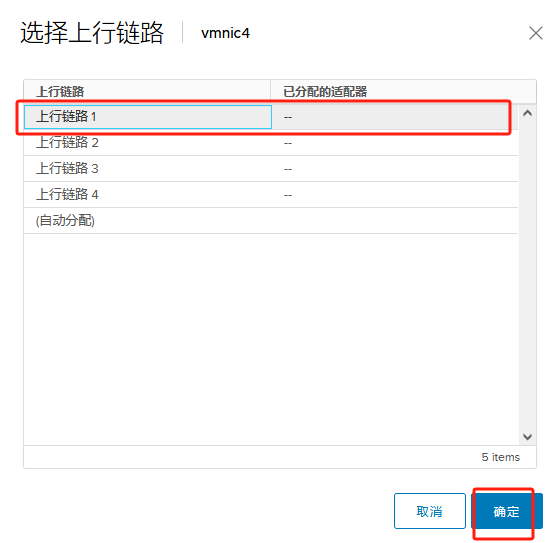
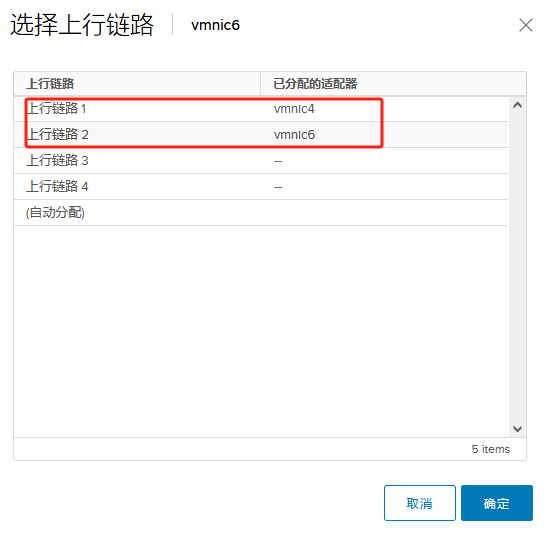
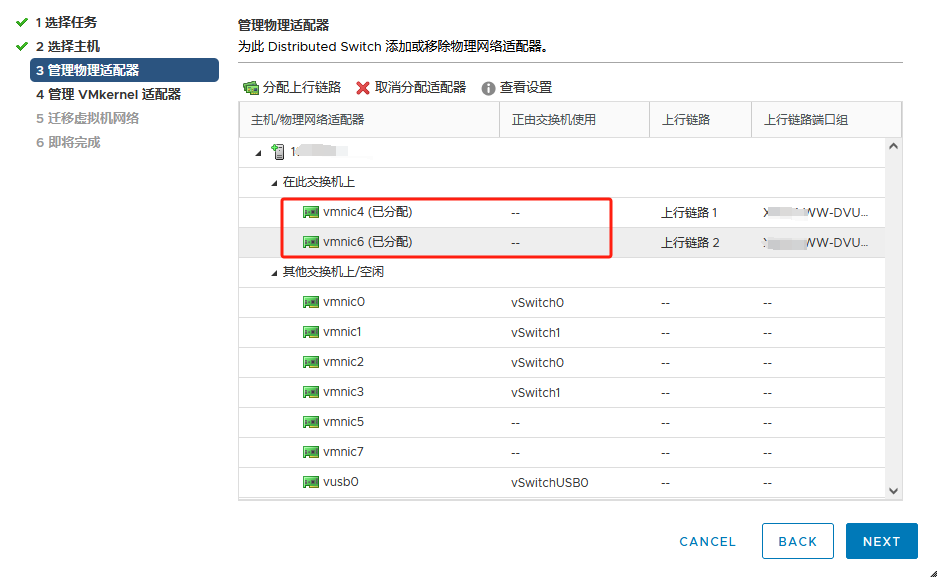
提前将ESXI主机和已存在主机群集以及对应的分布式交换机 物理链路打通
比如Management network、vm network、vMotion、vcenterHA 以及虚拟机业务分布式交换机打通
通俗的讲:
需要实现各个ESXI主机之间互通 以备主机正常使用和虚拟机正常迁移
还要保障主机上的虚拟机可以在任其集群中的任意一台主机上正常运行
由此 需要将 新的ESXI主机将网线以及光纤线连接到对应的已存在群集的物理交换机来实现 网络打通
以此在vSphere平台上将新的ESXI主机加入主机群集以及分布式交换机
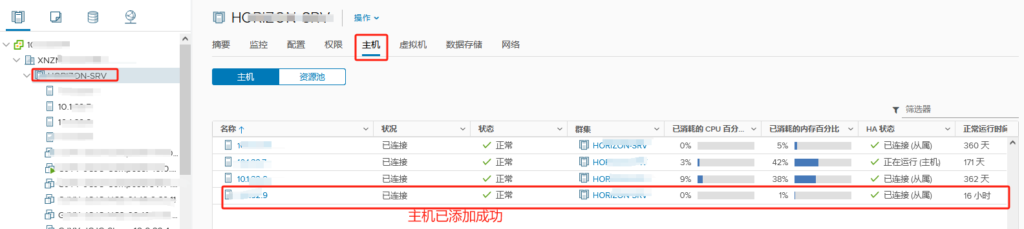
在CentOS中,要查看占用空间最大的文件,可以使用du命令结合sort进行排序
以下是一个基本的命令示例,用于查找当前目录下占用空间最大的文件:
du -h –max-depth=1 / | sort -hr | head -n 10
解释:
du: 磁盘使用情况命令。
-h: 以人类可读的格式显示(例如,KB、MB、GB)。
–max-depth=1: 限制显示目录的深度。
/: 你想要检查的目录路径。
sort -hr: 按人类可读的数字大小逆序排序。
head -n 10: 只显示最大的10个文件。
注意:这些命令可能需要一定时间来运行,因为它们会遍历整个文件系统来统计文件大小。
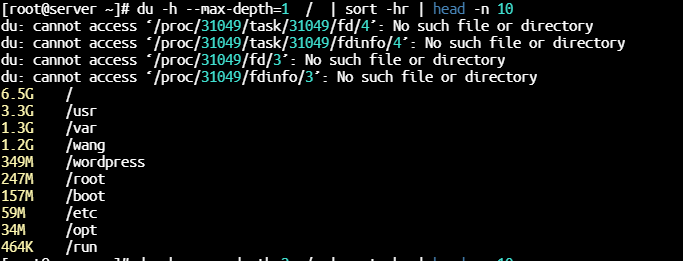
“应用程序无法正常启动0xc0000142″。这个错误通常是由于应用程序的某些组件丢失或损坏,或者系统的某些配置不正确导致的。
参考链接:https://baijiahao.baidu.com/s?id=1784164710765921883&wfr=spider&for=pc
这里我是内存以及磁盘资源不足导致的
一、原因分析
当应用程序的组件丢失或损坏时,可能会导致应用程序无法正常启动。这可能是由于多种原因引起的,例如:
除了应用程序本身的问题外,系统配置也可能会导致应用程序无法正常启动。例如:
二、解决方法
首先,尝试重新安装或升级应用程序,以确保所有的组件都能够正确地复制和注册。如果问题依然存在,可以尝试在应用程序的官方网站上查找是否有相关的更新或修复程序可供下载。如果问题依然无法解决,可能需要联系应用程序的技术支持团队以获取更进一步的帮助。
在确认应用程序的组件没有问题后,需要检查系统的配置是否正确。可以尝试以下方法:
有时候,应用程序可能与当前的操作系统不兼容,导致无法正常启动。在这种情况下,可以尝试以下方法:
总之,当遇到”应用程序无法正常启动0xc0000142″错误时,需要仔细分析错误的原因并采取相应的解决方法。可以通过检查应用程序的组件、系统的配置和应用程序与操作系统的兼容性等方面来解决这个问题。如果问题依然无法解决,可以寻求相关的技术支持帮助。
背景:该虚拟机所运行的宿主机故障重启 所以该虚拟机为非正常重启 所以文件系统因为此原因被挂载为只读模式是为了保护数据不受损坏而自动将文件系统挂载为只读。


journalctl看到文件系统只读 此时认为内存使用率高是因为文件系统只读原因(后来发现内存高是因为rsyslog服务问题重启即可与文件系统只读无关)
journalctl -p err -b 看到只读文件系统 此链接为journalctl命令链接 centos7 主机开机自动进入救援模式

让其权限读写 提示写保护 不可操作
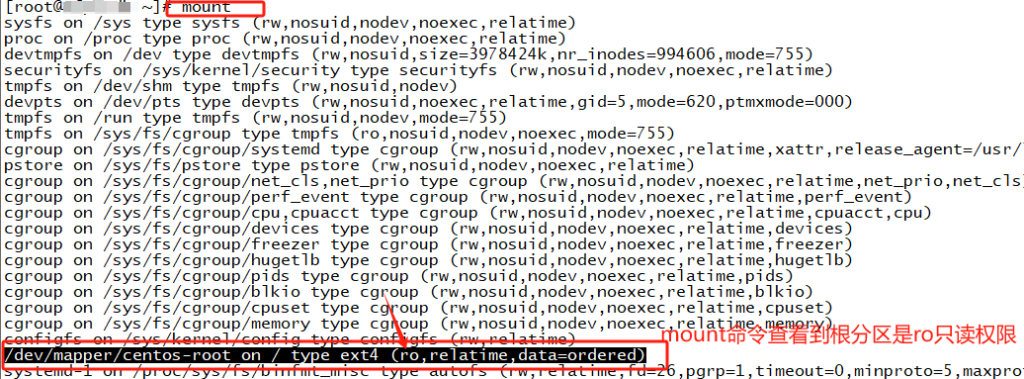
[root@~]# mount -o remount,rw /
mount: cannot remount /dev/mapper/centos-root read-write, is write-protected
Mount:不能重新挂载/dev/mapper/centos-root,读写,写保护
-o 指定挂载文件系统时选项
remount 重新挂载已挂载的文件系统
rw 读写权限
/ 根分区
fsck修复文件系统
https://blog.csdn.net/m0_74282605/article/details/132456869
参考链接:https://www.xitongcheng.com/jiaocheng/win7_article_39967.html
此链接写了四种解决方法 me用第三种方法解决的


regsvr32 C:\Windows\System32\msxml3.dll 回车后再次打开成功
syslog 一般是默认安装
syslog 服务用于记录系统和应用程序的日志信息 默认情况下,syslog配置为接收来自本地系统的日志信息,并可以通过配置文件将其转发到远程syslog服务器。
要配置Linux系统以外发syslog到远程服务器,步骤操作:
1、编辑/etc/rsyslog.conf或者/etc/syslog.conf文件(取决于你的Linux发行版)。
2、注释掉或删除所有以*.info;mail.none;authpriv.none;cron.none开头的行,这些是本地系统通常配置的用于忽略某些类型日志的规则。
3、最后一行添加配置,指定远程syslog服务器。例如:
*.*@@ip:port
其中*.*代表所有的日志级别,@@表示使用TCP协议,@表示使用UDP协议 ip是远程syslog服务器的主机名或IP地址 port是syslog端口(默认514端口)。
保存配置文件并重启rsyslog服务:systemctl restart rsyslog
重启rsyslog服务后,本地系统的日志将会被发送到指定的远程syslog服务器。
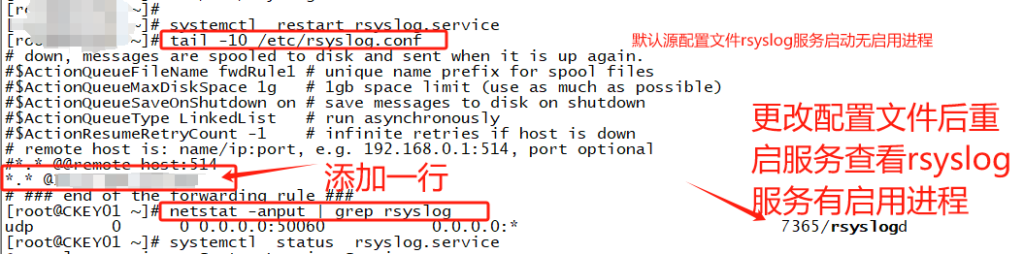
logger 命令远程测试syslog
https://www.11meigui.com/dev/linux/logger
https://www.cnblogs.com/xingmuxin/p/8656498.html
https://blog.csdn.net/tanga842428/article/details/79407652
经过查询这是因为windows上的簇大小(分配单元)决定的:
在进行扩展磁盘分区即“扩展卷”操作时,需要注意微软对分区的簇大小及个数的限制。
win2000之后的系统在NTFS文件系统中分区大小为16TB以下时,簇大小默认为4KB,而16TB~32TB时默认簇大小为8KB。
分配单元设置得过大,会造成大量的磁盘空间未被利用,浪费了磁盘空间;如果设置得过小,则会导致硬盘上簇的数量过大,硬盘会浪费大量的时间来寻道,性能降低。所以其取值应该兼顾空间和性能的需要,一般用默认值就行了
如果扩容之前的分区大小与扩容后的大小不在一个簇大小下。
系统会提示:“无法扩展该卷,因为群集的数量将超过文件系统支持的最大群集数量。”因此扩展卷时,该卷只能扩展到当前簇大小所支持的最大值。
报错截图:

对应簇大小:
fsutil fsinfo ntfsinfo E:\
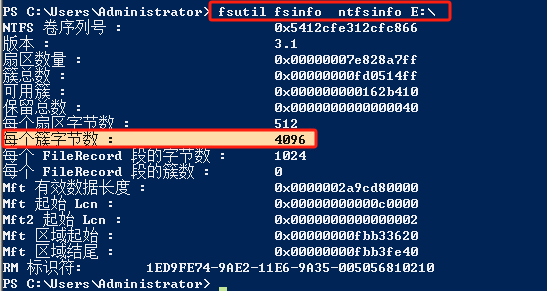
4096也就是4KB 最大支持到16T容量
此次扩容是要大于16T 所以报错原因已清晰
可以通过以下两种方式进行处理:
1、若这类大规格容量场景的话,建议不在原的分区上进行扩容,而是对扩容的磁盘空间进行新建分区的操作,这样系统会对新建分区适配相应的簇大小。
2、若必须将扩容空间与原空间合并为一个分区的话,则需要将该原有分区中的数据全部备份到其他磁盘,再将该分区删除与新增容量统一进行格式化,此方式较操作复杂,如果不是必须,建议使用新建分区的方式来使用新增容量。
零信任VPN和传统SSLVPN的区别:
传统SSL VPN是通过对外发布端口的形式将业务发布在互联网上,在进行数据连接的时候,用户访问应用,通过VPN的鉴权后即可建立一个VPN的隧道,这个连接会涉及两个问题:
1、首先是在连接过程中只会做一次鉴权,除非掉线否则不进行二次验证。
2、是在VPN隧道建立前,用户就已经访问到了业务端口,一旦VPN被攻破,这个“用户”就会获得所有的业务权限,所以传统VPN在架构上就不够安全。
下面我们在看看零信任是如何工作的:
1、首先通过代理网关+控制中心的模式将业务完全收缩进内网,并且所有访问默认都是不可信任的,所有用户要访问业务都要通过零信任本身的验证,验证通过后控制中心下发相关权限,由代理网关进行代理访问业务。用户不直接和业务接触,在架构设计上就比VPN安全。
2、其次零信任采取SPA单包授权的模式,对用户的连接实时的进行动态的验证,在连接过程中实时发现用户侧的连接是否安全,网络状态是否变化等。
3、零信任采用灰度权限,当用户的网络情况发生变化如从公司网络环境变成手机热点或者家庭wifl,零信任可以开启二次验证,使用灰度权限的功能既确保了用户接入业务的安全,也确保了用户的接入体验,最后零信任还可以联动EDR等其它设备对终端进行验证等。
整体来说零信任在身份认证、终端安全认证、连接安全、用户权限、数据安全和行为安全方面都有VPN所不具备的优势。
1、用户使用体验
VPN需要在用户设备上安装专门的VPN客户端软件,并进行配置。这使得使用VPN的过程相对繁琐;而且通过建立安全隧道来实现远程连接,因此可能会导致连接速度变慢。最后,VPN的连接方式比较固定,一般需要预先配置一组网络设置,灵活性相对较低。相比之下,零信任服务在用户体验方面相对更加便捷和灵活。它不需要复杂的客户端软件,支持直接访问云应用和互联网资源,而且具备自动化的访问权限管理和灵活的安全策略适配,为用户提供了更好的工作体验和个性化定制选项。
2、接入体验
VPN通常通过提供远程用户与企业网络之间的安全连接来实现网络资源访问控制。用户在通过VPN连接后,被授予了访问企业网络中特定资源的权限。然而,这种授权往往是基于用户的身份验证,一旦用户通过身份验证,他们将获得相对广泛的网络访问权限,包括访问敏感数据或者关键系统的权限。这种静态且广泛的访问权限可能会增加潜在的安全风险,因为一旦用户的凭证被泄露或被滥用,黑客或恶意用户可能会获取到敏感信息或者对关键系统进行未经授权的访问。
而零信任服务在网络资源访问控制和权限认证方面具有明显的优势。它通过动态的权限分配、细粒度的访问控制和加强的身份验证机制,为企业提供了更为安全和可控的访问控制方案。
3、安全防护
VPN使用加密隧道来保护数据的传输,通过对数据包进行加密和解密来确保数据的机密性。然而,VPN通常采用预共享密钥或证书等静态的身份验证方式,容易受到密码破解和中间人攻击的威胁。相比之下,零信任服务采用更强大的动态身份验证机制,如多因素身份验证和单一登录(SSO),以及细粒度的访问控制策略,从而提供了更高级别的数据保护。
认证方式:
零信任:持续校验用户、设备、授权。SSL VPN:用户访问应用时,通过VPN鉴权,账号登录成功后,即会建立SSL VPN隧道,VPN下发IP地址、路由到终端。之后VPN会维持该隧道,并基于IP和端口进行访问权限控制。除非掉线重新登陆,否则不会有第二次校验。
安全性和访问控制:
零信任:不仅仅依赖于网络边界上的信任,而是将信任放在用户身份和设备状态的实时验证上。这意味着在访问企业资源时,每个用户和设备都需要经过严格的身份验证和授权,不论其所处的网络环境如何。SSL VPN:可能存在安全问题,例如内部人员所为导致的安全问题或VPN本身的问题。
扩展性和用户体验:
零信任:可扩展性更好,因为其基于策略和验证的安全模型可以灵活地应对各种网络环境和用户需求。SSL VPN:可能在某些情况下对用户体验产生影响,例如掉线重新登陆等情况。
综上所述,零信任和传统的SSL VPN在认证方式、安全性和访问控制、扩展性和用户体验等方面存在显著的区别。零信任通过持续校验用户、设备、授权来提高安全性,而SSL VPN则可能存在安全问题。同时,零信任还具有更好的可扩展性和用户体验。
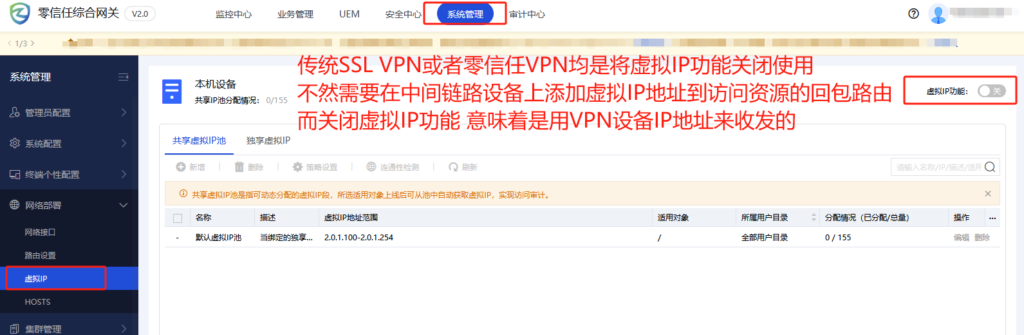
零信任VPN关闭虚拟IP截图